

Группировка, агрегирование и сводные таблицы в Pandas
Библиотека Pandas широко используется при обработке и анализе данных, являясь, среди всего прочего, одним из важных инструментов системного аналитика. В этом материале мы вкратце расскажем о группировке и агрегировании данных.
Стоит отметить, что группировка данных является одним из самых часто используемых методов в процессе анализа данных. В библиотеке Pandas за группировку отвечает специальный метод под названием .groupby.
Чтобы продемонстрировать группировку, давайте возьмем стандартный набор данных (dataset), который часто применяется на курсах анализа данных — речь идет о данных, представляющих собой перечень пассажиров печально известного "Титаника". Скачать соответствующий CSV-файл вы можете по этой ссылке.
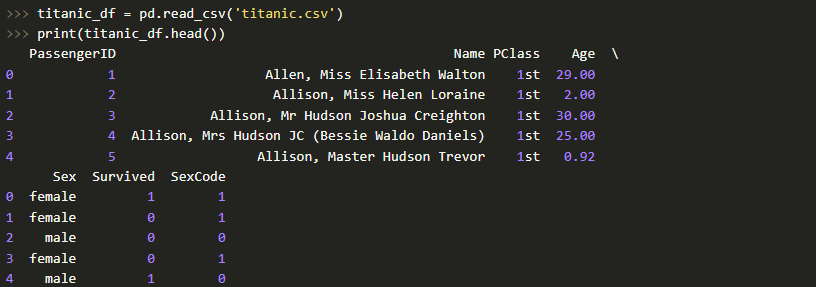
Перед нами задача сосчитать, сколько мужчин и женщин спаслись, а сколько нет. Здесь поможет вышеупомянутый метод .groupby.

А теперь давайте выполним анализ с учетом класса каюты:
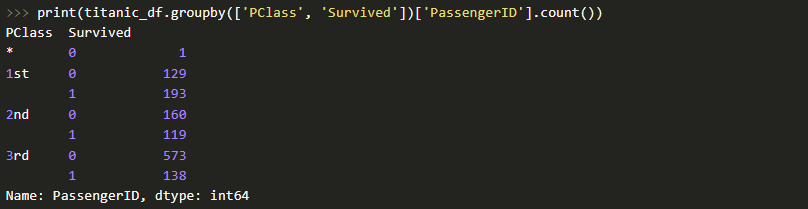
Здесь уместно ввести термин "сводная таблица". Он прекрасно известен всем, кто хорошо знаком с инструментом типа Microsoft Excel. В Pandas сводные таблицы строят с помощью метода .pivot_table. Исходя из вышесказанного, давайте теперь посчитаем, сколько всего мужчин и женщин было в конкретном классе корабля:

Теперь в качестве индекса выступает пол человека, а в качестве колонок -- значения из PClass. Что касается функции агрегирования, то это count (подсчет числа записей) по колонке Name.
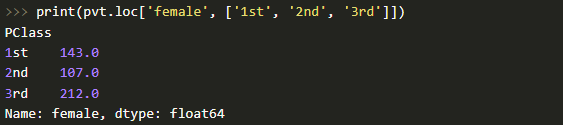
Как видите, все довольно просто.
По материалам блога https://khashtamov.com/ru/.