

Tsfresh: автоматически генерируем признаки из временных рядов

Продолжаем работать с временными рядами. В прошлой статье мы посмотрели, как использовать мощь глубокого обучения для прогнозирования временных рядов при помощи библиотеки GluonTS от Amazon. На сей раз вернёмся к "обычному" машинному обучению, где признаки по-прежнему нужно генерировать перед построением моделей (а не модели услужливо строят удобные для себя признаки).
Time Series FeatuRe Extraction based on Scalable Hypothesis tests

Автоматизируем рутину
При работе с временными рядами могут возникнуть две ситуации: 1. Мы хотим спрогнозировать временной ряд, основываясь на его предыдущих значениях. 2. Мы хотим использовать временной ряд как признак объекта.
И в первом, и во втором случае мы могли бы самостоятельно придумать различного рода эвристики и признаки, извлечь их из временного ряда и обучить на них модель. Типичными признаками могут быть предыдущие значения ряда, минимальные/максимальные значения в пределах некоторого окна, стандартное отклонение и среднее, и так далее. Признаков можно придумывать бесконечно много и бесконечно долго. Но что, если эту операцию автоматизировать? Для этих целей и создавалась замечательная библиотека tsfresh. В этой статье рассмотрим её использование для второго случая.
tsfresh — а вы и признаки за меня придумывать будете?
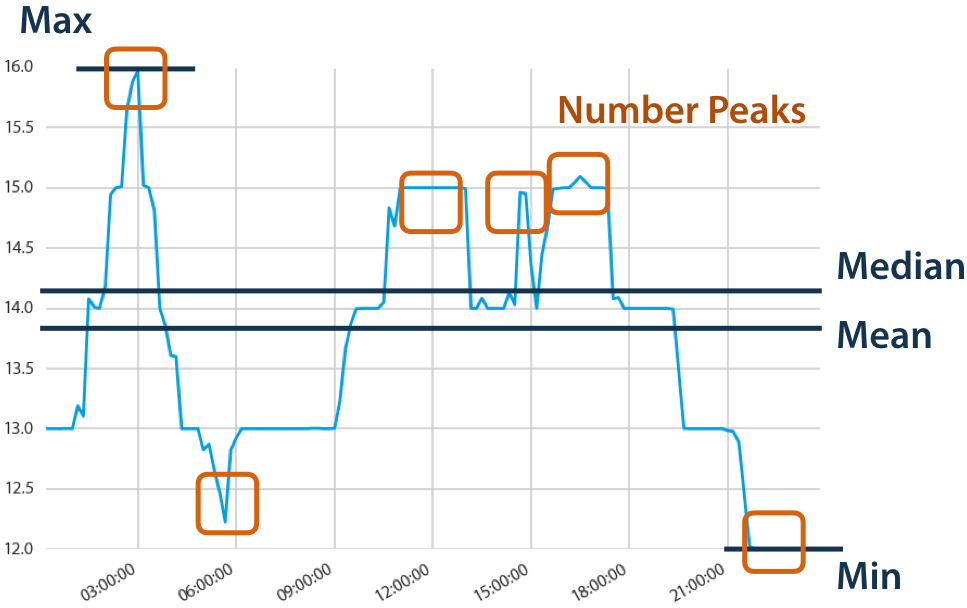
Основная идея библиотеки tsfresh — сгенерировать как можно больше признаков (если позволяют вычислительные ресурсы), а затем при помощи моделей или статистических критериев из этих признаков уже можно отобрать только те, которые релевантны для текущей задачи. Признаки могут быть как достаточно привычные — те же средние, максимальные и минимальные значения, так и довольно экзотичные, например, p-value коэффициента наклона линии тренда в текущем скользящем окне. Безусловно, не все эти признаки окажутся полезными (некоторые и вовсе могут оказаться константными), поэтому библиотека предоставляет небольшой инструментарий, который позволит быстро убрать самый откровенный мусор.
