

Графовые рекомендации групп в Одноклассниках
Графовые рекомендательные системы показывают state of the art результаты, но про них редко пишут и еще реже используют в продакшене. В этой статье мы расскажем про опыт Одноклассников в применении графового подхода для задачи рекомендации групп, разберем причем тут нейросети и что делать, если не все рекомендации одинаково полезны для пользователей и портала.
Меня зовут Андрей, и я занимаюсь разработкой рекомендательных систем в команде групп. В Одноклассниках много сервисов используют рекомендательные системы, построенные на разных подходах и экосистема групп здесь не исключение. Прежде чем углубляться в детали реализации нашего подхода к рекомендациям, стоит рассказать о том, что представляют собой группы на портале и в чем их особенность как объектов рекомендаций.
Что рекомендуем?
Группы в Одноклассниках — одна из важнейших частей портала, которые помогают находить нашим пользователям сообщества единомышленников, а брендам и малому бизнесу — своих клиентов. На сегодняшний день у нас зарегистрировано больше 11 миллионов групп очень разных по содержанию и назначению. Мы стараемся каждому нашему пользователю подобрать что-то по вкусу, впрочем, о вкусах речь пойдет дальше.
Мы рекомендуем группы как на отдельной "витрине групп", так и в ленте пользователя.
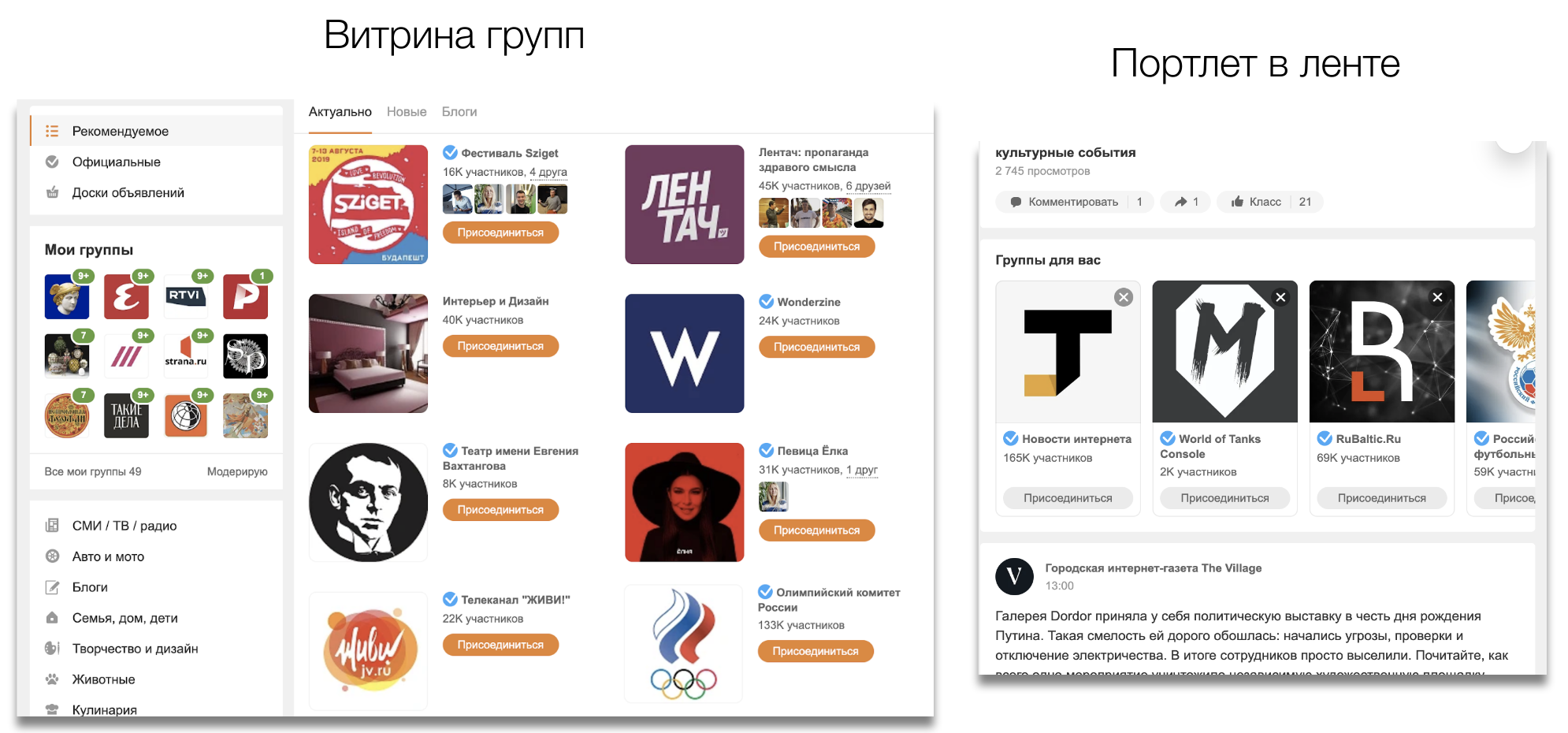
А еще есть внутренний пользователь — сервис "Рекомендации", который использует групповые рекомендации для отбора постов-кандидатов. Каждый день мы показываем пользователям 2 миллиарда рекомендованных им групп.
Группы как объект рекомендаций, имеют свой уникальный набор сложностей по сравнению с классическими примерами вроде товаров в онлайн-магазинах:
- Обратная связь. Представьте себе ситуацию, что в музыкальном сервисе пользователям из всего огромного каталога рекомендуются только 10 треков, но пользователи довольны и успешно слушают только их. Нас бы это скорее всего устроило, но такой сценарий неприемлем для групп потому, что рекомендации — мощный источник трафика, без которого авторы контента потеряют мотивацию развивать свои сообщества.
