

Как работают ndarray в Numpy?

Многие знают, что Numpy классный и замечательный. А его ndarray позволяют не только удобно обращаться с данными, но также делают это крайне производительно. За счёт чего?
Для начала заметим, что ndarray не то же самое, что класс array стандартной библиотеки Python, который используется только для одномерных массивов.
Наиболее важные атрибуты объектов ndarray (выдернул с Хабра):
ndarray.ndim — число осей (измерений) массива. В мире Python число измерений часто называют рангом.
ndarray.shape — размеры массива, его форма. Это кортеж натуральных чисел, показывающий длину массива по каждой оси. Для матрицы из «n» строк и «m» столбов, shape будет (n,m). Число элементов кортежа shape равно рангу массива, то есть ndim.
ndarray.size — число всех элементов массива. Равно произведению всех элементов атрибута shape.
ndarray.dtype — объект, описывающий тип элементов массива. Можно определить dtype, используя стандартные типы данных Python. NumPy здесь предоставляет целый букет возможностей, например: bool_, character, int_, int8, int16, int32, int64, float_, float8, float16, float32, float64, complex_, complex64, object_.
ndarray.itemsize — размер каждого элемента массива в байтах. Например, для массива из элементов типа float64 значение itemsize равно 8 (=64/8), а для complex32 этот атрибут равен 4 (=32/8).
ndarray.data — буфер, содержащий фактические элементы массива. Обычно нам не будет нужно использовать этот атрибут, потому как мы будем обращаться к элементам массива с помощью индексов.
Почему же ndarray так производительны?
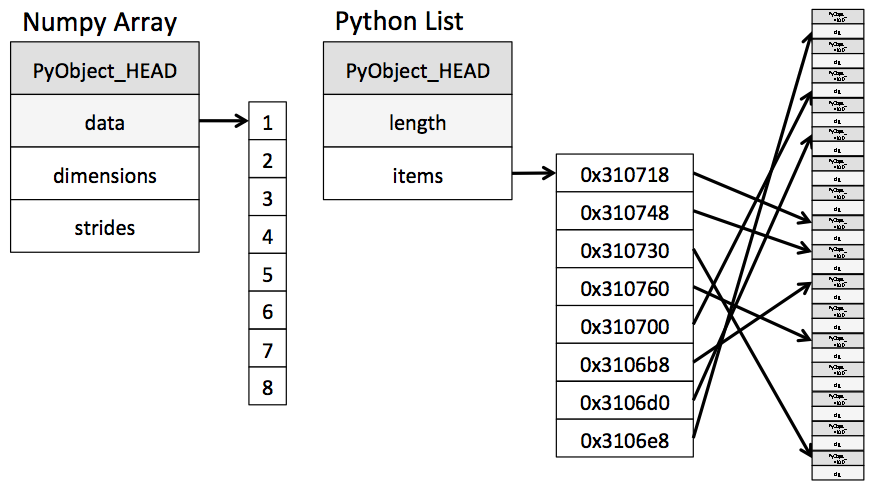 Дело, в том числе, в особенной структуре хранения данных. Обычные списки в Python хранят указатели на объекты, внутри которых есть указатели на их типы. Таким образом, чтобы прочитать что-то из списка нужно «скакать» по памяти. Numpy-массивы хранят указатель на кусок память, где лежат все данные, плюс метаинформацию об этих данных: типа, размерность и т.д. Тогда, при последовательном обращении к элементам массива эффективно используется кэш процессора, что позволяет снизить количество кэш-промахов, так как работает механизм предвыборки (prefetching).
Дело, в том числе, в особенной структуре хранения данных. Обычные списки в Python хранят указатели на объекты, внутри которых есть указатели на их типы. Таким образом, чтобы прочитать что-то из списка нужно «скакать» по памяти. Numpy-массивы хранят указатель на кусок память, где лежат все данные, плюс метаинформацию об этих данных: типа, размерность и т.д. Тогда, при последовательном обращении к элементам массива эффективно используется кэш процессора, что позволяет снизить количество кэш-промахов, так как работает механизм предвыборки (prefetching).
Также Numpy обеспечивает «векторизацию» операций над своими массивами. Он выполняет их на уровне С-кода, который, в свою очередь, использует структуру хранения, описанную выше, умнее.
Но и это еще не всё! Многие операции с массивами, такие как resizing, slicing и т.д., не копируют данные, на которые ссылается массив, а лишь изменяют хранящуюся рядом метаинформацию, обеспечивая другой view на те же самые данные.
Есть вопрос? Напишите в комментариях!