

Как получить независимые модели при бэггинге?
Как известно, алгоритм машинного обучения "Случайный лес" (Random forest) основывается на принципе бэггинга, то есть на усреднении предсказания нескольких независимых моделей. Но что, если у нас только одна обучающая выборка? Каким образом в данном случае мы получим независимые модели? И почему на практике это не приводит к проблемам?
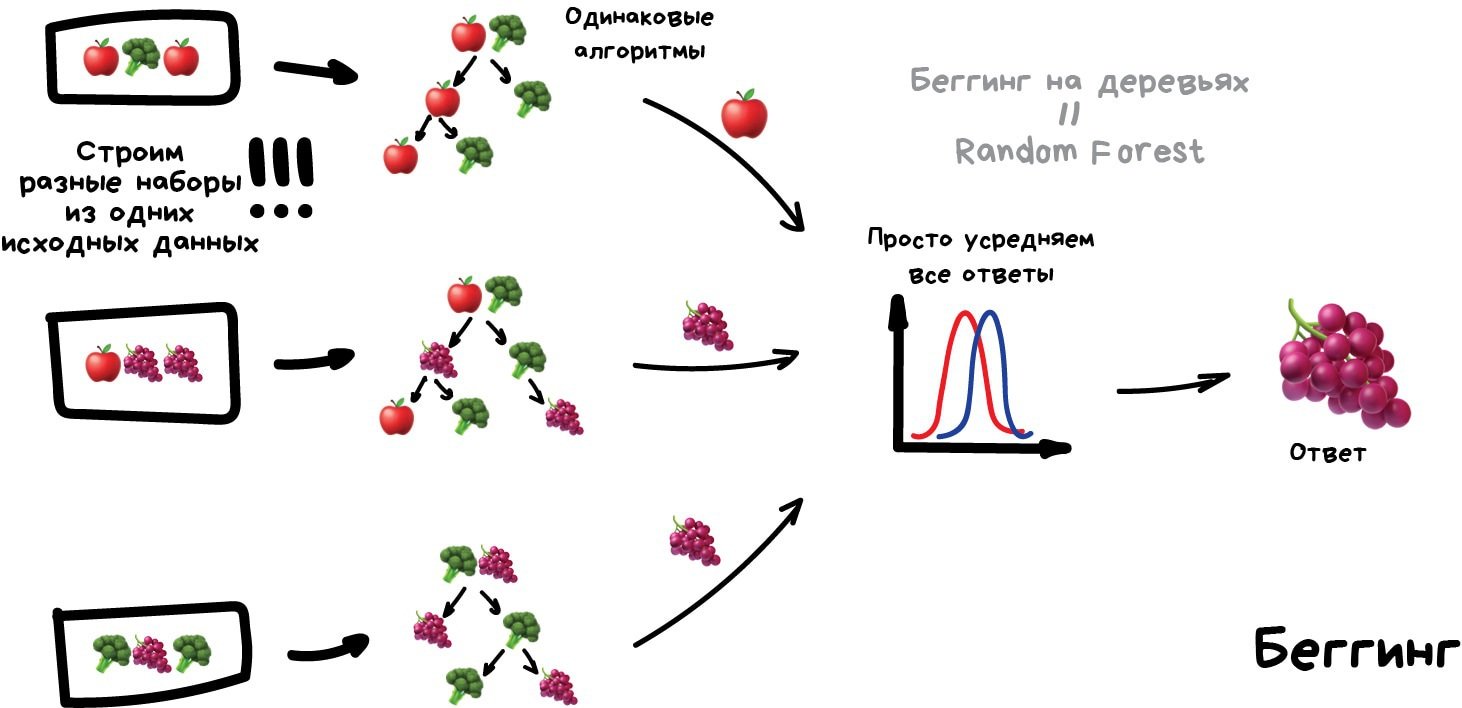
Для начала вспомним, что идея бэггинга (беггинга) заключается в том, чтобы просто агрегировать предсказания, которые выдаются базовыми моделями (к примеру, усреднять либо брать наиболее популярное предсказание). А для того, чтобы результат получился качественным, важно, чтобы каждая модель являлась достаточно сильной (именно поэтому главный пример бэггинга — это случайный лес, который задействует глубокие и переобученные решающие деревья).
Всё так, но давайте теперь вернемся к вопросам, которые заданы в начале статьи. Дело в том, что на практике оказывается, что, по сути, строгое выполнение предположения о независимости обязательным не является. То есть вполне достаточно, чтобы алгоритмы являлись лишь в некоторой степени непохожими друг на друга. При этом достаточная непохожесть будет обеспечена тем, что в процессе обучения каждого дерева мы:
- возьмем случайное подмножество обучающей выборки;
- возьмем случайное подмножество признаков.
Как-то так. Причем знание вышеописанных нюансов может вам пригодиться при прохождении собеседования. Кстати, раз мы уже заговорили об ансамблях ML-моделей, таких как бэггинг, то более подробную информацию можно найти здесь.
По материалам tproger.ru.