- Группы могут сильно изменяться со временем, так как выбор тематики группы и их контентного наполнения определяется ее администрацией.
- У групп практически отсутствует достоверный набор статичных характеристик для использования их в моделях машинного обучения.
- Географическая локальность групп — еще одна очень интересная особенность. К примеру, даже если пользователя из Таганрога очень интересует разведение русской псовой борзой, то предложенная тематическая группа из Орла вряд ли будет ему релевантна.
- Боты. Накрутка аудитории все еще актуальная история. Цифра в графе “участники” для некоторых значит многое, поэтому администраторы покупают себе в группы ботов, которые неизбежно вносят шум в алгоритмы, ломая органический поток рекомендаций.
Все эти особенности требуют аккуратной подготовки данных для обучения, а также механизма пост-фильтрации рекомендаций.
Выбор алгоритма для рекомендательной системы
В отличии от других областей машинного обучения в задачах рекомендаций нет универсального набора моделей. C одной стороны, глубокое обучение все чаще используется для построения рекомендательных систем, в большом количестве публикуются соответствующие статьи, а Google регулярно рассказывает о том, как они используют [1,2,3,4] нейронные сети для рекомендаций в YouTube.
С другой стороны, эти успехи не так очевидны даже на фоне классических алгоритмов. Так в работе "Are we really making much progress? A worrying analysis of recent neural recommendation approaches", которая получила приз за лучшую статью на последней RecSys, авторы приходят к таким выводам:
- Только для 39% статей им удалось воспроизвести заявленные результаты.
- Настроенные под конкретные датасеты классические подходы ItemKNN, UserKNN, Random Walks, SVD и даже просто Top-N, почти во всех случаях работали лучше их нейронных архитектур.
Помимо этого, другая группа авторов на том же RecSys показала, что графовый алгоритм на Random Walks с доработанным механизмом формирования графа и персонализированной глубиной случайного блуждания с заметным отрывом превосходит все существующие подходы. Помимо превосходных результатов в качестве рекомендаций графовый подход ультра-эффективен в плане производительности.
