

Стенд для нагрузочного тестирования: от DEV до PROD
В этой статье я попробовал обобщить личный опыт последних лет, успехи прорыва в результативности тестов и, соответственно, в повышении производительности, которого мы смогли достичь в компании за последнее время.
Договоримся о терминологии
- НТ — нагрузочное тестирование, для меня это синоним тестирования производительности. В НТ входят всевозможные подвиды тестов, направленные на проверку показателей производительности системы: время отклика, пропускная способность, % успешных операций или доступность, утилизация ресурсов.
- Максимальная производительность — уровень пропускной способности системы, после которого система перестаёт удовлетворять предъявленным к ней требованиям — по времени отклика, доступности, утилизации ресурсов.
- Тест определения максимальной производительности — ступенчатое повышение нагрузки на систему до достижения этого самого уровня.
Как у нас организована нагрузка
Инструменты:
- Основной – Gatling
- Протоколы – наиболее часто это REST-ы и web по http, бывают и скрипты нагрузки на БД / очереди
- Запуск тестов в Jenkins
- Мониторинг в Grafana + Clickhouse
- Для мониторинга генераторов нагрузки — Prometheus
- Redis и Postgres для хранения тестовых данных, FTP для больших файлов
В общем, всё как у взрослых людей. В следующих статьях расскажем об этом подробнее, если интересно. А сейчас едем дальше.
3+ регулярно нагружаемые крупные системы:
- Единый портал государственных услуг (ЕПГУ)
- Единая система идентификации и аутентификации (ЕСИА)
- Система межведомственного электронного взаимодействия (СМЭВ, шина данных)
- …и еще с десяток периодически нагружаемых прикладных систем и сервисов
Основные типы тестов:
- Проверка стабильной нагрузки — короткий тест с заданным tps
- Стресс-тесты — проверка работы под большой нагрузкой в течение короткого времени
- Классическая максимальная производительность
Команда инженеров:
1 лид и 4 нагрузочника разного опыта и происхождения, со средним опытом в НТ = ~3 года
Вернемся к нагрузочным стендам
Разделим типы стендов на несколько категорий и поймём, что же можно на них тестировать и какие риски / ограничения нужно держать в уме:
- DEV — стенд разработки
- UAT — стенд регрессионного функционального тестирования
- LT — отдельный стенд нагрузочного тестирования
- PROD — стенд на базе инфраструктуры Продуктивного контура
Каждый опишем с нескольких сторон по такой схеме:
- Summary — короткое резюме от меня
- Жиза — как мы используем этот стенд
- Что можно — какие тесты можно проводить
- Команда — кто здесь понадобится нагрузочнику, насколько самостоятельно выполнение тестов
- Pros and cons — основные + / -
- Advice — совет напоследок обзора стенда
DEV - место бурлящей жизни и регулярной поломки разработчиками
Summary: Отличное место для нагрузки пилотных решений или новых микросервисов, но задержаться на нём для исследований бывает сложно. Особенно, если архитектура монолитная.
Жиза: Не самый активный стенд именно для нагрузки, но супер-массовые новые сервисы сначала тестим здесь — социальные выплаты, сервисы для выборов, онлайн-запись в школы. Конечно же, в микросервисах, особенно часто в кубере. Здесь не проверить какой-нибудь scaling, но 50-70% проблем на данном стенде мы закрывали, хоть пользовались им не так часто, как стоило бы.
Отступление в рамках темы Отдельного внимания здесь в описании DEV заслуживает наше детище для Системы межведомственного электронного взаимодействия (СМЭВ). Изначально мы планировали собрать стенд LT, но заказчики-разработчики пожелали проверять новые решения и тюнинг/рефакторинг старых здесь и сейчас. У нас вышел эдакий Монстр, которого мы прозвали DEV-LT! По необходимости могли и мощностей накинуть для достижения нужных цифр, но и не ждали отлаженных новых релизов и прочих pipeline-ов для проверки разных гипотез.
В итоге за пару месяцев мы протестили отказоустойчивость при отключении разных сервисов системы, протюнили с десяток компонент и повысили общую производительность системы раза в три (с учётом пост-тестов на других стендах, конечно же). Это был суровый марафон, но глаза горели у всех!
Что можно: стресс-тесты и общая максимальная производительность всего комплекса здесь бессмысленны. Только точечный тюнинг и проверка отдельных компонентов тестами со стабильными потоками (количество открытых соединений / thread-ов) или подачей стабильной нагрузки.
Команда: Если времени мало, то практически в онлайне с разработчиком. Если побольше — в режиме чатика. Очень удобно поработать devops-ом: сделать «кнопку» для разработчика и дать ему «пофрустрировать» самому до желаемого результата. Не забудьте про мониторинг, чтобы он получал удовольствие! Главное вовремя остановить, не доводить до уровня «хочу 100к tps выжать, 12 ночи всего, запускаю ещё тест!»
