

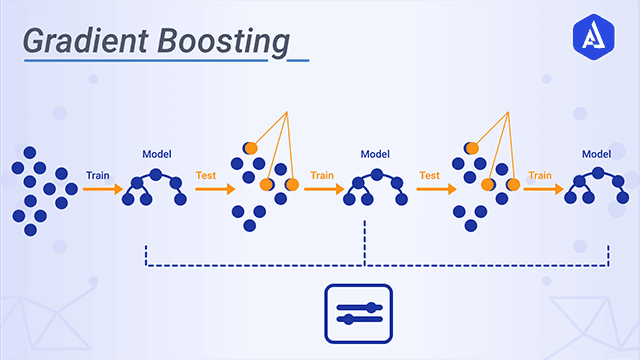
Боремся с переобучением у градиентного бустинга
Если вы проходите собеседование на ML-специалиста, у вас могут спросить, какие именно гиперпараметры вы бы настраивали в целях борьбы с переобучением у градиентного бустинга. Что ж, давайте попробуем ответить на этот вопрос.
Как правило, разъяснения строятся на основании разложения ошибки на смещение и разброс. Если говорить простыми словами, то смещение, по сути, показывает нам, насколько модели, которые обучены на различных выборках, ошибаются в среднем, тогда как разброс — это про то, насколько различными будут модели, которые обучены на разных выборках.
При этом каждая следующая базовая модель в бустинге будет обучаться таким образом, чтобы уменьшалась общая ошибка всех предшественников. В результате итоговая структура получит меньшее смещение, чем каждый отдельно взятый базовый алгоритм (да, уменьшение разброса может иметь место, но это не обязательно).
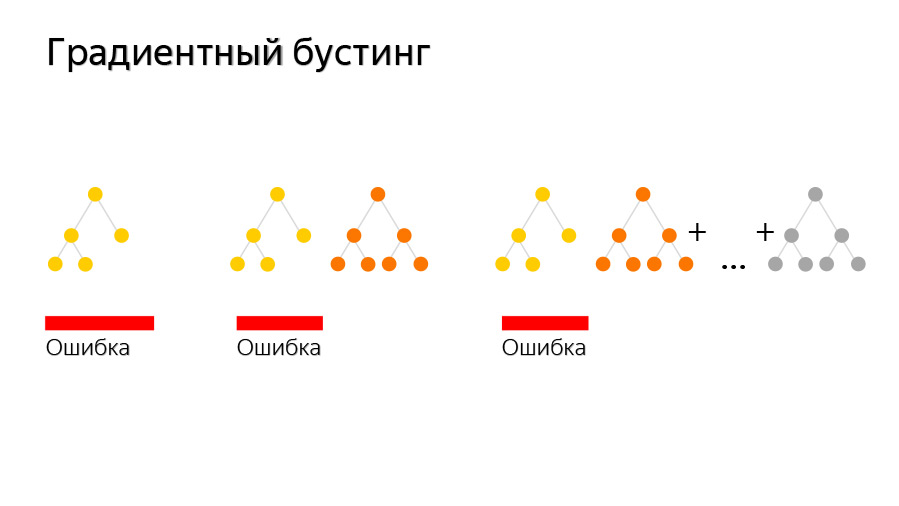 Идем дальше. Как правило, переобучение характеризуется низким смещением при высоком разбросе. А так как простым увеличением количества базовых моделей мы не уменьшим разброс, то надо будет снизить разброс каждой из моделей. В результате всё будет сведено к тому, что модели надо будет делать проще.
Идем дальше. Как правило, переобучение характеризуется низким смещением при высоком разбросе. А так как простым увеличением количества базовых моделей мы не уменьшим разброс, то надо будет снизить разброс каждой из моделей. В результате всё будет сведено к тому, что модели надо будет делать проще.
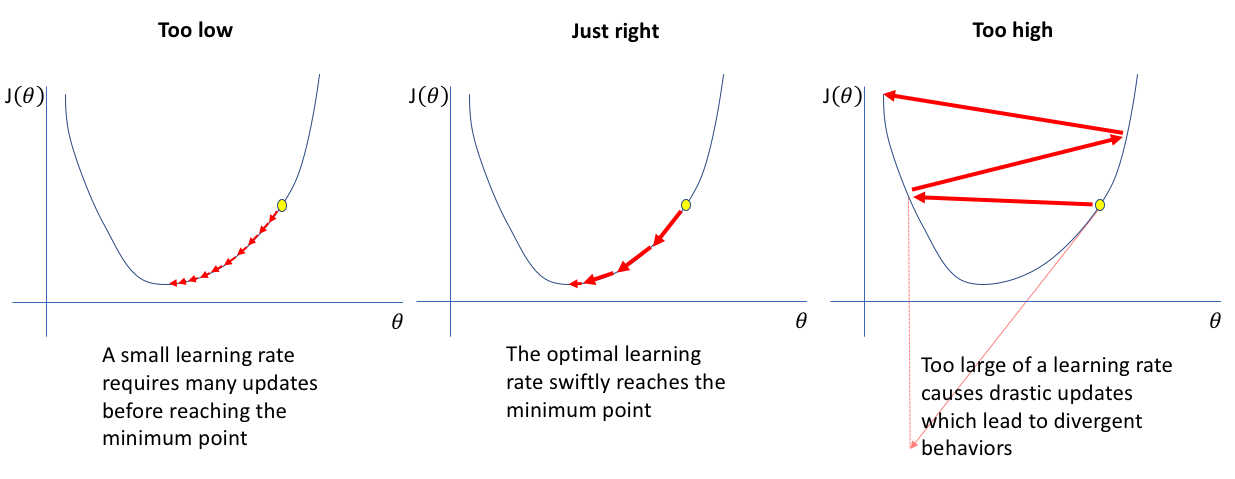
Но вообще, когда речь идет о бустинге над деревьями, то рекомендуется уменьшить их глубину (именно поэтому в бустинге чаще всего применяют деревья небольшой глубины). А так как базовые модели становятся проще, то есть целесообразность в увеличении их числа, однако при всем при этом мы не хотим, чтобы они черезчур быстро приблизили таргет на нашей обучающей выборке (что тоже являлось бы переобучением). Следовательно, здесь бывает весьма полезным одновременно уменьшить и темп обучения (learning rate).
По материалам tproger.ru.