

Форматы файлов в больших данных: Avro
Для сериализации больших данных сегодня широко используют Avro — формат хранения данных в Hadoop, основанный на строках. Он позволяет хранить схему в JSON, что облегчает как ее чтение, так и ее интерпретацию любой программой. При этом сами данные размещаются в двоичном формате, что обеспечивает компактность и эффективность.
Сама по себе система сериализации Avro является нейтральной к языку программирования. Вы можете обрабатывать файлы с помощью C, C++, C#, Python, Java, Ruby.
Ключевая особенность Avro — надежная поддержка схем данных, меняющихся со времени, то есть данных, которые эволюционируют. Можно сказать, что Avro «понимает» изменения схемы, будь то удаление, добавление либо изменение полей.
Также Avro поддерживает различные структуры данных. К примеру, вы можете создать запись, содержащую массив, подзапись либо перечислимый тип.
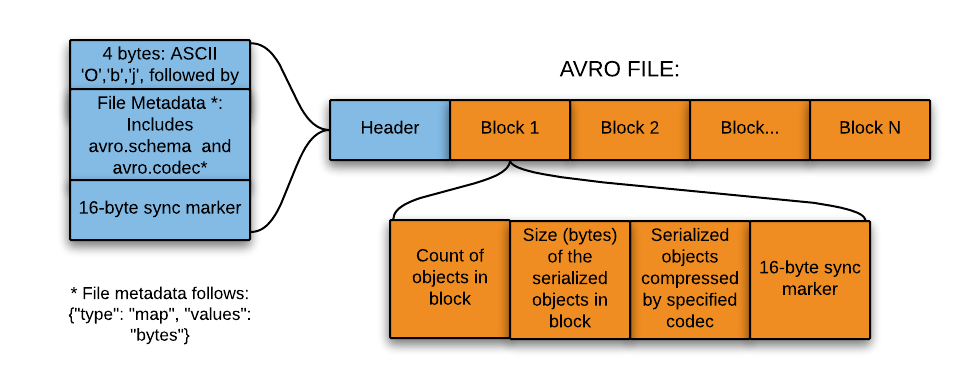
Данный формат отлично подходит для записи в посадочную зону озера данных (подробнее об озерах вы можете почитать здесь). При этом для записи в посадочную зону Data lake этот формат подходит не просто так, а по ряду причин: 1. Данные из этой зоны, как правило, считываются целиком в целях дальнейшей обработки нижестоящими системами. Так вот, формат на основе строк как раз таки здесь более эффективен. 2. Нижестоящие системы способны без проблем извлекать таблицы схем из файлов, так как нет необходимости в отдельном хранении схем во внешнем мета-хранилище. 3. Практически любое изменение исходной схемы обрабатывается легко (речь идет о так называемой эволюции схемы).
В следующий раз поговорим о других форматах файлов, используемых в Big Data. Следите за новостями!
По материалам блога MCS.Mail.ru.