

Гессиан Vector-Product трюк

В некоторых алгоритмах машинного обучения возникает необходимость в расчёте матрицы вторых производных функции
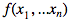 Будем называть её «гессиан»:
Будем называть её «гессиан»:
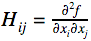 Примером может быть метод Ньютона для оптимизации.
Примером может быть метод Ньютона для оптимизации.
Вместе с тем, далеко не всегда необходима сама матрица гессиана. Иногда нужно лишь произведение этой матрицы на какой-то вектор: Hv (например, в методе сопряжённых градиентов для оптимизации). В этом случае можно избежать вычисления всего гессиана и рассчитать всего лишь 1 производную по направлению.
Будем обозначать градиент функции
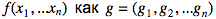 и получаем:
и получаем:
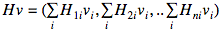 Рассмотрим одну компоненту этого вектора:
Рассмотрим одну компоненту этого вектора:
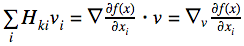 Как видно, это всего лишь производная по направлению для функции
Как видно, это всего лишь производная по направлению для функции 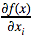 И её легко сосчитать с помощью конечных разностей для произвольной функции F(x):
И её легко сосчитать с помощью конечных разностей для произвольной функции F(x):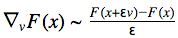 Запишем итоговую формулу:
Запишем итоговую формулу: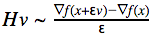
Дополнительные материалы: 1. Hessian Free Optimization; 2. Fast Exact Multiplication by the Hessian; 3. Посмотреть формулы из заметки можно здесь.
Есть вопрос? Напишите в комментариях!