

Форматы файлов в больших данных: Parquet
Parquet представляет собой Open source-формат для Hadoop, который может хранить вложенные структуры данных в виде плоского столбчатого формата. Если сравнивать с обычным строчным подходом, то Parquet является более эффективным в плане хранения и производительности.
Однако давайте сделаем небольшую ремарку: для наилучшего понимания файлового формата Parquet в Hadoop надо взглянуть на столбчатый формат, то есть формат, основанный на столбцах. Дело в том, что в нем могут вместе храниться однотипные значения каждого столбца.
К примеру, наша запись включает такие поля, как ID, Name и Department. В данном случае все значения столбца ID станут храниться вместе, впрочем, так же, как и значения столбца Name, ну и т. д. Следовательно, таблица получит приблизительно следующий вид:
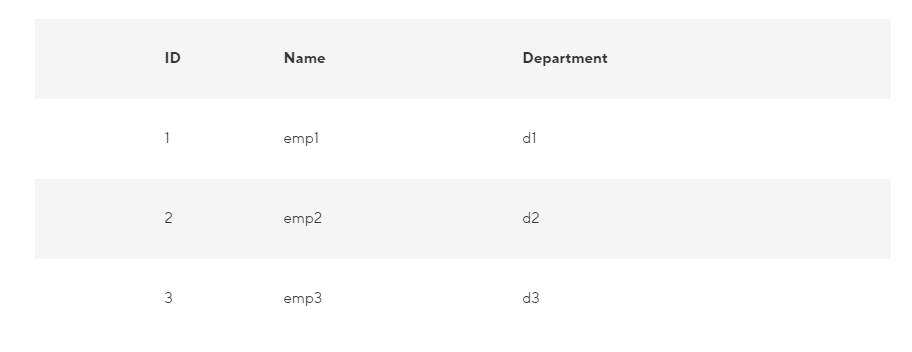
В строковом формате сохранение данных осуществляется следующим образом:

А вот, как обстоит дело в случае со столбчатым форматом файлов:

Таким образом, столбчатый формат будет более эффективным, если надо запрашивать из таблицы несколько столбцов. При использовании такого формата, будут считаны лишь нужные столбцы, т. к. они располагаются по соседству. Следовательно, операции ввода-вывода будут сведены к минимуму.
Представим, что нужен лишь столбец NAME. Если используется строковый формат, то каждую запись в наборе данных надо будет загрузить, разобрать по полям, а потом извлечь данные NAME. Столбчатый же формат позволит перейти непосредственно к столбцу Name, ведь все значения для него хранятся вместе. Следовательно, всю запись сканировать не потребуется.
Итак, столбчатый формат повысит производительность запросов, ведь для перехода к требуемым столбцам надо меньше времени на поиск. Также сокращается число операций ввода-вывода, так как происходит чтение лишь нужных столбцов.
У Parquet существует и уникальная особенность: способность хранить данные со вложенными структурами. К примеру, в файле Parquet даже вложенные поля вы сможете читать по отдельности, то есть нет необходимости считывать все поля во вложенной структуре. Что касается хранения вложенных структур, то здесь Parquet задействует алгоритм измельчения и сборки (shredding and assembly).
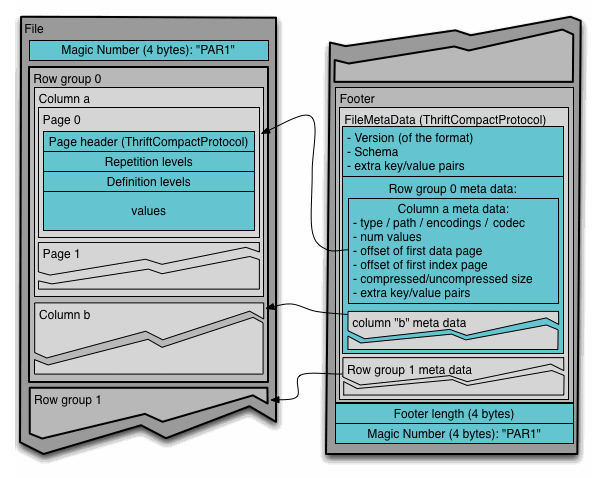
Для понимания формата файла Parquet в Hadoop, следует знать ряд терминов:
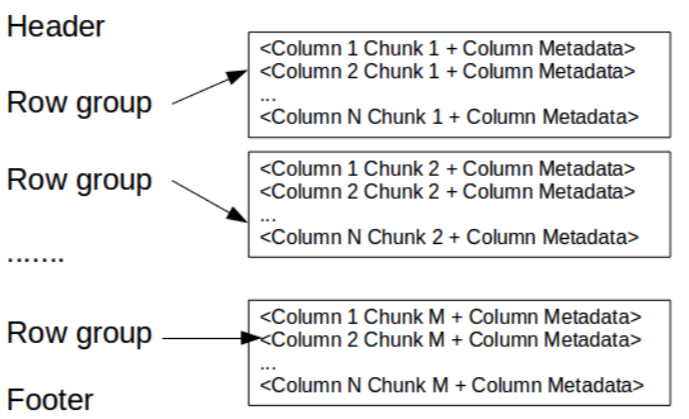
- Группа строк (row group). Речь идет о логическом горизонтальном разбиении данных на строки. При этом row group состоит из фрагмента каждого столбца в наборе данных.
- Фрагмент столбца (column chunk). В принципе, имеется в виду фрагмент конкретного столбца. Такие фрагменты столбцов "проживают" в определенной группе строк и гарантированно являются смежными в файле.
- Страница (page). Вышеописанные фрагменты столбцов делятся на страницы, которые записаны друг за другом. Страницы имеют общий заголовок, поэтому при чтении ненужные можно пропустить.
На картинке заголовок содержит волшебное число PAR1 (4 байта), идентифицирующее файл как файл Parquet-формата.
Осталось посмотреть, что записано в футере:

По материалам блога MCS.Mail.ru.