Несмотря на стабильно хорошие результаты графовых подходов для рекомендаций в научных статьях, зрелых открытых библиотек для них до сих пор не появилось.
Открытые реализации графовых рекоммендеров:
- Здесь выложен код нескольких алгоритмов, в том числе и двух графовых. Написано на Python с комментариями и инструкциями по запуску.
- Продвинутая релизация графового рекоммендера на С, без особых пояснений.
В своем решении мы ставили целью совершенствование подхода Random Walks для задачи рекомендаций групп. В результате этой работы получилось найти, как общеприменимые подходы к улучшению оригинального подхода, так и эвристики, позволяющие решать конкретно нашу задачу.
Наша реализация Random Walks
Вершинами графа для случайного блуждания являются объекты рекомендаций (в нашем случае группы), а веса рёбер между этими вершинами — оценка похожести групп на основе пользовательской обратной связи. В самом простом случае такую оценку можно получить на основе пересечений аудиторий групп, посчитав косинусное расстояние между векторами групповых членств пользователей. Для каждой вершины-группы мы оставляем только top-k похожих на нее групп в исходящих ребрах и нормируем их значения.
Помимо самого графа, который мы держим в памяти, необходимо иметь начальные вершины, с которых начинается его обход. Их набор и добавляет персонализацию в этот подход (сам граф один на всех), поскольку зависит от интересов пользователей, которые мы называем “групповыми вкусами”. В самом простом приближении ими могут быть группы, в которых состоит пользователь.
Для отбора кандидатов проводятся тысячи итераций обхода графа, которые начинаются с виртуальной “нулевой вершины” — самого пользователя к одной из его начальных вершин входящих в “групповые вкусы” с соответствующим весом и далее по графу. Вес ребра определяет вероятность перехода между вершинами, при этом в каждой вершине есть вероятность телепортироваться в начало обхода. Конечные вершины каждого обхода становятся кандидатами для рекомендаций.
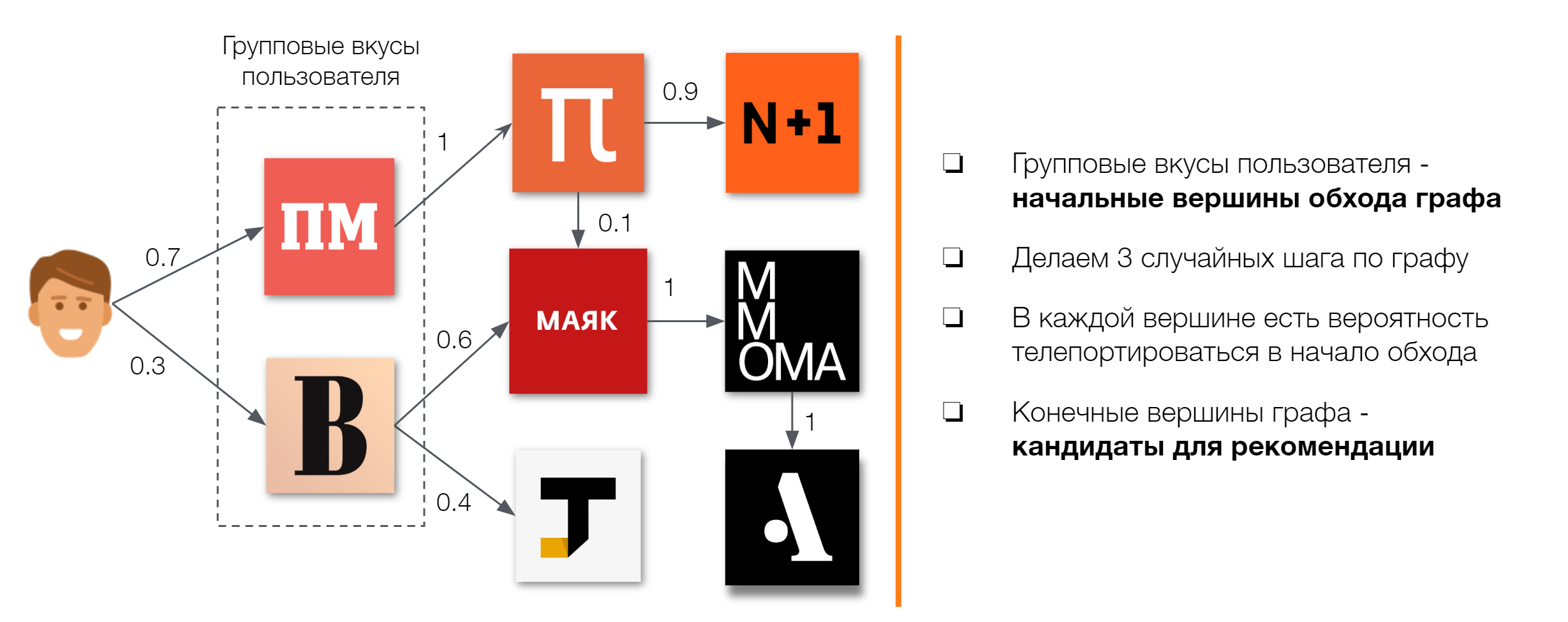
