

Восстанавливаем данные с помощью k-NN
В одной из предыдущих статей мы рассматривали процесс импутации данных с помощью глубокого обучения. Однако восстановить значения в неполном наборе данных можно и с помощью алгоритма k-Nearest Neighbour. Давайте посмотрим, как это работает.
Итак, k-Nearest Neighbour (k ближайших соседей) — это относительно простой алгоритм классификации, который мы можем модифицировать в целях импутации недостающих значений. Алгоритм использует сходство точек для предсказания недостающих значений на основе k ближайших точек, у которых это значение присутствует. Говоря проще, происходит выбор k точек, которые наиболее похожи на рассматриваемую точку, а уже на их основании и происходит подбор значения для пустой ячейки в вашем неполном наборе данных.
Реализовать процесс можно посредством специальной библиотеки Impyute:
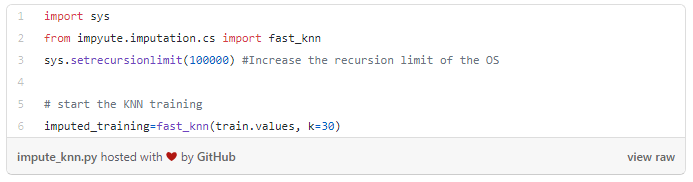
Сначала алгоритм выполняет импутацию простым средним способом, в результате чего он получает определенный набор данных. На основании его он строит дерево, а потом применяет это дерево при поиске ближайших соседей. При этом взвешенное среднее значений соседей и вставляется вместо недостающих значений в исходный набор данных.
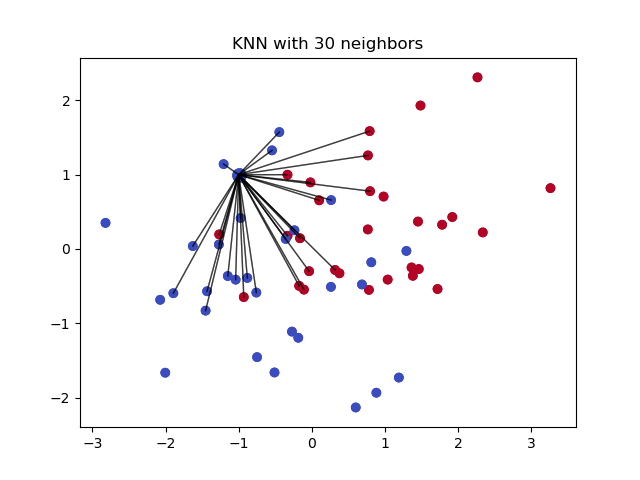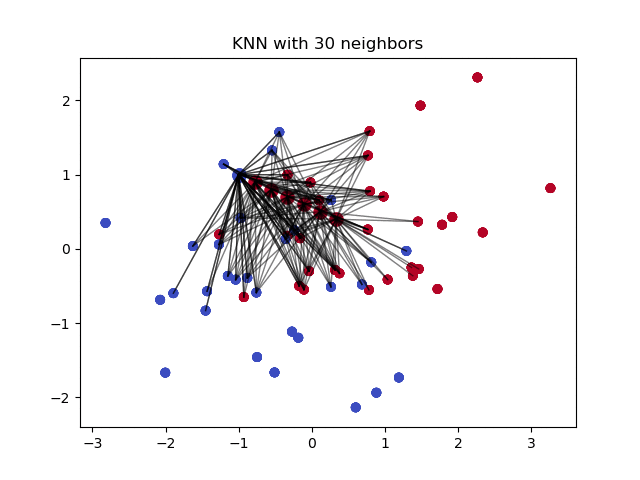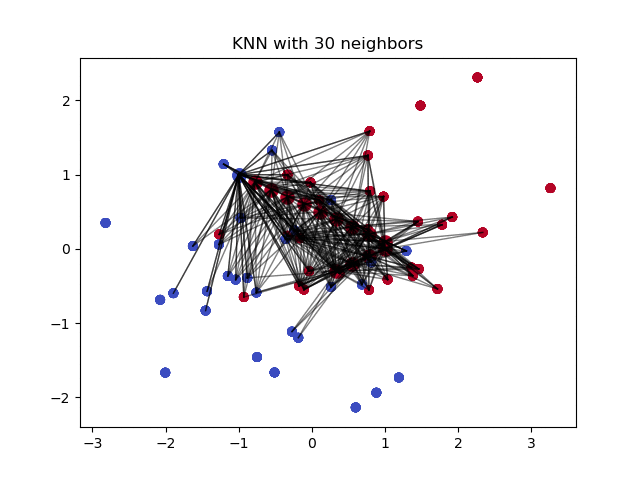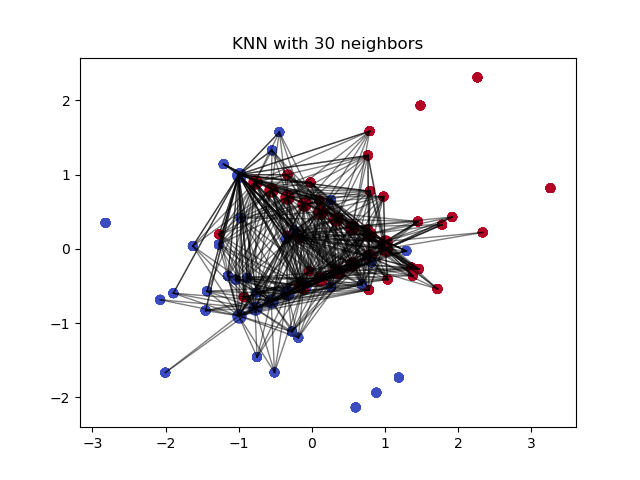
Преимущества и недостатки
У метода есть ряд плюсов: • на ряде датасетов алгоритм работает точнее, если сравнивать со способом константы либо среднего/медианы; • корреляция между параметрами учитывается.
К сожалению, минусы тоже имеются: • метод дороже с точки зрения вычислительного процесса, ведь надо держать в памяти весь набор данных; • надо всегда понимать, какая именно дистанционная метрика применяется при поиске соседей. Помните, что имплементация в impyute поддерживает лишь евклидову и манхэттенскую дистанцию, поэтому при анализе соотношений (к примеру, при анализе количества входов на веб-сайты людей различных возрастов) может потребоваться предварительная нормализация; • метод является чувствительным к выбросам в данных (в отличие, скажем, от того же SVM).
По материалам статьи «6 Different Ways to Compensate for Missing Values In a Dataset (Data Imputation with examples».