

Основные алгоритмы машинного обучения

В этой статье мы поговорим об основных алгоритмах, которые используются в процессе машинного обучения. И назовём лучшие из них по мнению Джеймса Ли, автора статьи «A Tour of The Top 10 Algorithms for Machine Learning Newbies». Как говорится, встречайте «горячую десятку»!
Алгоритм алгоритму рознь
Знакома ли вам теорема «No Free Lunch»? Суть её проста: не существует алгоритма, который стал бы наилучшим выбором для любой задачи и особенно обучения с учителем. К примеру, мы не можем утверждать, что нейронные сети всегда функционируют лучше, нежели деревья решений. Собственно говоря, на эффективность работы алгоритма оказывает влияние множество данных, включая и размер данных, и структуру набора данных.
Именно по этой причине нам нужно пробовать разные алгоритмы и проверять их эффективность на тестовых наборах данных, а только после этого выбирать наилучший вариант. Естественно, выбирать следует из алгоритмов, соответствующих поставленным задачам. Очевидно, что убирая квартиру, вы будете использовать веник или пылесос, но уж точно не лопату.
Идём дальше. Алгоритмы машинного обучения мы можем описать как обучение целевой функции f, которая самым лучшим образом соотносит входные переменные x и выходную переменную y: y = f(x).
При этом нам неизвестно, что же из себя представляет функция f. А если бы мы и знали, то применяли бы её напрямую, не пытаясь обучить посредством разных алгоритмов.
Самая распространённая задача в машинном обучении — предсказание значений y для новых значений x. Речь идёт о прогностическом моделировании, где наша цель — сделать предсказание максимально точным.
После нашего непродолжительного вступления пришло время поговорить о наиболее популярных алгоритмах, применяемых в машинном обучении.
1. Линейная регрессия
Один из самых понятных и известных алгоритмов в машинном обучении и статистике. Его можно представить в форме уравнения, описывающего прямую, максимально точно показывающую взаимосвязь между выходными переменными y и входными переменными x. Чтобы составить уравнения, найдём определённые коэффициенты b для входных переменных.
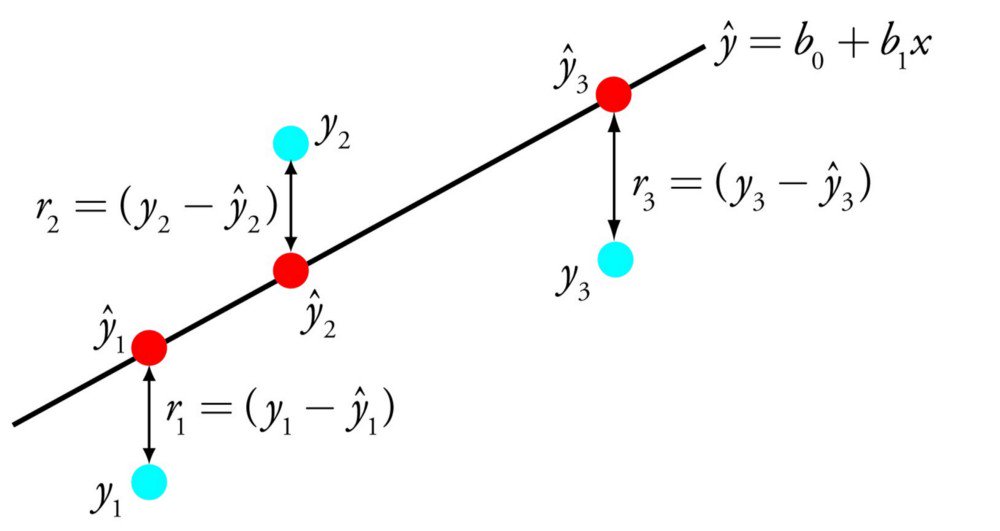
К примеру:
y = b0 + b1 * x
Зная x, мы должны найти y. Что касается цели этого алгоритма, то она состоит в поиске значений коэффициентов b0 и b1.
