

Библиотеки по анализу данных: scikit-learn
Как известно, Python считается одним из наиболее подходящих языков для системного анализа, Machine learning, статистики, прогнозной аналитики и других задач, связанных с обработкой данных. Чтобы выполнять этот анализ эффективно, используют специализированные библиотеки: NumPy, Pandas, Matplotlib. Сегодня поговорим про scikit-learn.

На практике scikit-learn больше подходит для машинного обучение, хотя успешно используется и для прогнозной аналитики. Библиотека включает в себя ряд методов, которые, по сути, охватывают все, что вам может понадобиться на протяжении первых нескольких лет в карьере аналитика данных, а именно:
- алгоритмы регрессии и классификации,
- валидацию,
- кластеризацию,
- выбор моделей.
Кроме вышесказанного, вы можете применять scikit-learn в целях выделения признаков и уменьшения размерности данных.
Пример, как в scikit-learn может выглядеть простейшая классификация с применением модели «случайный лес» представлен ниже:
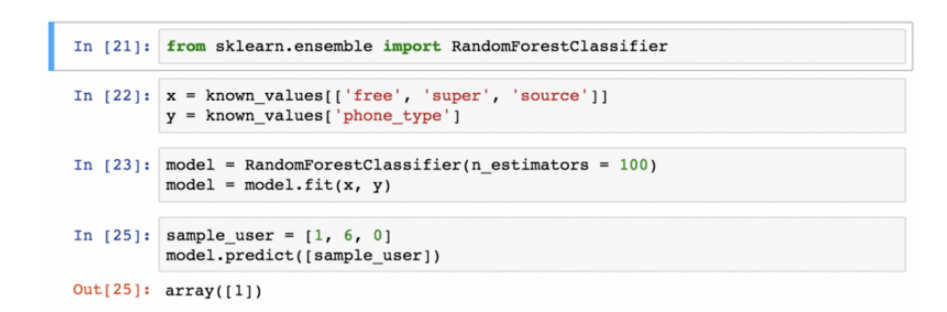
Что касается машинного обучение, то оно в scikit-learn заключается, преимущественно, в импорте правильных модулей и запуске метода подбора модели. Но если речь идет о вычистке, форматировании и подготовке данных с подбором модели на основе оптимальных входных значений, то все становится сложнее. То есть надо понимать, что для эффективного использования этой библиотеки будет нелишним отработать приемы работы с Python и Pandas, что даст вам возможность получить навыки качественной подготовки данных -- это во-первых. Во-вторых, вы освоите как теорию, так и крепкую математическую основу разных моделей классификации и прогнозирования, что, в свою очередь, обеспечит понимание, что именно происходит с данными.
Хотите знать про инструменты системного анализа больше? Обратите внимание на курс "Системный аналитик. Advanced"!