Подход к расчету похожести групп при построении рекомендательного графа аналогичен ItemKNN подходу, где для описания объекта рекомендаций служит вектор пользовательских рейтингов (взаимодействий).
На практике, при использовании такого подхода из графа выпадают небольшие группы, которые получают слишком малый вес близости из-за небольшого числа участников. Для решения этой и других проблем мы решили усовершенствовать механизм формирования графа, использовав модель нейронной сети word2vec.
Прокачиваем граф с помощью word2vec
Word2vec — модель нейронной сети, предназначенная для решения задач обработки естественного языка. Подробное описание того, как это работает, есть в переводе отличной статьи. Если вкратце, то с помощью word2vec можно получать векторные представления (эмбеддинги) слов, подавая на вход нейронной сети контекст, в которых они встречаются. Для задач рекомендаций вместо предложений из слов на естественном языке, мы формируем последовательности из объектов, относящихся к одному пользователю или пользовательской сессии, и на выходе получаем эмбеддинги для этих объектов.
Например, подавая на вход нейронной сети списки групп, в которых состоят пользователи, нейронная сеть сможет расположить их в векторном пространстве так, что они сформируют некоторые осмысленные кластера.
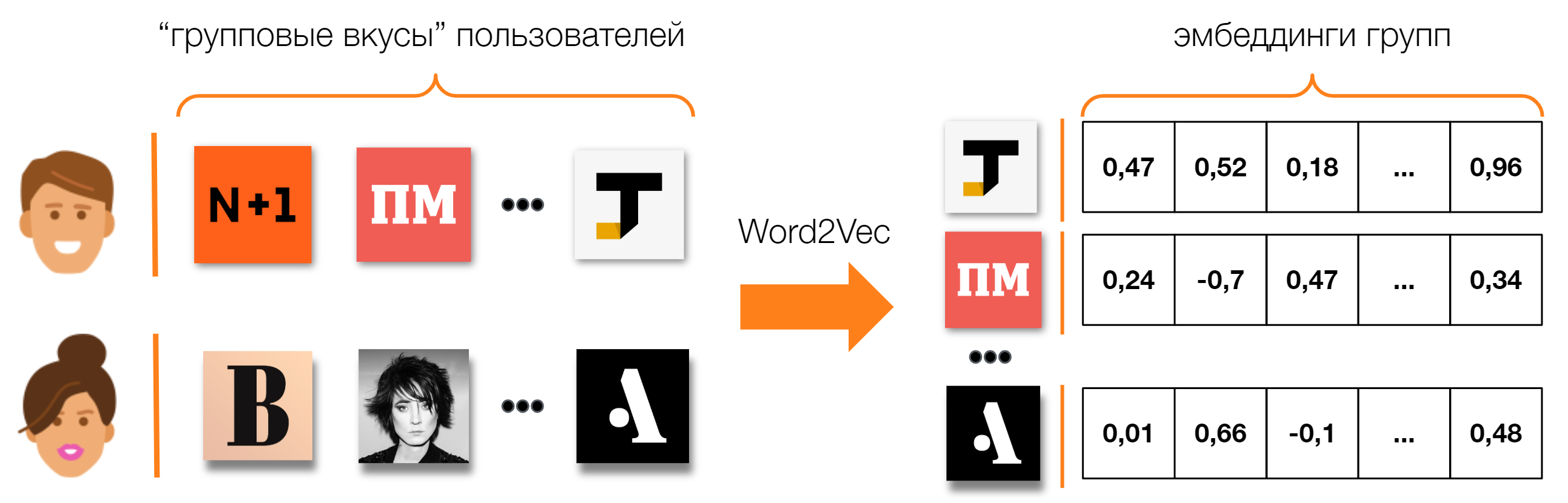
Обучив первую модель на данных об участиях пользователей в группах, мы получили эмбеддинги групп. Взяв top-k групп близких по косинусу эмбеддингов для каждой группы как исходящие ребра, получился более богатый на небольшие группы граф (число групп увеличилось в 4 раза). Результаты А/Б эксперимента показали +25% к общим вступлениям в группы, при этом вступления в группы меньше 1 тысячи участников выросли в 13 раз.
Классические упражнения для проверки интуиции с полученными векторами групп также показали, что модель выучила что-то осмысленное.

Интуитивно кажется, что все верно: если из большого СМИ про все на свете (ТАСС) вычесть деловое издание (РБК), то останется группа нишевого издания про науку (Образовач — N+1).
Артефакты наивного подхода