Чтобы оценить регрессионную модель, используют разные методы, например, метод наименьших квадратов. Вообще, линейная регрессия существует не одну сотню лет, поэтому алгоритм тщательно изучен. Он считается быстрым, простым и хорошо подходит для изучения в качестве первого алгоритма в машинном обучении.
2 . Логистическая регрессия
Очередной алгоритм, который пришёл в машинное обучение из статистики. Прекрасно подходит для решения задач бинарной классификации.
Чем логистическая регрессия похожа на линейную? Прежде всего, тем, что в ней нужно найти значения коэффициентов входных переменных. Но есть и разница: выходное значение преобразуется посредством логистической или нелинейной функции.
Логистическая функция имеет форму большой буквы S, преобразовывая любое значение в число в диапазоне от 0 до 1.
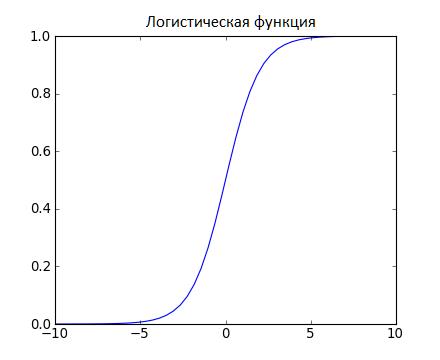
Как и линейная регрессия, логистическая выполняет свою задачу лучше, если уберём лишние и похожие переменные. Модель быстро обучается и отлично подходит для задач бинарной классификации.
3. LDA — линейный дискриминантный анализ
Логистическая регрессия применяется, если нужно отнести образец к одному из 2-х классов. Но если классов более двух, лучше подходит алгоритм LDA. Его представление довольно простое и состоит из статистических свойств данных, которые рассчитаны для каждого класса. Это включает для каждой входной переменной: — дисперсию, рассчитанную по всем классам; — среднее значение для каждого класса.
Предсказания выполняются при вычислении дискриминантного значения для классов и выбора класса, имеющего наибольшее значение. Мы предполагаем, что данные нормально распределены, поэтому удаляем из данных аномальные значения перед началом работы. Этот алгоритм для машинного обучения считается простым и эффективным при решении задач классификации.
4. Древа принятия решений
Древо решений представляют в форме 2-ичного древа, знакомого по структурам данных и алгоритмам. Здесь любой узел — это входная переменная и точка разделения для этой переменной, но при условии, что переменная является числом.
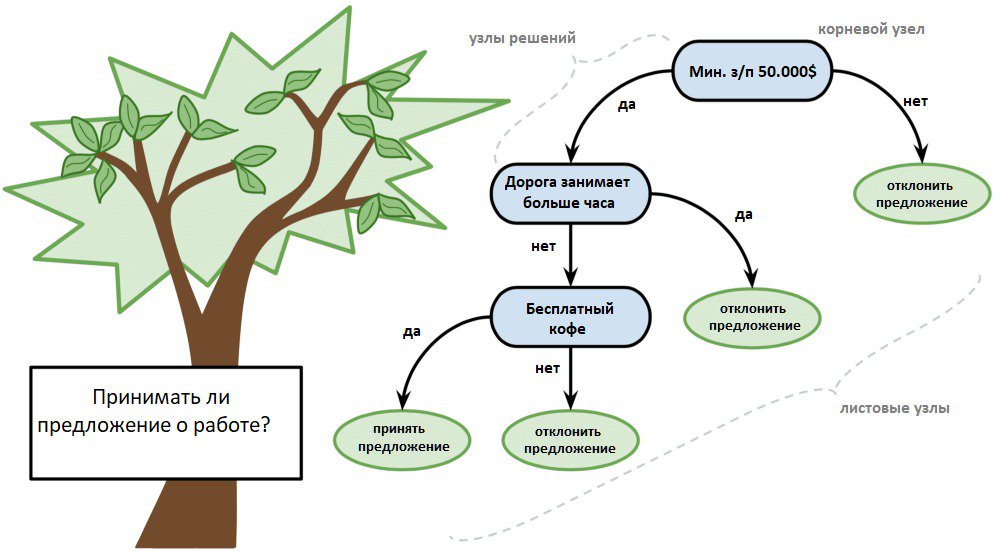
В качестве выходных переменных выступают листовые узлы, используемые для предсказания. Последние выполняются посредством прохода по древу к листовому узлу с последующим выводом значений класса на данном узле.