Pros and cons:
+ экономит время тюнинга на поздних этапах, что особенно актуально для багов по производительности (все мы знаем, они бывают ОЧЕНЬ дорогими) + можно запускать «на коленке» и получать реальный value – не подходит для основательных выводов по максималке / не применить к PROD — нужны дополнительные тесты на других контурах – стенд обычно шаток и разработчики любят его ломать, а иногда его потом сложно восстановить – сложно с тестированием интеграций, DEV, как правило, изолирован
Advice: Совет подойдёт и для других стендов — «одно изменение за раз!». Разработчики любят побежать азартно вперёд, и применить много «оптимизаций» между тестами за один раз. Потом приходится часто искать, что именно улучшило или ухудшило производительность. Поэтому лучше стараться делать одно улучшение/изменение за раз и оценивать тестом, хотя бы коротким.
UAT (стенд регрессионного функционального тестирования) — относительно стабильный контур по сборкам, но слабый по железу

Summary: Как и для ФТ — хороший стенд для проверки новых релизов по старой функциональности (применимо и для НТ). Так и хочется добавить к нему железа, и пусть весь мир (другие стенды) подождут. Но в итоге тестов будет ждать и остальная команда.
Жиза: С этого стенда мы начинали в РТЛабс проводить регулярное НТ — в данном случае проверка релизов на не-ухудшение производительности. В частности, на небольшом железе мы сравниваем «выдерживание» ступени стабильной нагрузки по основным показателям производительности. Дефектов обычно находится не так много, как хотелось бы, потому что у этого стенда всегда много «но» по сравнению с PROD. И это несмотря на то, что по конфигурации компонентов он к нему ближе, чем любой другой.
Что можно: Лучше проводить тесты стабильной нагрузки 10-60 минут. Длительность зависит от вашей ступени стабильной нагрузки, за которую вы сможете адекватно оценить показатели производительности. Если у вас быстрая система с 100-500+ tps и временем отклика в пределах секунды (шина данных, например), то хватит и коротких тестов. Если что-то пользовательское с множеством сценариев — лучше погонять подольше и заодно оценить надежность.
Команда: Как правило, лучший друг нагрузочника — это функциональщик. В данном случае вдвойне, так как это его стенд! Он подскажет, когда и сборка более-менее стабильна и когда можно поломать стенд тестами. С дефектами тут сложнее, чем на DEV — у нас по крайней мере были наводки и на инфраструктурные сбои, а разбор может быть не таким быстрым, как хотелось бы.
Pros and cons:
+ хороший стенд для старта нагрузочного тестирования в плане стабильности и отладки (в том числе на новых готовящихся версиях системы). И для того, чтобы потом куда-то переезжать с тестами на другие стенды + обычно неплохая поддержка со стороны ФТ и сопровождения, так как релизы должны ехать в PROD без простоев. А вы, в том числе, занимаете время подготовки релиза :) – придётся выбирать время для тестов, чтобы не мешать ФТ – сильную нагрузку целиком на систему не подать ввиду слабости стенда по железу, то есть сложно оценить максимальную производительность в целом
Advice: Не убивайте стенд, пожалейте функциональщиков! Не только проведением нагрузки днём, но и забиванием БД тестовыми или созданными в тестах данными. Проработайте процедуры очистки.
LT (отдельный стенд нагрузочного тестирования)
На какой хватит средств какой построите, такой и будет! Но в любом случае он лучше остальных стендов, потому что СВОЙ.
Summary: Здесь всё понятно — идеальный стенд практически для любых целей НТ. Не надо сидеть по ночам / ждать пока он освободится (в пределах одной тестируемой системы, конечно). В некоторых банках даже построили интеграционные стенды НТ. Правда пока я не видел стенд, выдерживающий 100% нагрузку по профилю с Прода, со всех каналов-систем.
Жиза: Выше я рассказывал о том, как мы применяем стенд DEV-LT. Пока мы видим неплохую пользу в совмещении целей для этого контура с учетом имеющейся инфраструктуры PROD для больших тестов (об этом ниже).
Из опыта других компаний могу сказать, что отдельный контур это действительно долго, дорого и замечательно. Причём для стабильного стенда крупной системы «долго» — это скорее всего минимум год, а «дорого» — не только закупка оборудования, но ещё и отдельная команда админов разного профиля. Ведь у вас небольшой PROD, а значит нужны инженеры СПО, ППО, DBA и т.д.
При этом на других стендах можно и нужно ловить 80-90% проблем. Это значит, что в микросервисной архитектуре огромные стенды становятся всё менее полезными.