В первой итерации для обучения брали просто факт участия в группе, и это было неплохим приближением. Однако несколько артефактов, замеченных при внимательном изучении результатов, заставили нас задуматься о том, что сам факт участия в группе не является железобетонным указанием того, что пользователю она интересна.
В качестве хорошего примера можно взять группу музыкального проекта “Нейромонах Феофан”. Стилистика оформления у коллектива очень аутентичная (говорят, что там даже поет медведь) и не все пользователи по названию, аватару и даже фотографиям группы сразу понимают ее назначение. Поэтому, среди участников группы Феофана есть пользователи, которые на самом деле попали туда по ошибке. Из-за этого оказалось, что в первых вариациях модели, наряду с музыкальными проектами к Феофану в топ похожих, попали группы религиозной направленности.

Кроме этого случая, удалось выловить несколько примеров групп, радикально изменивших свою тематику, при этом понятно, что аудитория измениться не успела и выученные эмбеддинги таких групп попадали в абсолютно нерелевантные кластера. Так, крупная группа для автомобилистов с постами/обзорами машин превратилась в кулинарное сообщество.
Из-за того, что “групповые вкусы” являются еще и начальными точками обхода графа, попадание туда случайной группы приводило к тому, что пользователь мог систематически получать нерелевантные рекомендации.
Качественнее данные — точнее модель
Для расширения и уточнения “групповых вкусов” мы решили использовать все доступные данные о пользовательских взаимодействиях с группами и групповым контентом, взвешивая их по времени получения (новые имеет больший вес):
- Собираем неявный фидбек: все открытия окон, просмотры видео в группах, клики в ленте и просмотры постов в ленте (число и длительность просмотра).
- Собираем явный фидбек: классы, решары, комменты.
- С негативным весом добавляем скрытия контента, выход из групп, отписки от групповых оповещений.
- Нормализуем взаимодействия на количество показов контента (исключаем перекос активно постящих групп).