Древа быстро обучаются, точны для большого спектра круга задач, плюс не нуждаются в особой подготовке данных.
5 . Наивный Байесовский классификатор
Простой, но весьма эффективный алгоритм.
Здесь модель состоит из 2 типов вероятностей, рассчитываемых посредством тренировочных данных, а именно: 1. Вероятность каждого класса. 2. Условная вероятность для каждого класса при каждом значении x.
После расчёта модели её можно применять для предсказания с новыми данными, используя теорему Байеса. Если данные вещественные, то при нормальном распределении рассчитать вероятности совсем несложно.
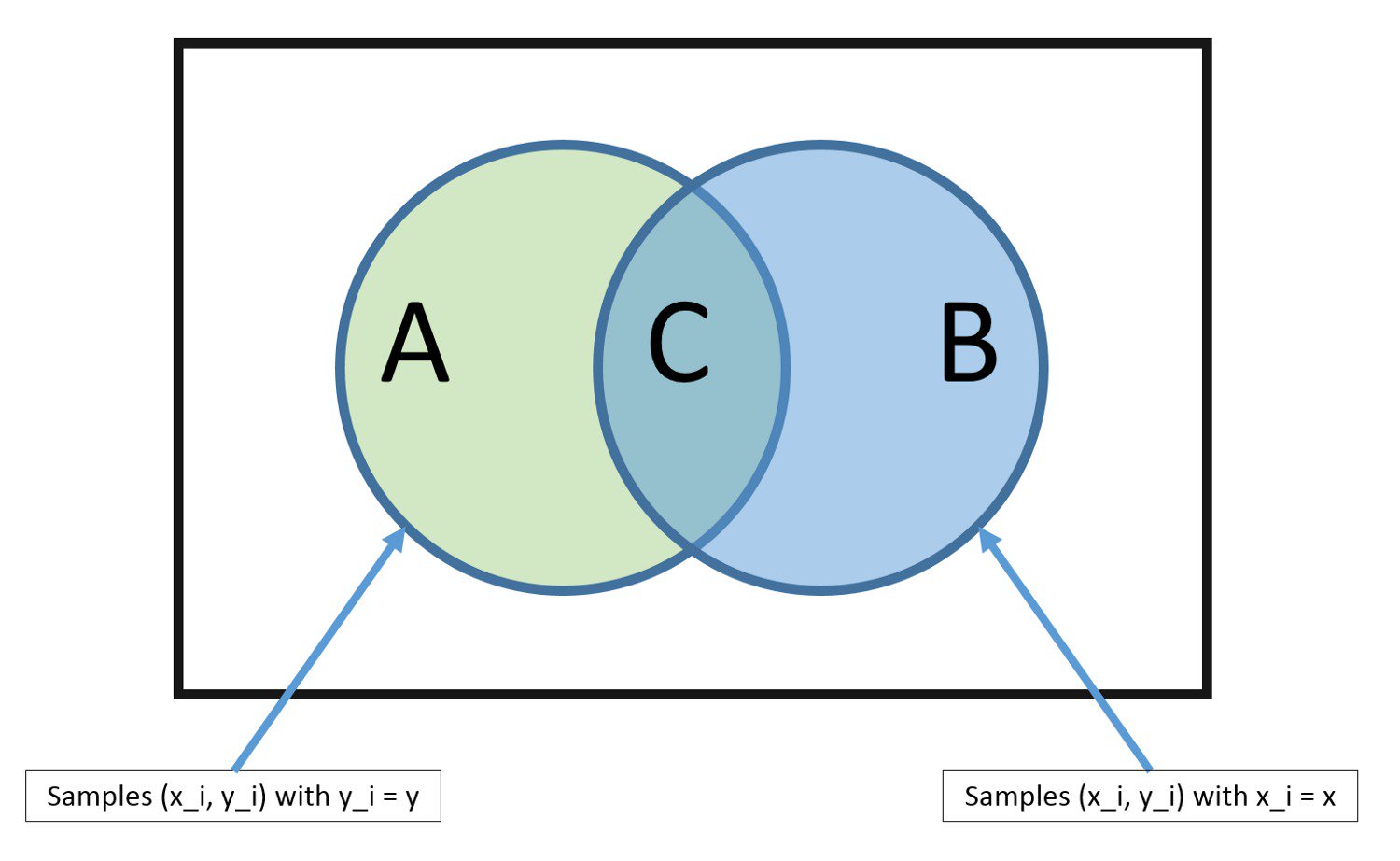
Байес называется наивным по той причине, что алгоритм предполагает, как будто каждая входная переменная независима. Это довольно сильное предположение, не соответствующее реальным данным. Но несмотря ни на что, алгоритм очень эффективен при решении ряда сложных задач, например, при классификации спама либо распознавании рукописных цифр.
