

Percona XtraDB Cluster with ProxySQL

Одно из определений кластера гласит: «Кластер это группа серверов, объединённых логически, способных обрабатывать идентичные запросы и использующихся как единый ресурс». Это значит, что мы объединяем несколько sql-серверов в единую структуру, которая функционирует, как единое целое.
Можно выделить несколько основных преимуществ кластера: 1. Отказоустойчивость. Если в нашем кластере 5 нод, то мы вполне можем продолжать работать даже на 3х нодах; 2. Сохранность данных. Хотя бы одна нода будет содержать максимально актуальную версию данных. Потеря данных всё ещё возможна, но при этом мы потеряем данные не от момента сбоя до последней резервной копии, а только некоторую разницу в данных между моментом сбоя и нормальным состоянием.
Стоит отметить, что само резервное копирование по-прежнему необходимо, так как только оно спасёт нас от порчи/искажения данных случайно или преднамеренно.
Схемы кластеров
Имеются следующие схемы построения кластеров:
1. Мастер-слейв. В данном случае мы можем читать с любой ноды, но писать только на одну.
 2. Мультимастер (мастер-мастер). В данном случае возможны чтение/запись на любую ноду.
2. Мультимастер (мастер-мастер). В данном случае возможны чтение/запись на любую ноду.
 В ряде случаев между приложением (сервисом) ставится прокси (HAProxy, ProxySQL). Их наличие позволяет балансировать нагрузку, кешировать запросы, реализовывать отказоустойчивость.
В ряде случаев между приложением (сервисом) ставится прокси (HAProxy, ProxySQL). Их наличие позволяет балансировать нагрузку, кешировать запросы, реализовывать отказоустойчивость.
Percona XtraDB Cluster with ProxySQL
Данный кластер представляет собой несколько нод в мульти-мастер режиме. Подключение к ним осуществляется через ProxySQL-сервер, который является высокопроизводительным SQL-прокси.
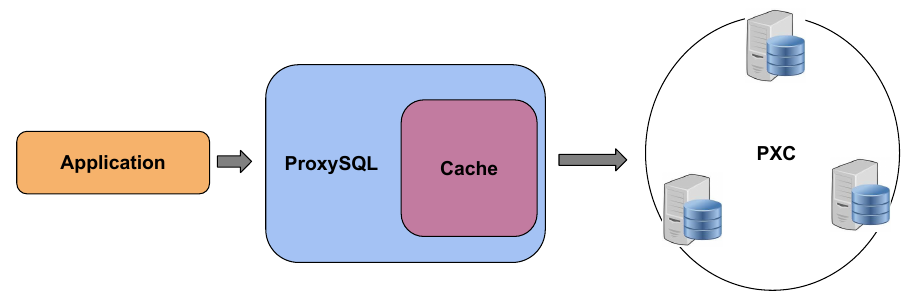 Данная схема даёт нам ряд преимуществ:
— кеширование запросов;
— маршрутизация запросов;
— поддержка отказоустойчивости;
— изменение настроек на лету без простоя.
Данная схема даёт нам ряд преимуществ:
— кеширование запросов;
— маршрутизация запросов;
— поддержка отказоустойчивости;
— изменение настроек на лету без простоя.
Подготовка и запуск
В одном из проектов возникла необходимость в MySQL-кластере. За основу был взят Percona XtraDB Cluster, который будет запускаться в Docker’е. Имеющийся в Docker Hub официальный image состоит из трёх контейнеров (нода в терминах Percon’ы): где запущена сама Percona, контейнер с Discovery-сервисом и контейнер с ProxySQL, к которому и будет подключаться приложение.
В боевых условиях у нас возможно появление новых нод или уменьшение их количества ниже некоторого критического, поэтому нам необходимо отслеживать состояние нашего кластера.
Для запуска контейнеров перкона кластера воспользуемся образами из официального докер-хаба:
И третий необходимый образ это ProxySQL:
В скрипты, находящиеся в этом образе, нам и необходимо внести изменения. Данные изменения должны решать следующие задачи: 1. ожидание готовности самого ProxySQL; 2. автоматическое добавление нод; 3. мониторинг количества нод.