- Взвешиваем по типу контента, учитывая то, насколько давно пользователь ознакомился с группой (уменьшаем вес случайным действиям).
- Нормализуем веса групп во вкусах пользователей. Эти веса и будут весами ребер графа на первом шаге обхода графа.
После обучения модели на этих данных и настройки параметров word2vec обнаруженные ранее артефакты исчезли, а А/Б эксперимент показал +23% к вступлениям в группы меньше 1 тысячи человек и 9,5% в группы с от 1 до 10 тысяч участников.
Холодные или чуть теплые пользователи
Что делать, если пользователь потребляет мало контента и собранных "вкусов" недостаточно, чтобы предложить ему полноценную витрину рекомендаций? Как всегда, на помощь приходят друзья, в нашем случае это друзья самого пользователя. Мы считаем, что скорее всего человек разделяет "вкусы" своих друзей (особенно той же соцдем-группы), и подмешиваем их в начальное множество вершин обхода графа.
В худшем случае берем соцдемы (Top-N популярных с группировкой по полу, возрасту и географии), которые почти всегда являются универсальной палочкой-выручалочкой. Наконец, если вдруг мы совсем ничего не знаем про пользователя (он только зарегистрировался и даже не успел заполнить профиль), есть общий топ популярных на портале групп. Кстати, его же мы используем как резерв, если рекомендательный сервис по какой-то причине недоступен.
Хороший, плохой, злой
Существенная часть групп в Одноклассниках состоит из сообществ единомышленников, но в то же время большое число групп ведутся профессионалами в коммерческих целях: от крупных брендов с интересным содержанием до банального спама.
Иногда в группу вкладывают много сил и создают практически отдельное сильное медиа, но потом передают её тем, кого волнует только монетизация. Такие группы быстро теряют прежний объём фидбека, но по инерции могут ещё долго занимать выгодное положение в выдаче рекомендательной системы. Так как две трети от всех вступлений в группы в Одноклассниках происходят через рекомендации, мы должны следить за тем, чтобы пользовательское внимание занимали не просто релевантные, но и качественные группы с вовлекающим контентом.
Граф близости групп не может обеспечить это сам по себе, поскольку некоторым очень хорошим группам может не повезти и они не наберут входящих связей от крупных групп, а некоторым некачественным группам, наоборот, алгоритм может присвоить одну-две связи от крупных групп. Это может привести к существенному разбросу числа их рекомендательных показов, так как связи от крупных групп приведут большее число пользователей первым шагом обхода графа.