6. KNN
Модель K-nearest neighbors представлена полным набором тренировочных данных. Предсказание для новой точки осуществляется посредством поиска «K-ближайших соседей» в наборе данных с последующим суммированием выходной переменной для этих K-экземпляров.
Появляется лишь вопрос, каким образом определить сходство между разными экземплярами данных. Например, если признаки имеют одинаковый масштаб (допустим, миллиметры), то проще всего использовать евклидовы расстояния — то есть числа, которые можно рассчитать, используя различия с каждой входной переменной.
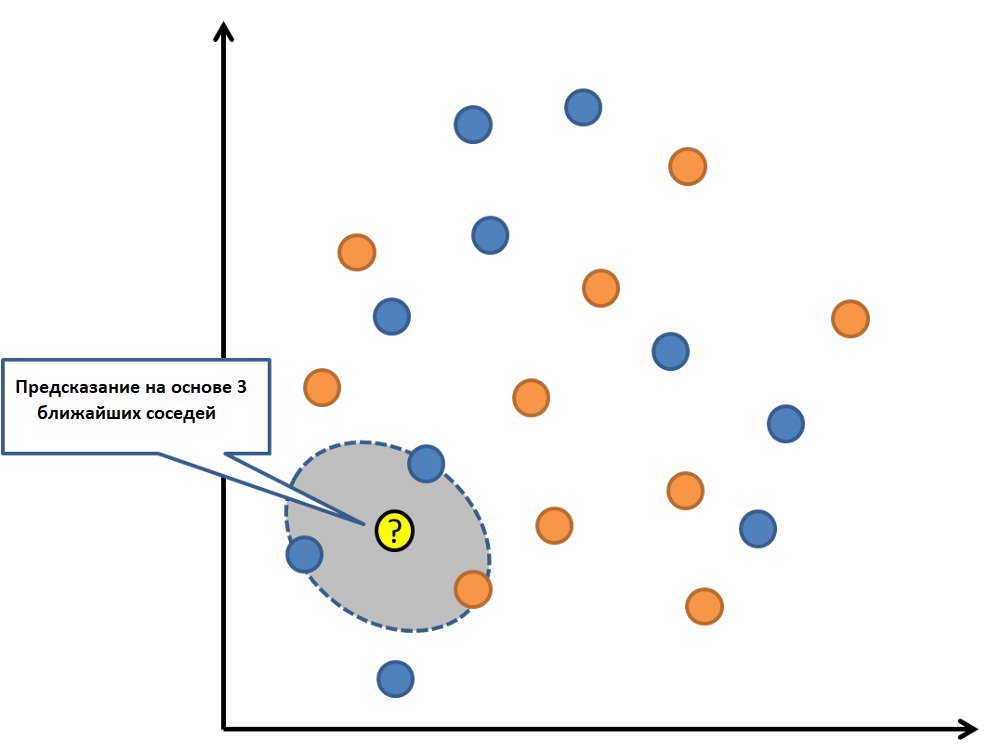
Для хранения всех данных при использовании KNN может потребоваться много памяти, но зато предсказание будет сделано быстро. Вдобавок ко всему, обучающие данные можно обновлять, дабы сохранить точность предсказаний с течением времени.