Клонируем официальный репозиторий. В нём содержатся файлы:
—
Изменяем proxysql-entry.sh
добавляем запуск скрипта добавления нод:
#!/bin/bash if [ -z "$CLUSTER_NAME" ]; then echo >&2 'Error: You need to specify CLUSTER_NAME' exit 1 fi if [ -z "$DISCOVERY_SERVICE" ]; then echo >&2 'Error: You need to specify DISCOVERY_SERVICE' exit 1 fi # Starting add_nodes /usr/bin/add_cluster_nodes.sh& /usr/bin/proxysql --initial -f -c /etc/proxysql.cnf
Изменяем add_cluster_nodes.sh
Добавим функцию ожидания готовности самого ProxySQL:
waiting_proxysql() { status=255 while [ $status -gt 0 ]; do echo Waiting proxysql sleep 2s `2>/dev/null echo "" > /dev/tcp/127.0.0.1/6032 || exit 1` status=$? done }
И добавим функцию ожидания Discovery-сервиса:
waiting_discovery_service() { status=255 while [ $status -gt 0 ]; do echo Waiting discovery service sleep 2s status=$(curl -s $DISCOVERY_SERVICE 2>/dev/null 1>/dev/null; \ echo $?) done return $(curl -s \ http://$DISCOVERY_SERVICE/v2/keys/pxc-cluster/$CLUSTER_NAME/ |\ jq -r '.node.nodes[]?.key' | awk -F'/' '{print $(NF)}' | wc -l) }
Необходимо заметить, что эта функция, помимо ожидания готовности, возвращает количество зарегистрированных нод на сервисе. Таким образом скрипт
#!/bin/bash ipaddr=$(hostname -i | awk ' { print $1 } ') if [ -z "$REFRESH_INTERVAL" ]; then export REFRESH_INTERVAL=1m fi if [ -z "$NODE_COUNT" ]; then export NODE_COUNT=3 fi waiting_proxysql() { status=255 while [ $status -gt 0 ]; do echo Waiting proxysql sleep 2s `2>/dev/null echo "" > /dev/tcp/127.0.0.1/6032 || exit 1` status=$? done } waiting_discovery_service() { status=255 while [ $status -gt 0 ]; do echo Waiting discovery service sleep 2s status=$(curl -s $DISCOVERY_SERVICE 2>/dev/null 1>/dev/null; \ echo $?) done return $(curl -s \ http://$DISCOVERY_SERVICE/v2/keys/pxc-cluster/$CLUSTER_NAME/ |\ jq -r '.node.nodes[]?.key' | awk -F'/' '{print $(NF)}' | wc -l) } add_nodes() { for i in $(curl http://$DISCOVERY_SERVICE/v2/keys/pxc-cluster/$CLUSTER_NAME/ |\ jq -r '.node.nodes[]?.key' | awk -F'/' '{print $(NF)}') do echo $i mysql -h $i -uroot -p$MYSQL_ROOT_PASSWORD \ -e "GRANT ALL ON *.* TO '$MYSQL_PROXY_USER'@'$ipaddr' IDENTIFIED BY '$MYSQL_PROXY_PASSWORD'" mysql -h 127.0.0.1 -P6032 -uadmin -padmin \ -e "INSERT INTO mysql_servers (hostgroup_id, hostname, port, max_replication_lag) VALUES (0, '$i', 3306, 20);" done mysql -h 127.0.0.1 -P6032 -uadmin -padmin \ -e "INSERT INTO mysql_users (username, password, active, default_hostgroup, max_connections) VALUES ('$MYSQL_PROXY_USER', '$MYSQL_PROXY_PASSWORD',1, 0, 200);" mysql -h 127.0.0.1 -P6032 -uadmin -padmin \ -e "LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; LOAD MYSQL USERS TO RUNTIME; SAVE MYSQL USERS TO DISK;" } # refreshing nodes while [ 0 -eq 0 ] ; do waiting_proxysql nodes=0 while [ $nodes -lt $NODE_COUNT ]; do waiting_discovery_service nodes=$? done add_nodes #echo waiting next update sleep $REFRESH_INTERVAL done
Через переменные окружения
Настраиваем развертывание
Финальный версия
version: '3.1' services: # ProxySQL service proxy: # image image: perconalab/proxysql # network networks: - galera # Forwarded ports ports: # SQL-connection - "3306:3306" # ProxySQL administration connection - "6032:6032" env_file: proxysql.env # Modified scripts volumes: - ./add_cluster_nodes.sh:/usr/bin/add_cluster_nodes.sh - ./proxysql-entry.sh:/entrypoint.sh deploy: mode: replicated replicas: 1 labels: [APP=proxysql] # service restart policy restart_policy: condition: on-failure delay: 5s max_attempts: 3 window: 120s # service update configuration update_config: parallelism: 1 delay: 10s failure_action: continue monitor: 60s max_failure_ratio: 0.3 placement: constraints: [node.role == manager] # Discovery service galera_etcd: image: quay.io/coreos/etcd command: etcd volumes: - /etc/ssl/certs:/etc/ssl/certs env_file: etcd.env networks: - galera deploy: mode: replicated replicas: 1 placement: constraints: [node.role == manager] # Percona xtradb cluster nodes percona-xtradb-cluster: image: percona/percona-xtradb-cluster:5.7 networks: - galera env_file: galera.env deploy: mode: global labels: [APP=pxc] # service restart policy restart_policy: condition: on-failure delay: 5s max_attempts: 3 window: 120s # service update configuration update_config: parallelism: 1 delay: 10s failure_action: continue monitor: 60s max_failure_ratio: 0.3 networks: # Network for communication between nodes galera: # Use a custom driver driver: overlay internal: true ipam: driver: default config: - subnet: 10.20.1.0/24
При помощи опции
Для запуска нашего кластера необходим предварительно созданный swarm-кластер. На leader-node выполняем
Полный пример можно найти по ссылке.
Есть вопрос? Напишите в комментариях!