

Поиск аномалий с One-Class SVM

Поиск аномалий может быть как конечной целью анализа и построения моделей, так и промежуточным этапом подготовки и очистки данных. В первом сценарии мы хотим научиться для каждого объекта выборки выносить вердикт, является ли он аномальным/нестандартным, а во втором мы находим и убираем выбросы в данных, чтобы в дальнейшем получить более устойчивые модели.
В определении из документации scikit-learn, задача поиска аномалий разделяется на два возможных типа:
- Outlier detection (поиск выбросов): в тренировочной выборке содержатся выбросы, которые определяются как наблюдения, лежащие далеко от остальных. Таким образом, алгоритмы для детектирования выбросов пытаются найти регионы, где сосредоточена основная масса тренировочных данных, игрорируя аномальные наблюдения.
- Novelty detection (поиск "новизны"): тренировочная выборка не загрязнена выбросами, и мы хотим научиться отвечать на вопрос "является ли новое наблюдение выбросом".
Сложности при поиске аномалий
На практике задача поиска аномалий зачастую не сводится к построению бинарного классификатора "выброс/не выброс". Реальные данные редко бывают размечены, и мы вынуждены использовать методы обучения без учителя.
Одновременно с этим возникает вопрос о построении надежной схемы валидации, ведь если "правильных ответов" у нас нет, то и понять, насколько алгоритм справляется со своей задачей, уже сложнее. Здесь очень помогут экспертные оценки о проценте аномальных объектов, которые ожидаются в выборке, так как с ними можно будет сравнивать прогнозные значения и варьировать тем самым чувствительность алгоритмов.
Если же поиск и очистка от аномалий — это шаг в подготовке данных для последующего моделирования, то можно использовать стандартные подходы: разбиение на train/test, кросс-валидацию и т. д. Конечно, чтобы избежать переобучения, очистка в этом случае должна проводиться только на тренировочной части датасета.
Коротко о Support Vector Machine
Если совсем вкратце, SVM — базовая линейная модель. Основная идея алгоритма (в случае с классификацией) — разделить классы гиперплоскостью так, чтобы максимизировать расстояние (зазор) между ними. Изначально алгоритм был способен работать только с линейно разделимыми классами, однако в 90-е годы прошлого века метод стал особенно популярен из-за внедрения "Kernel Trick" (1992), позволившего эффективно работать с линейно неразделимыми данными.

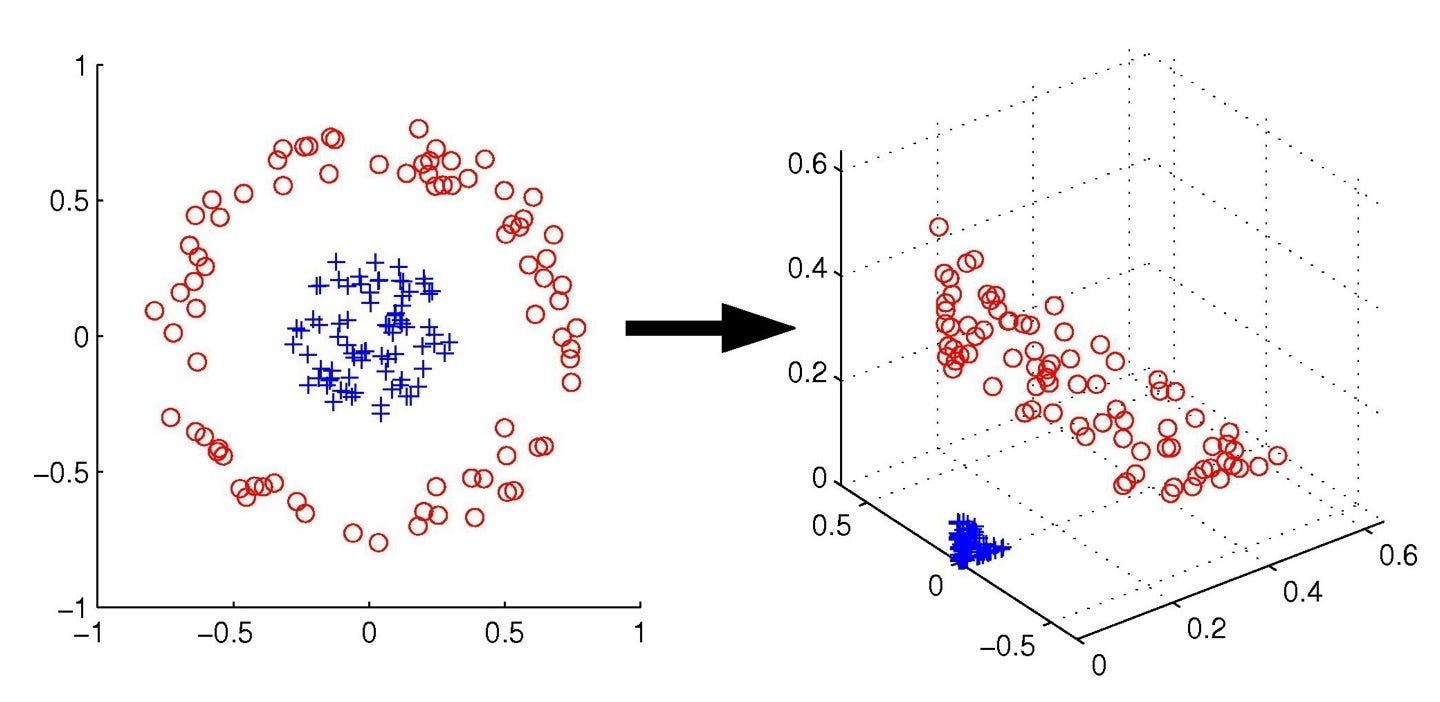
Kernel Trick
Ядро (kernel) — это функция, которая способна преобразовать признаковое пространство (в том числе нелинейно), без непосредственного преобразования признаков.
Крайне эффективна в плане вычисления и потенциально позволяет получать бесконечноразмерные признаковые пространства.
Идея заключается в том, что классы, линейно неразделимые в текущем признаковом пространстве, могут стать разделимыми в пространствах более высокой размерности:
One Class SVM
One Class SVM — это одна из форм классического алгоритма, однако, как следует из названия, для его обучения нам достаточно иметь всего один класс.
Если мы имеем дело с задачей novelty detection, где для тренировки нам доступны только "хорошие" наблюдения без аномалий, то мы можем воспользоваться этой моделью и научиться для каждого нового наблюдения говорить, является ли оно аномальным или нет.
Общая идея: преобразовать признаковое пространство и провести разделяющую гиперплоскость так, чтобы наблюдения лежали как можно дальше от начала координат:

В результате мы получаем границу, по одну сторону которой максимально плотно упакованы наблюдения из нашей чистой тренировочной выборки, а по другую будут находится аномальные значения, не похожи на то, что алгоритм видел во время обучения.
Плюсы и минусы
+ Благодаря kernel trick, модель способна проводить нелинейные разделяющие границы
+ Особенно удобно использовать, когда в данных недостаточно "плохих" наблюдений, чтобы использовать стандартный подход обучения с учителем — бинарную классификацию
- Может очень сильно переобучиться и выдавать большое количество ложно отрицательных результатов, если разделяющий зазор слишком мал
- И, конечно, нужно быть абсолютно уверенным, что тренировочные данные не содержат никаких выбросов, иначе алгоритм будет считать их нормальными наблюдениями

Больше о различных методах детектирования аномалий вы сможете узнать на занятии "Поиск аномалий в данных" в рамках курса Machine Learning.