Давайте разберём всё на интересном примере — распознавании активности человека по данным акселерометра с мобильного телефона:
# импортируем необходимые функции из библиотеки from tsfresh.examples.har_dataset import download_har_dataset, load_har_dataset, load_har_classes from tsfresh import extract_features, extract_relevant_features, select_features from tsfresh.utilities.dataframe_functions import impute from tsfresh.feature_extraction import settings # для построения моделей воспользуемся sklearn from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns
Загрузим данные, которые удобно находятся в самой библиотеке. Суммарно у нас есть 7352 наблюдений, каждому из которых соответствуют 128 показаний акселерометра и одна из шести возможных активностей (подробное описание датасета можно найти здесь).
download_har_dataset() data = load_har_dataset() y = load_har_classes() print(data.shape) data.head()
Out[]: (7352, 128)
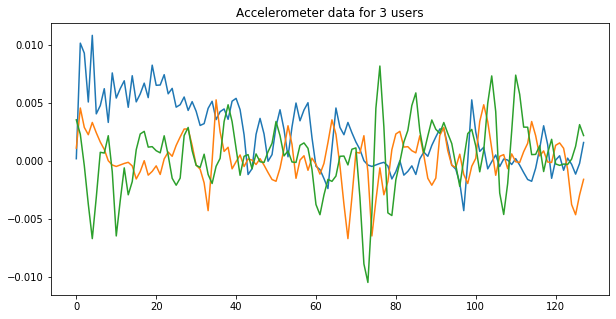
Если мы нарисуем первые несколько наблюдений, то заметим, что временные ряды действительно отличаются друг от друга, а значит, есть надежда выучить на них что-то полезное для предсказания активности.
Для начала, давайте обучим простую модель на сырых данных, т. е. возьмем все 128 наблюдений акселерометра и засунем их в качестве признаков в случайный лес с дефолтными значениями.
X_train, X_test, y_train, y_test = train_test_split(data, y, test_size=.2) cl = DecisionTreeClassifier() cl.fit(X_train, y_train) print(classification_report(y_test, cl.predict(X_test)))
Out[]: precision recall f1-score support 1 0.68 0.69 0.68 260 2 0.56 0.59 0.57 210 3 0.78 0.68 0.73 199 4 0.31 0.37 0.33 242 5 0.34 0.33 0.34 266 6 0.49 0.44 0.46 294 micro avg 0.51 0.51 0.51 1471 macro avg 0.53 0.52 0.52 1471 weighted avg 0.51 0.51 0.51 1471
В результате получили бейзлайн оценки качества для нашей многоклассовой классификации. Хорошо видно, что некоторые классы модель распознает с большей точностью, чем другие (обычно на этом датасете сложнее всего отличить сидячих от стоячих людей).
Раз бейзлайн на сырых признаках есть — настало время извлечь что-то поинтереснее!
В tsfresh есть различные предустановленные варианты извлечения признаков, которыми можно воспользоваться из коробки и особо не думать насчет содержания. Отличаются они лишь количеством рассчитываемых признаков, а значит, скоростью обработки данных и количеством информации, которую эти признаки смогут передать. При желании, можно также вручную изменять набор рассчитываемых признаков.
Первый и самый базовый набор признаков даёт
Обычно такие признаки не дают хорошего качества (всё-таки их не так много и они представляют собой лишь базовые статистики, описывающие распределение значений). Однако такой набор удобно использовать для прототипирования, построения бейзлайнов или в случае, когда получение других признаков занимает слишком много времени.
