

Доступ по индексу в DataFrame
Мы уже рассказывали о структуре DataFrame в Pandas -- высокоуровневой Python-библиотеке для анализа данных. Но как осуществляется доступ по индексу в DataFrame?
На самом деле, индекс по строкам мы можем задавать различными способами, к примеру, в процессе формирования самого объекта DataFrame либо, как говорится "на лету":
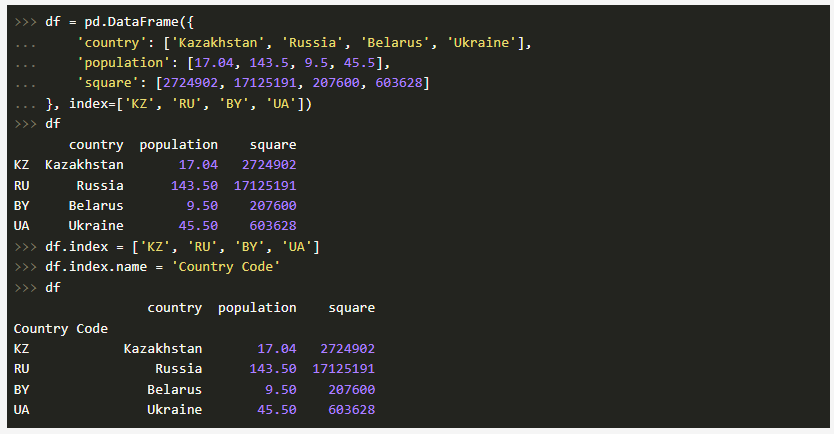
Таким образом, мы видим, что индексу задается имя Country Code. Также стоит отметить, что объекты Series из DataFrame приобретут те же самые индексы, что и объект DataFrame:

При этом доступ к строкам по индексу можно осуществить 2-мя способами:
- .loc -- для доступа по строковой метке;
- .iloc -- для доступа по числовому значению (от 0 и выше).

Идем дальше. У нас есть возможность выполнять выборку по индексу и интересующим колонкам:

Обратите внимание, что .loc в квадратных скобках принимает два аргумента. Кроме интересующего индекса, поддерживаются колонки и слайсинг.

Следующий момент -- у нас есть возможность фильтровать DataFrame, используя для этого булевы массивы:

Кроме того, существует возможность обращения к столбцам -- для этого применяется атрибут либо нотация словарей Python, то есть df.population и df['population'] -- это, по сути, одно и то же.
Если надо сбросить индексы, сделать это можно следующим образом:

Также Pandas при операциях над DataFrame осуществляет возвращение нового объекта DataFrame.
Давайте выполним добавление нового столбца, где население, исчисляемое в миллионах человек, мы поделим на площадь государства, тем самым получив плотность:
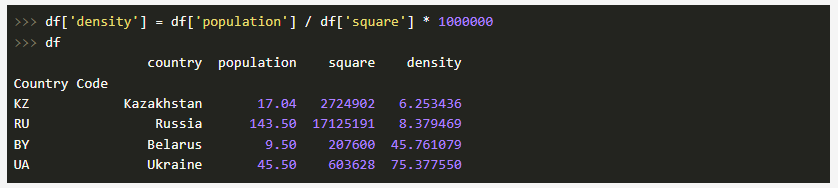
Теперь представим, что новый столбец нас чем-то не устраивает. Не беда -- его можно без проблем удалить:

Ну а если вы очень ленивы, то достаточно написать del df['density'].
Для переименования столбцов воспользуемся методом rename:
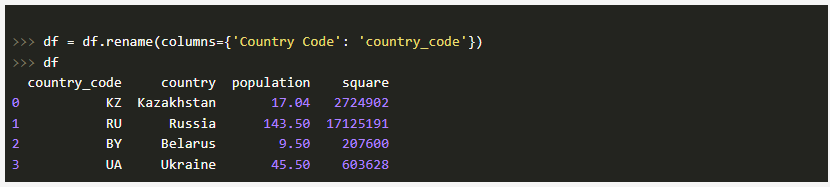
В вышеприведенном примере перед переименованием столбца Country Code следует сначала удостовериться, что с него сброшен индекс. В обратном случае никакого эффекта не будет.
По материалам блога https://khashtamov.com/ru/.