Что можно: ВСЁ. Ну, правда. Интеграционные нагрузочные тесты можно проводить с эмуляторами, хорошо идут регрессионные тесты, стресс-тест/максималка/надежность/отказоустойчивость и любые другие, которые вы ещё себе придумаете между релизами.
Команда: Если хотите работать эффективно, а не чинить стенд неделями, когда ребята с PROD / тестовых контуров смогут уделить вам время, то только отдельная команда. Если стенд небольшой, можно не выделять отдельно системных администраторов / DBA на задачи одного этого стенда. Но инженеры ППО точно нужны — системы нужно и поднимать с нуля и поддерживать (поднимать) после регулярных тестов и релизов, которые будут их ломать.
Pros and cons:
+ подходит для всех нужных нагрузочных тестов (с интеграционным НТ может быть сложно, но возможно!) + не нужно ждать очередь на стенд, есть время для улучшений / экспериментов + можно готовить нужные наборы тестовых данных, тестировать объемы – дорого и долго — и по подготовке железа, и в поддержке – команде сопровождения нужно долго набираться опыта – бывает сложно отслеживать все изменения на PROD / тестовых контурах, чтобы тестовый стенд НТ был актуален
Advice: Не надейтесь, что стенд НТ взлетит быстро, особенно если команда собирается с нуля. Исключения — небольшие и простые системы, по ним и PROD просто и быстро собрать.
И раз уж у вас отдельный стенд — пробивайте получение копии БД с PROD (урезанной, обезличенной), это повысит качество тестирования.
Ещё совет— не делайте прогнозирование / домножение результатов, полученных на стенде НТ, для PROD, если у вас LT сильно меньше по ресурсам. Горизонтальное масштабирование — непростая штука. Да простят меня мастера-архитекторы – иногда позволяю себе «умножить на 2» производительность, полученную на стенде НТ, который в 2 раза слабее Прода по ресурсам, при микросервисной архитектуре и не загруженности всех узлов по метрикам серверов. Можно предположить, что на Прод будет не хуже.
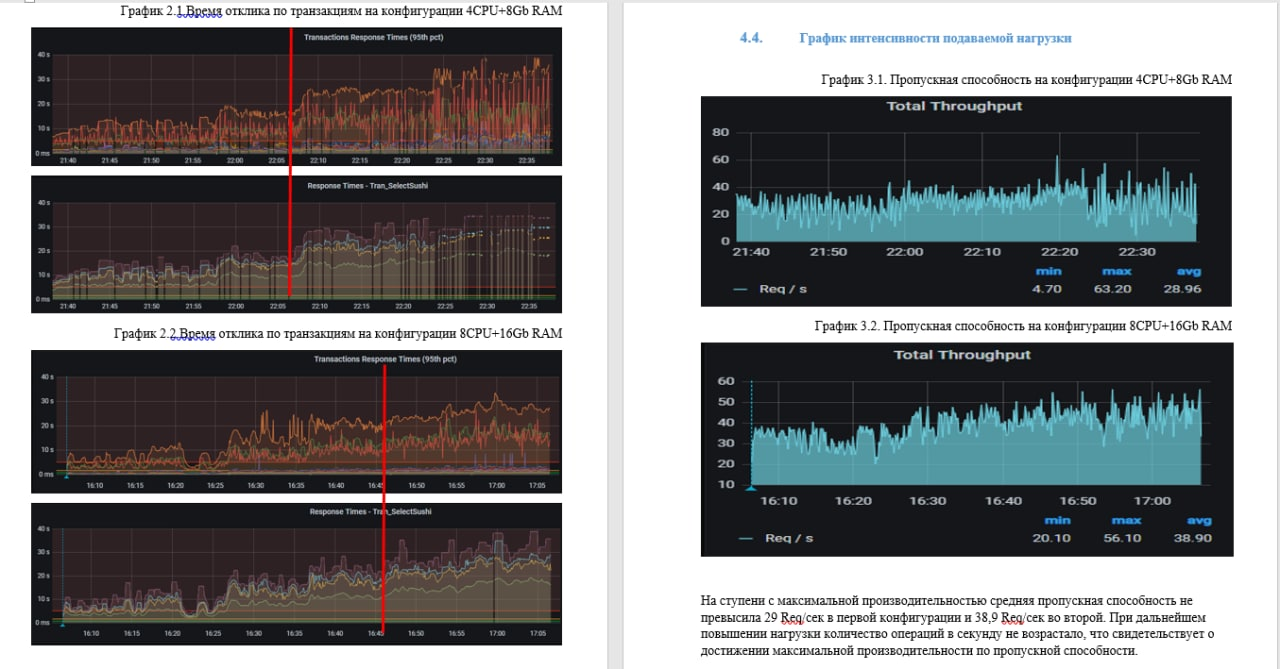
Сравнение производительности простой web-ки на node.js при увеличении ресурсов машины в 2 раза.
