

Adversarial Autoencoders: порождение дискретных объектов

У базовой архитектуры GANs есть одно существенное фундаментальное ограничение – подход не работает, если данные дискретные.
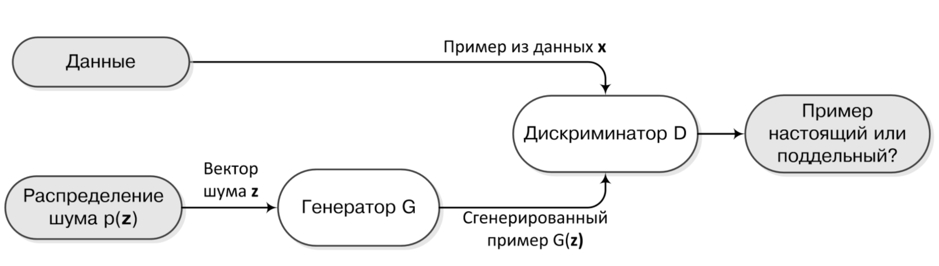 Чтобы эффективно обновлять «веса», мы должны уметь пропускать градиент от Дискриминатора через примеры, порождённые Генератором. Понятно, что если данные представляют из себя бинарные вектора (например, bag of words или целые предложения), то ни о каком градиенте не может идти речи.
Чтобы эффективно обновлять «веса», мы должны уметь пропускать градиент от Дискриминатора через примеры, порождённые Генератором. Понятно, что если данные представляют из себя бинарные вектора (например, bag of words или целые предложения), то ни о каком градиенте не может идти речи.
Какое же есть решение?
К счастью для нас, обойти такое ограничение можно с помощью старых добрых автоэнкодеров.
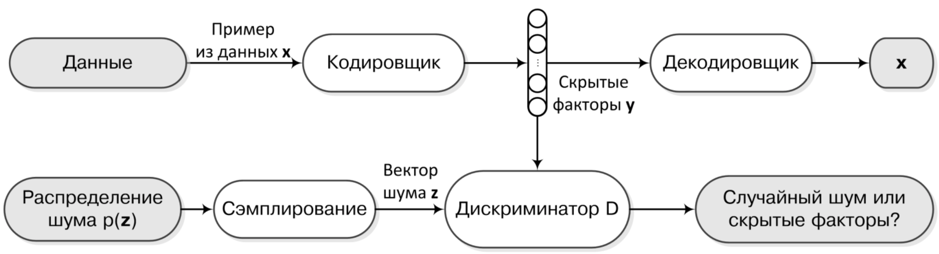 Давайте инвертируем задачу и заставим Генератор отображать реальные данные в шум, а Дискриминатор пытаться отличить этот шум от какого-нибудь заданного приорного распределения (как всегда N(0,1) очень хорошо подходит).
Давайте инвертируем задачу и заставим Генератор отображать реальные данные в шум, а Дискриминатор пытаться отличить этот шум от какого-нибудь заданного приорного распределения (как всегда N(0,1) очень хорошо подходит).
Фактически эта задача не отличается от исходной, но остаётся вопрос: как же нам генерировать новые примеры? Для этого достаточно наложить дополнительное ограничение на Генератор – он должен выдавать не совсем случайный шум, а такой, из которого потом было бы возможно восстановить исходный пример, например, с помощью дополнительной сети – Декодеровщика.
Понятно, что в новой схеме мы не ограничены непрерывностью данных, так как сами данные появляются только на внешних слоях автоэнкодера. А градиент от Дискриминатора свободно течёт через непрерывное распределение внутреннего слоя. Теперь чтобы получить новый пример из данных, мы как и раньше сэмплируем из заданного приорного распределения, но для порождения используем уже не Генератор, а Декодеровщик.
Этот относительно простой трюк позволяет обучать генеративные модели не только для порождения текстов и естественных языков, но и, например, для порождения молекулярных структур, которые тоже представляют из себя дискретные объекты.
Всем интересующимся я крайне рекомендую подробно ознакомиться с оригинальной статьей Adversarial Autoencoders, в которой помимо новой архитектуры авторы демонстрируют, например, то, как с помощью такого подхода можно научиться порождать изображения рукописных цифр, не только задавая цифру, но и её стиль.
 На этом изображении авторы генерируют различные цифры, фиксируя при этом «стиль» написания. Как видите это работает довольно неплохо!
На этом изображении авторы генерируют различные цифры, фиксируя при этом «стиль» написания. Как видите это работает довольно неплохо!
Есть вопросы? Напишите в комментариях!