Для решения этой проблемы мы разработали алгоритм построения графа, учитывающий помимо похожести групп два дополнительных фактора: “мощности” исходной вершины и “качества” конечной.
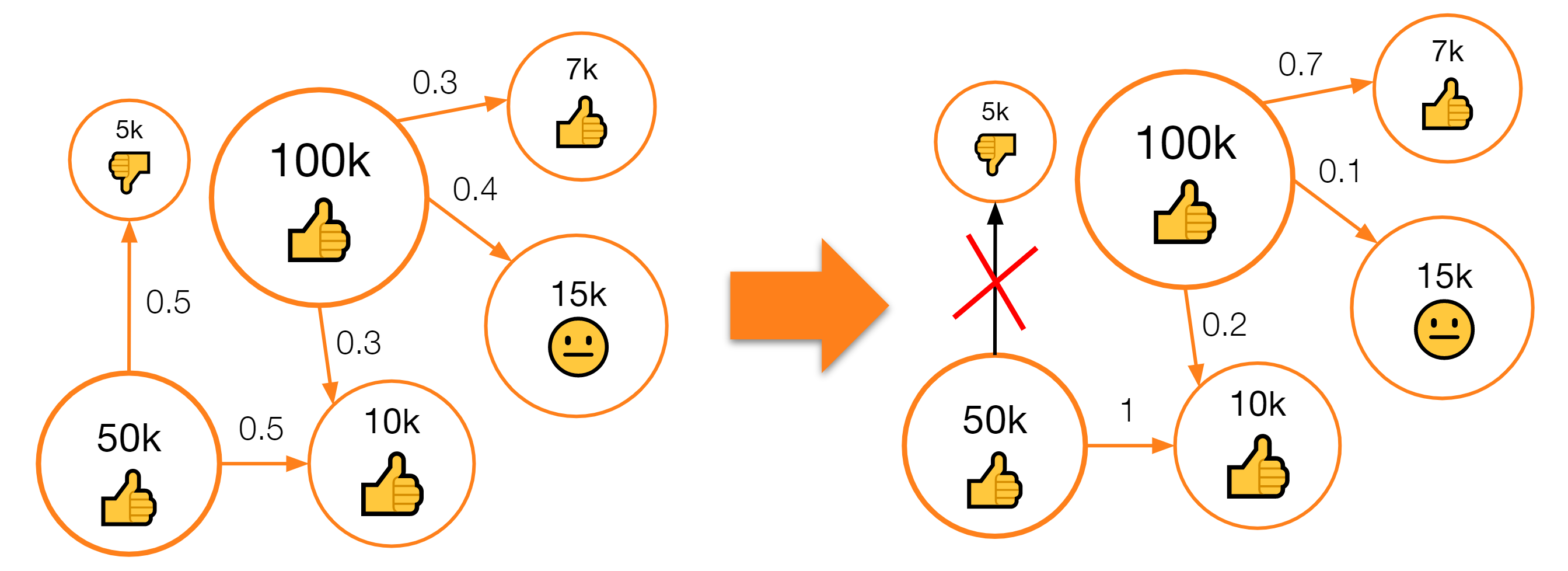
“Мощность” из этих двух нововведений посчитать проще всего: чем больше активных участников у группы, тем она мощнее, поскольку её исходящие связи в графе будут оказывать влияние на рекомендации большему числу пользователей. “Качество” посчитать значительно сложнее и мы продолжаем совершенствовать механизм его оценки так, чтобы с одной стороны точно убрать из рекомендаций неинтересные группы, а с другой, не допустить случаев, когда группа интересная, но проваливается в “некачественные”.
Для подсчёта “качества” мы собираем около ста характеристик каждой группы для обученной логистической регрессии. Модель для этого этапа выбрали наиболее простую для удобства интерпретации результатов.
Далее, имея исходный граф близости групп, “мощность” и “качество” каждой группы, остается решить только задачу балансирования этих трёх факторов: т. е. построить граф, в котором от наиболее “мощных” групп связи идут к наиболее “качественным”, при этом вес связи должен в неменьшей степени учитывать схожесть. К сожалению, решить её за разумное время можно только приблизительно, поскольку это задача из класса NP. Однако, уже за 10 итераций фильтрации входящих и исходящих связей с учётом “мощности” и “качества” соответственно, приближённое решение оказывается вполне достойным.
Итоги
В сухом остатке, word2vec, дополнительные данные и учёт мощности и качества групп при формировании графа по сравнению с оригинальным подходом дали:
- x4 к числу групп в рекоммендере;
- x13 вступлений в группы численностью менее 1к пользователей;
- +30% к общим вступлениям в группы.
Что еще мы применяем
Рекомендательные системы в Одноклассниках работают во всех ключевых сервисах и помимо графового рекоммендера, мы используем широкий спектр технологий:
- За формирование умной ленты отвечает градиентный бустинг в реализации XGBoost, с интересной историей внедрения.
- Под капотом рекомендаций музыки работает ранжирующая модель с WARP loss в реализации LightFM.
- Рекомендации китайских товаров строятся с помощью нейронной сети.
- Для рекомендаций друзей в сервисе “Возможно вы знакомы” используются нетривиальные графовые эвристики.
- Еще есть байесовские многорукие бандиты, BPR, старый-добрый SVD и другие.