Идея KNN может не очень хорошо работать с многомерными данными (при множестве входных переменных), что негативно отразится на эффективности алгоритма (это называют «проклятием размерности»).
7 . LVQ — сети векторного квантования
Главный недостаток KNN — необходимость хранения всего тренировочного набора данных. Это недостатка лишён алгоритм LVQ (Learning vector quantization).
Это алгоритм, представляющий собой набор кодовых векторов. Векторы выбираются случайным образом в начале и в течение ряда итераций адаптируются таким образом, чтобы лучше всего обобщить весь набор используемых данных.
После обучения вектора могут применяться для предсказания по аналогии с KNN. В этом случае алгоритм тоже ищет «ближайшего соседа» (максимально подходящий кодовый вектор), вычисляя расстояние между новым экземпляром данных и каждым кодовым вектором. После этого для наиболее подходящего вектора в качестве предсказания происходит возвращение класса (или числа в случае регрессии). Наилучшего результата удаётся достичь, если все данные находятся в одном диапазоне, к примеру, от 0 до 1.
8. SVM — метод опорных векторов
Популярный и обсуждаемый алгоритм машинного обучения. В нём гиперплоскость (линия, которая разделяет пространство входных переменных) выбирается таким образом, дабы лучше разделить точки в плоскости входных переменных по их классу: 0 либо 1.
В 2-мерной плоскости это легко представить как линию, полностью разделяющую точки всех классов. В процессе обучения алгоритм ищет коэффициенты, помогающие разделять классы гиперплоскостью наилучшим образом.
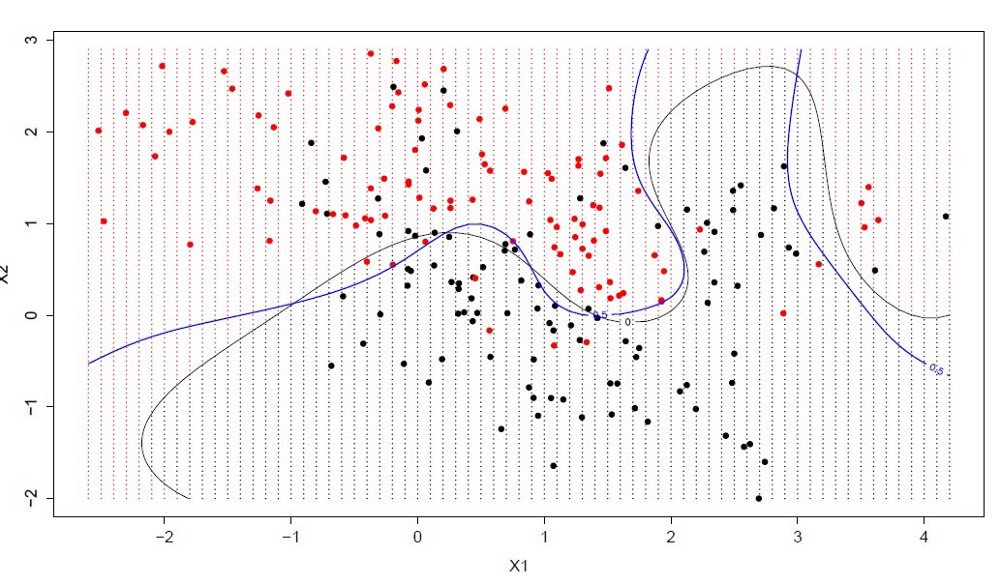
Разницей называется расстояние между ближайшими точками данных и гиперплоскостью. Оптимальной гиперплоскостью, разделяющей 2 класса, называют линию с наибольшей разницей. И лишь эти точки имеют значение при построении классификатора и определении гиперплоскости. Как раз эти точки и называют опорными векторами. Чтобы определить значения коэффициентов, максимизирующих разницу, используют специальные алгоритмы оптимизации.
