

Выделяем сущности и факты с NLP
Как известно, NLP применяется для машинного перевода, текстового анализа, синтеза и распознавания речи, разработки диалоговых систем. Кроме этого, популярной задачей NLP является NER -- извлечение именованных сущностей из текста (Named-entity recognition). Что это значит? Рассмотрим на примерах.
Пример № 1
Представьте, что у вас есть сплошной текст, посвященный покупке/продаже активов. Вам поставлена задача: выделить из текста даты, активы и существующие персоны.
Текст может иметь такой вид:

В нашем случае задачей выделения сущностей и фактов будет понимание системой того, что участок текста «1999 года» -- это дата, «Иван Петров» — это персона, «пакет акций» — это, соответственно, актив.
Собственно говоря, без NER относительно сложно представить решение многих NLP-задач, того же построения вопросно-ответных систем или разрешения местоименных анафор. В частности, схожий механизм используется в анализе поисковых фраз. Например, набрав запрос «Кто играл роль царя в кинофильме “Иван Васильевич меняет профессию”», ответ будет формироваться как раз таки на основании выделения именованных сущностей: (фильм, роль и так далее), то есть сначала формируется "понимание", что именно спрашивается, а уже потом происходит поиск ответа в базе данных.

Вообще, постановка NER-задачи характеризуется высокой степенью гибкости. Мы можем выделять любые необходимые непрерывные фрагменты текста, чем-то непохожие на весь остальной текст. В итоге подбирается набор сущностей для конкретной практической задачи. Далее останется лишь обработать тексты этим набором, а потом обучить модель. Вышеописанный алгоритм используется повсеместно, что делает NER, по сути, одной из наиболее часто встречаемых и решаемых NLP-задач в индустрии.
Пример № 2
Ниже -- подобный проект, разработанный для крупной энергетической компании. Заказчик хотел подготовить данные об активах: средствах контроля и измерения, эксплуатируемом оборудовании, промышленных установках. В качестве источников данных послужили текстовые документы -- в реальности это были техрегламенты, максимально подробно описывающие технологические процессы и интересующие производственные объекты.
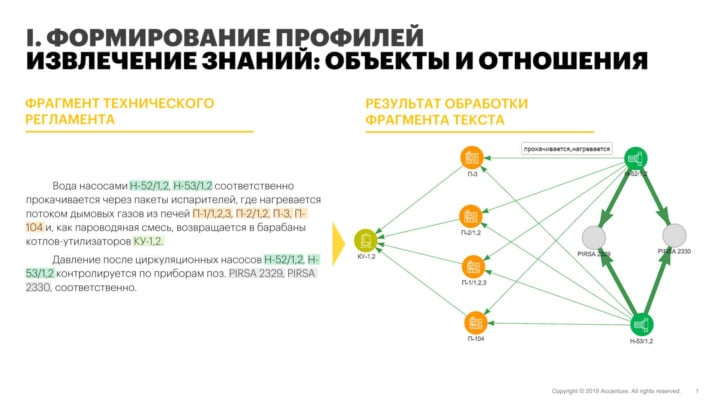
В результате исполнитель продемонстрировал возможность применения Machine Learning- и NLP-технологий для извлечения нужной информации из текстового описания с последующим формированием профилей оборудования на основе полученных данных. После сопоставления сформированных профилей с результатами ручного маппинга, который взяли за эталон, достигнутая точность составила 97,3 %. При этом, в отличие от ручного маппинга, NER позволил:
- значительно снизить затраты труда и времени;
- минимизировать риски, которые связаны с ошибками при ручной обработки текстов.

По материалам https://tproger.ru.
P. S. Желаете освоить современные NLP-технологии? Добро пожаловать на авторский курс от Otus!