Как-то студенты курса по НТ проводили простой эксперимент по оценке влияния повышения ресурсов сервера, на котором крутилась простая веб-страничка c node.js под капотом, практически ничего не делающая. Результат налицо. Теперь храню эту картинку и показываю всем, кто любит «умножать на 10».
PROD (стенд на базе инфраструктуры Продуктивного контура) – опасно, но крайне эффективно

Summary: Мало кто вас сюда пустит. Но если пустит — польза не только в качестве достоверных результатов, но и в тренировке для команды поддержки PROD. Только нежнее с боевой инфрой! И не забывайте про очистку от разного мусора после тестов.
Жиза: Чтобы быть уверенными в высокой доступности новых, серьёзных по нагрузке сервисов, финальные тесты мы проводим здесь. Особенно это актуально, когда у нас мало времени, например, при запуске срочных выплат населению страны последних пары лет.
Пользователи Госуслуг засыпают, а мы собираемся на ночной zoom и аккуратно тестируем на PROD-инфраструктуре. Тюним на месте, записываем изменения конфигов «на лету» себе в тикеты «на утро». Отдельно заказываем новые VM туда, где понимаем, что не успеем дотюниться до запуска сервиса.
Конечно, для этого нужна аккуратная и дотошная подготовка скриптов для очистки мусора после тестов и выверенный чёткий план тестирования с автоматизацией запуска тестов.
Что можно: Конечно, не всё. В первую очередь это стресс-тесты — короткие, точные, до первых узких мест, чтобы затем произвести тюнинг. Можно сразу в онлайне, чтобы не уходить потом на ещё одни работы. Не получится использовать инфраструктуру PROD, если у вас интенсивная пользовательская нагрузка 24/7 и нет микросервисов, которые вы можете изолировать от влияния на пользователей на 99%+.
Команда: Берите с собой в онлайн ВСЕХ ключевых участников проекта — разработку, сопровождение PROD, специалистов по сети, виртуализации, железу. В общем, всех, кто будет (а лучше не будет, не зря же делается НТ) разбираться с проблемами PROD в день запуска нового сервиса. Ведь это же боевая тренировка!
Для тех, кто по каким-то причинам не хочет в этом участвовать, есть отличный аргумент — или мы сейчас проконтролируем что будет, или будем смотреть на это в онлайне, на живых пользователях и чинить, теряя SLA.
Pros and cons:
+ не только НТ, но и тренировка для команды + в нехватке времени можно тюнить на лету (конечно, сохраняя улучшения в репозиториях) – требуется хорошая подготовка плана и скриптов очистки – не для каждого сервиса возможно НТ на инфраструктуре PROD
Advice: Все же помнят хорошую практику: всё что выкатывается на PROD должно тестироваться? Это же касается и ваших скриптов НТ, тестовых данных, скриптов очистки от мусора после НТ. Всё должно быть протестировано на младших контурах, считайте, что это такой же релиз.
Ну и конечно, так как НТ на PROD — это часто ночные работы, не замучайте команду в ночь перед запуском важных сервисов. Если не успеваете, лучше ребятам поспать ночь и с утра уже готовиться к проблемам на PROD, быстрее будут реагировать.
Во всём нужна мера, потому что, как говорил один мой знакомый менеджер: «Работа отнимает всё отведенное на неё время».
Вместо заключения
Как видите, у каждого стенда НТ найдутся свои нюансы, а главное – своя польза. Уже давно прошли те времена, когда подрядчик требовал нагрузочный стенд, а заказчик закупал его месяцами, тратя огромные деньги. С новыми средствами НТ и микросервисной архитектурой тесты можно проводить на разных этапах и на разных стендах достаточно быстро.
Я бы описал рекомендованный путь становления процессов НТ в компании по части стендов так:
- UAT – отсюда можно стартовать регрессионное НТ
- DEV – для новых сервисов, которые будут нагружены
- PROD – когда отдельного стенда НТ нет, а ожидается новая большая нагрузка
- LT – когда уже научитесь тестировать, поймете систему и действительно сможете использовать дорогое удовольствие с пользой
Конечно, эти стенды у вас могут называться по-другому, типы тестов тоже. Я старался использовать плюс-минус общепринятые понятия. На закрепление терминологии не претендую.
Пишите в комментариях про ваш опыт использования тестовых стендов для НТ. Буду рад почерпнуть что-то новое, в том числе по поводу плюсов и минусов каждого.
Всем результативного НТ и рабочих стендов!
Иллюстрации: Михаил Голев.
Больше публикаций смотрите в моем блоге на Хабре.