

Модель seq2seq в машинном переводе

Ключевая идея модели заключается в том, что мы рассматриваем входные данные (предложение на языке А) и выходные данные (предложение на языке Б) как последовательности слов.
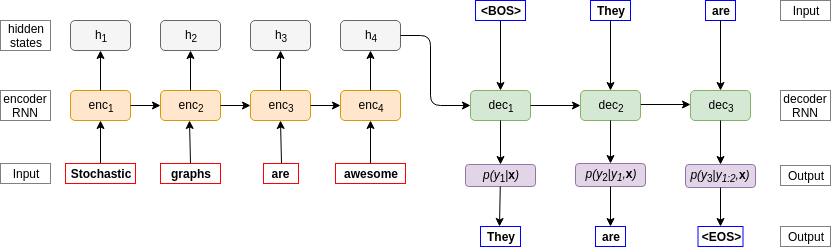 Таким образом, алгоритм перевода состоит из следующих основных этапов:
Таким образом, алгоритм перевода состоит из следующих основных этапов:
1) Энкодер (enc) последовательно считывает входное предложение и выдает вектор контекста «С». На рисунке передаче вектора контекста от энкодера к декодеру соответствует стрелка h4 → dec1.
2) Получив компактное описание входного предложения в виде «С», декодер (dec) генерирует слова на другом языке последовательно. Отдельным «словом» в словаре языка Б обозначим начало предложения «BOS» и конец предложения «EOS».
Схематично этот процесс представлен на рисунке.
Рассмотрим декодер подробнее
Его можно представить в виде следующей функции:
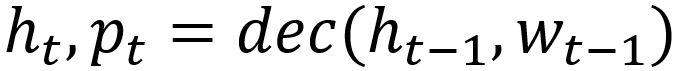
Здесь ht — вектор скрытого состояния декодера на шаге t (можно сказать, что декодер — такая «stateful» функция от предыдущего слова), pt — распределение по словам на шаге t, w(t-1) это слово, которое выбрано в качестве основной гипотезы исходя из распределения p(t-1) на шаге «t-1».
Для энкодера аналогичное уравнение выглядит следующим образом:
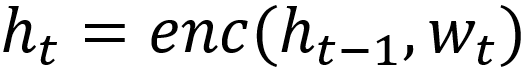
Обратите внимание, что в качестве финального вектора контекста C выбирается последнее скрытое состояние энкодера, в данном случае h4. В случае более сложных подходов (например, с добавлением механизмов т.н. «внимания») схема чуть усложнится.
В чем преимущество такого подхода?
Прежде всего тем, что количество параметров модели не зависит от длины предложения: одни и те же модели (enc и dec) работают на всех шагах по времени.
В завершение, вернемся к вопросу выбора правильной последовательности слов w1,w2,...wn, учитывая что декодер выдает только вероятности слов p1,p2,...pn.
Мы можем выбрать любое слово w(t-1) из категориального распределения p(t-1) над словарём, получить новое скрытое состояние ht и новое распределение pt. Выбору этого слова будет соответствовать определённая вероятность, которую будем обозначать p(t-1) (w(t-1)).
Выполняя на каждом шаге такую процедуру, получаем суммарную вероятность генерации последовательности слов:
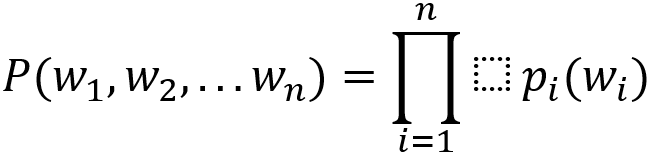
Простейший способ генерировать последовательность — выбирать на каждом шаге самое вероятное слово wt из распределения pt («greedy decoding»). Это, однако, не гарантирует нам, что мы найдём именно ту последовательность слов, которая максимизирует P(w1,w2,...wn) для заданного энкодера и декодера.
Есть вопрос? Напишите в комментариях!