settings_minimal = settings.MinimalFCParameters() settings_minimal
Out[]: { 'sum_values': None, 'median': None, 'mean': None, 'length': None, 'standard_deviation': None, 'variance': None, 'maximum': None, 'minimum': None }
Теперь посмотрим, как можно скомбинировать несколько разных вариантов извлечения признаков. Добавим к текущему минимальному набору еще один —
settings_time = settings.TimeBasedFCParameters() settings_time.update(settings_minimal) settings_time
Out[]: {'linear_trend_timewise': [{'attr': 'pvalue'}, {'attr': 'rvalue'}, {'attr': 'intercept'}, {'attr': 'slope'}, {'attr': 'stderr'}], 'sum_values': None, 'median': None, 'mean': None, 'length': None, 'standard_deviation': None, 'variance': None, 'maximum': None, 'minimum': None}
Следующий набор —
settings_efficient = settings.EfficientFCParameters() settings_efficient
Out[]: {'variance_larger_than_standard_deviation': None, 'has_duplicate_max': None, 'has_duplicate_min': None, 'has_duplicate': None, 'sum_values': None, 'abs_energy': None, 'mean_abs_change': None, 'mean_change': None, 'mean_second_derivative_central': None, 'median': None, 'mean': None, 'length': None, 'standard_deviation': None, 'variance': None, 'skewness': None, 'kurtosis': None, ... }
Наконец, самый большой и полный вариант —
settings_comprehensive = settings.ComprehensiveFCParameters() len(settings_comprehensive)
Out[]: 64
Для текущего туториала, давайте возьмем эффективный список параметров и построим с его помощью наше новое признаковое пространство.
Для начала нужно преобразовать датасет в
data_long = pd.DataFrame({0: data.values.flatten(), 1: np.arange(data.shape[0]).repeat(data.shape[1])}) print(data_long.shape) data_long.head()
Out[]: (941056, 2)
В результате наш датасет удлинился практически до одного миллиона строк.
Извлекаем признаки при помощи
X = extract_features(data_long, column_id=1, impute_function=impute, default_fc_parameters=settings_efficient) print(X.shape)
Out[]: (7352, 788)
Спустя пять минут работы библиотеки получаем готовый датасет, где каждому наблюдению соответствуют уже не 128 сырых значений акселерометра, а 788 извлеченных признаков.
Попробуем теперь обучить модель на них!
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2) cl = DecisionTreeClassifier() cl.fit(X_train, y_train) print(classification_report(y_test, cl.predict(X_test)))
Out[]: precision recall f1-score support 1 0.91 0.90 0.90 245 2 0.80 0.85 0.82 217 3 0.92 0.86 0.89 214 4 0.40 0.40 0.40 275 5 0.49 0.46 0.48 257 6 0.55 0.58 0.57 263 micro avg 0.66 0.66 0.66 1471 macro avg 0.68 0.68 0.68 1471 weighted avg 0.66 0.66 0.66 1471
Ура, действительно, признаки оказались полезными и качество предсказаний заметно подросло по всем классам.
Но скорее всего, многие из извлеченных признаков на самом деле не нужны для построения предсказаний и могут быть спокойно выброшены. Для этого в библиотеке есть метод
relevant_features = set() for label in y.unique(): # select_features работает с бинарной классификацией, поэтому переводим задачу # в бинарную для каждого класса и повторяем по всем классам y_train_binary = y_train == label X_train_filtered = select_features(X_train, y_train_binary) relevant_features = relevant_features.union(set(X_train_filtered.columns)) len(relevant_features)
Out[]: 352
В результате получили заметно меньшей признаковое пространство, попробуем снова построить модель.
X_train_filtered = X_train[list(relevant_features)] X_test_filtered = X_test[list(relevant_features)] cl = DecisionTreeClassifier() cl.fit(X_train_filtered, y_train) print(classification_report(y_test, cl.predict(X_test_filtered)))
Out[]: precision recall f1-score support 1 0.92 0.93 0.93 245 2 0.83 0.87 0.85 217 3 0.92 0.86 0.89 214 4 0.41 0.40 0.41 275 5 0.45 0.47 0.46 257 6 0.58 0.57 0.57 263 micro avg 0.67 0.67 0.67 1471 macro avg 0.69 0.68 0.68 1471 weighted avg 0.67 0.67 0.67 1471
Отлично, отбросив мусорные признаки мы не только упростили модель, но еще и получили более высокое качество!
О других методах работы с временными рядами вы сможете узнать на занятиях "Анализ временных рядов" курса Machine Learning.