Метод SVM считают одним из наиболее эффективных классических классификаторов.
9 . Бэггинг и случайный лес
Тоже весьма популярный алгоритм машинного обучения. По сути, это подвид ансамблевого алгоритма, называемого бэггингом.
Бутстрэп — эффективный статистический метод для оценки какой-нибудь величины вроде среднего значения. Мы берём много подвыборок из данных, считаем среднее значение для каждой, после этого усредняем результаты, чтобы получить лучшую оценку действительного среднего значения. Что касается бэггинга, то в нём задействуется тот же подход, но при оценке статистических моделей чаще используют древа решений. Тренировочные данные разбивают на много выборок, для каждой из них создаётся модель. Если надо сделать предсказание, это делает каждая модель, потом предсказания усредняются, чтобы дать выходному значению лучшую оценку.
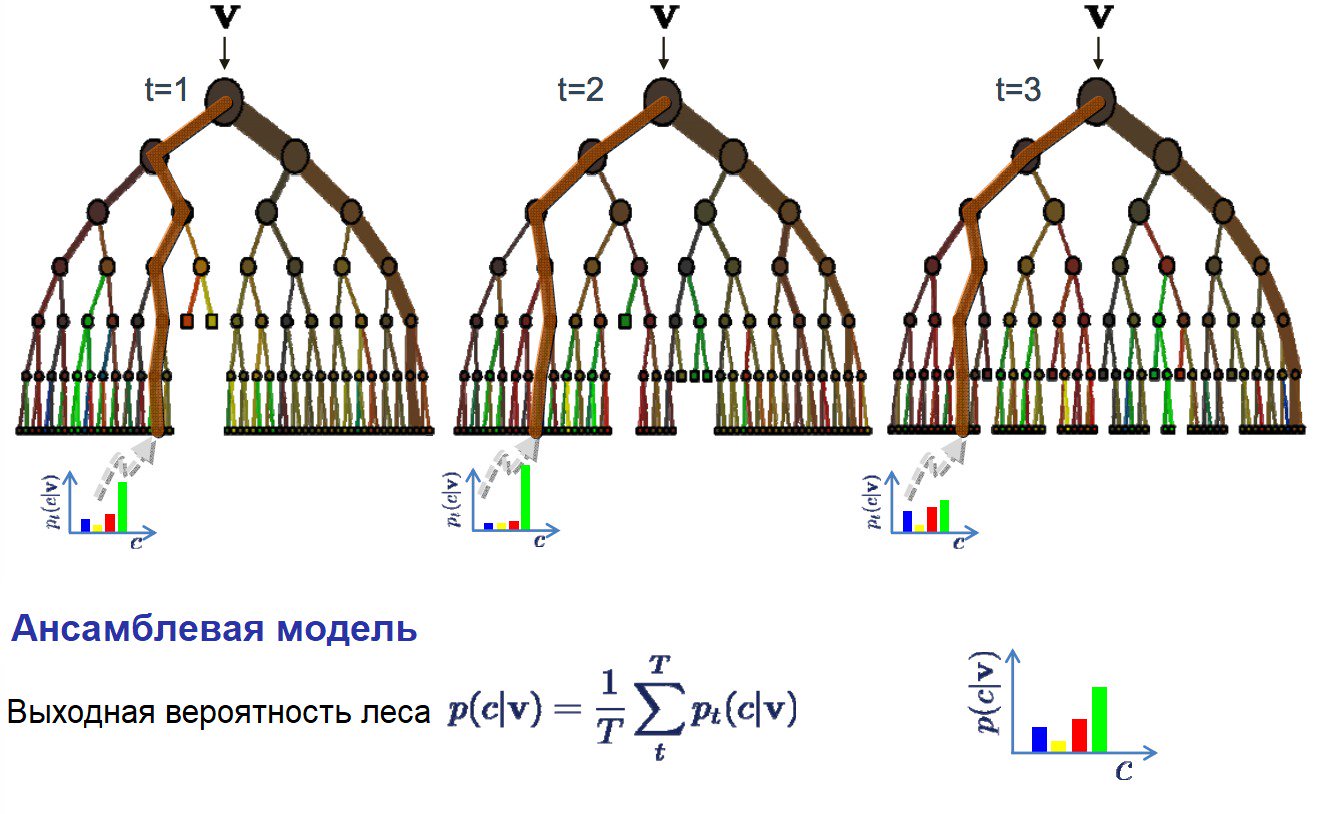
Алгоритмы случайного леса примечательны тем, что для всех выборок из тренировочных данных строят древа решений. И при построении для создания каждого узла выбирают случайные признаки. По отдельности полученные модели недостаточно точны, но в случае объединения качество предсказания существенно повышается.
