

Глубокое обучение на множествах. Часть 1

В некоторых задачах машинного обучения объектами исследования могут быть множества — наборы объектов произвольного размера. Давайте рассмотрим возможные подходы к работе с множествами с помощью нейронных сетей.
В первой заметке мы поговорим о ситуации, когда исследуемый объект у нас один, а вот в качестве предсказаний модели мы ожидаем увидеть множество. Примером такой задачи может быть задача тегирования, когда одному изображению нужно поставить в соответствие набор описывающих его ключевых слов или тегов. А во второй заметке речь пойдет об обратной задаче — по набору тегов выбрать наиболее подходящее изображение.
Типичный датасет для обеих задач будет содержать пары, состоящие из изображения и соответствующего ему набора тегов. Нашей задачей будет выбрать наиболее подходящие теги из словаря всех возможных.
Итак, начнём!
В простейшем случае мы можем тренировать свёрточную сеть выдавать вероятность для каждого слова из словаря быть тегом для конкретного изображения. При таком подходе на выходе нейронной сети будет длинный вектор (размером со словарь), на основе которого мы можем выбрать какое-то количество наиболее подходящих слов.
Проблемы с таким подходом довольно очевидны: огромный размер последних слоёв сети, большая разрежённость, независимость тегов друг от друга и вопросы к выбору отсечки или количества тегов.
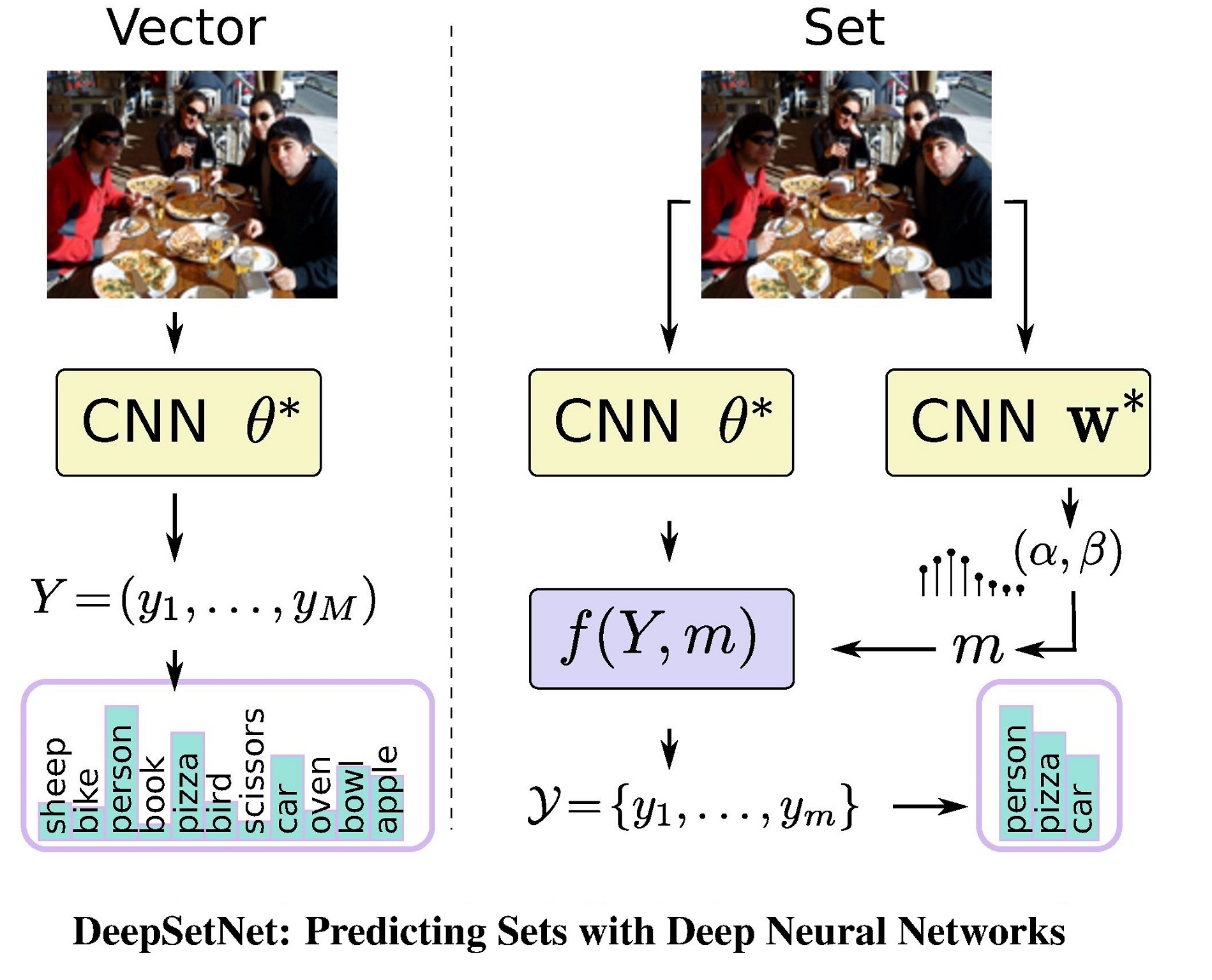 Статья «DeepSetNet: Predicting Sets with Deep Neural Networks», опубликованная в 2017 году на ICCV (международная конференция по компьютерному зрению), решает последнюю из этих проблем.
Статья «DeepSetNet: Predicting Sets with Deep Neural Networks», опубликованная в 2017 году на ICCV (международная конференция по компьютерному зрению), решает последнюю из этих проблем.
В дополнение к свёрточной сети, предсказывающей вероятности для каждого из возможных тегов в виде вектора, авторы предлагают тренировать ещё одну нейронную сеть, предсказывающую количество тегов, которое нужно выбрать для данного изображения. И, хотя это не решает остальные проблемы, данная статья всё-таки является хорошей иллюстрацией того, как можно работать со множествами.
Какой ещё возможен подход?
Другой подход, позволяющий избежать проблем с большим размером выходного вектора, разрежённостью и определением количества тегов, заключается в использовании рекуррентных сетей. Чтобы провернуть этот трюк, достаточно представить набор тегов, описывающих изображение, в виде последовательности и заменить последние слои сети из предыдущего решения на рекуррентную сеть, порождающую тег за тегом. Причём одним из элементов словаря в данном случае будет тег типа <хватит>, появление которого на выходе рекуррентной сети должно останавливать процесс порождения новых тегов.
Такой подход тоже не решает всех проблем, связанных с «предсказанием» множеств, но зачастую работает существенно лучше предсказания вероятностей для каждого слова. Одна из основных проблем — порядок тегов. Так как мы теперь работаем со множеством тегов как с последовательностью, нам надо установить порядок элементов в этой последовательности.
Одно из возможных решений этой проблемы я разберу на курсе в лекции, посвящённой генеративным рекуррентным моделям.
Следите за новостями и не забывайте оставлять комментарии!