10 . Бустинг и AdaBoost
Бустингом называют семейство ансамблевых алгоритмов. Их суть — создание сильного классификатора на основании нескольких слабых. При этом сначала создают одну модель, потом другую, которая пытается исправить ошибки, которые есть в первой. Модели добавляют до той поры, пока тренировочные данные не будут предсказываться идеально либо пока не превышается наибольшее число моделей.
Что касается AdaBoost, то это первый действительно успешный алгоритм бустинга, разработанный для бинарной классификации. Собственно говоря, именно с него лучше начинать знакомство с бустингом, как таковым. Кстати, современные методы вроде стохастического градиентного бустинга основаны на AdaBoost.
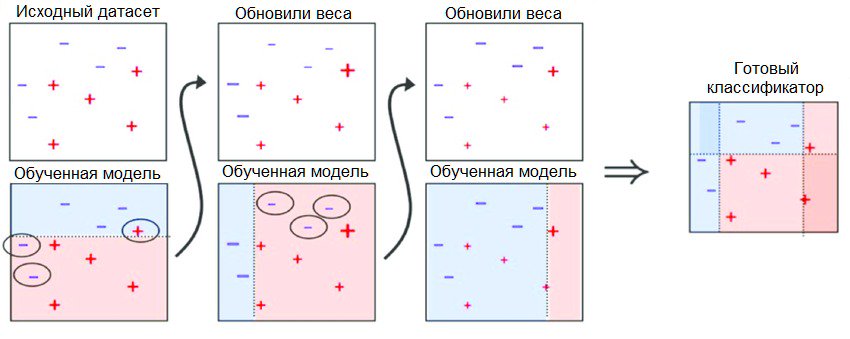
AdaBoost применяют вместе с короткими древами решений. После создания 1-го проверяется эффективность древа на каждом тренировочном объекте, что позволяет узнать, сколько внимания должно уделить следующее древо всем объектам. Данным, которые предсказать сложно, даётся больший вес, которые легко предсказать — меньший вес. Модели создают последовательно одну за другой, причём каждая из них обновляет веса для последующего древа. После того, как все деревья построены, выполняются предсказания для новых данных. В итоге эффективность каждого древа определяется исходя их того, насколько точным оно было на тренировочных данных.
В алгоритме много внимания уделяют исправлению ошибок моделей, поэтому надо следить, чтобы в данных не было аномалий.
Как выбрать алгоритмы для машинного обучения
Видя обилие алгоритмов, многие задумываются, какой из них выбрать. Ответ зависит от ряда причин: — качество, размер и характер данных; — требуемая срочность выполнения задачи; — доступное вычислительное время; — что вы хотите с этими данными делать.
Даже опытный data scientist не сможет точно сказать, какие алгоритмы будут более эффективны, не попробовав разные варианты. К тому же, мы привели лишь наиболее популярные алгоритмы для машинного обучения, есть и множество других. Впрочем, даже перечисленные алгоритмы станут неплохой отправной точкой.