

ETL в Data-инжиниринге
Среди многих навыков современного Data-инженера можно выделить один из самых важных — это способность разрабатывать/строить/поддерживать хранилища данных. Ведь если качественной инфраструктуры по хранению данных нет, то любая активность, которая будет связана с анализом данных, окажется или слишком дорогой, или просто немасштабируемой. И вот здесь будет вполне уместно вспомнить ETL.
ETL представляет собой общий термин, описывающий процессы миграции данных из одного источника в другой. В общем семантическом ядре, прямо или косвенно связанном с ETL, находятся и такие понятия, как импорт/экспорт/конвертация данных, web-scrapping, парсинг файлов и т. д.).
Сам по себе термин ETL можно назвать аббревиатурой, состоящей из следующих слов: Extract, Transform, Load. Это 3 концептуально важных шага, которые определяют, как устроена большая часть современных пайплайнов данных. По сути, можно говорить о базовой модели того, как именно сырые данные сделать данными, готовыми для анализа.
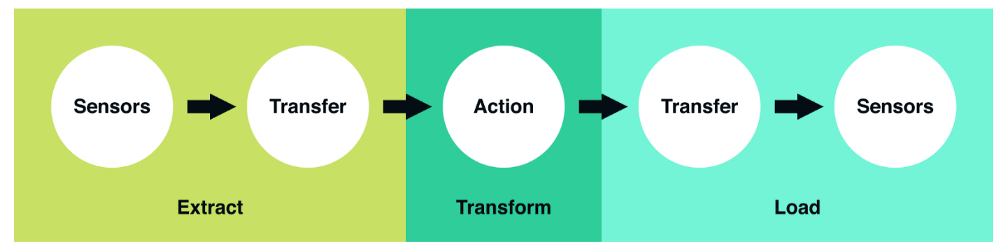
Теперь давайте рассмотрим эти шаги подробнее:
- Extract. На этом шаге данные принимаются на вход из разных источников (пользовательских логов, внешнего набора данных, копий реляционной БД и т.д.). Далее они передаются для дальнейших преобразований.
- Transform. Представляет собой «сердце» любого ETL. На этом этапе применяется бизнес-логика и осуществляются процессы фильтрации, группировки и агрегирования. Делается это в целях преобразования сырых данных в датасет, готовый к анализу. Данная процедура требует четкого понимания существующих бизнес-задач, не говоря уже о наличии соответствующих знаний области хотя бы на базовом уровне.
- Load. Обработанные данные загружаются и отправляются в место конечного пользования. В результате полученный набор данных уже можно использовать. Также это может быть входным потоком к другому ETL.

Типичные этапы ETL-процесса можно представить и так:
- извлечение данных из источника (файла, веб-страницы, базы данных);
- очистка полученных данных (приведение разнородных данных к некому единому формату, устранение недочетов, удаление лишнего и прочее);
- обогащение (если требуется, то для получения новых данных, которые связаны с обрабатываемыми данными, применяются алгоритмы либо внешние источники);
- трансформирование данных;
- загрузка данных (подразумевается интеграция данных в единую целевую модель, к примеру, в DWH).
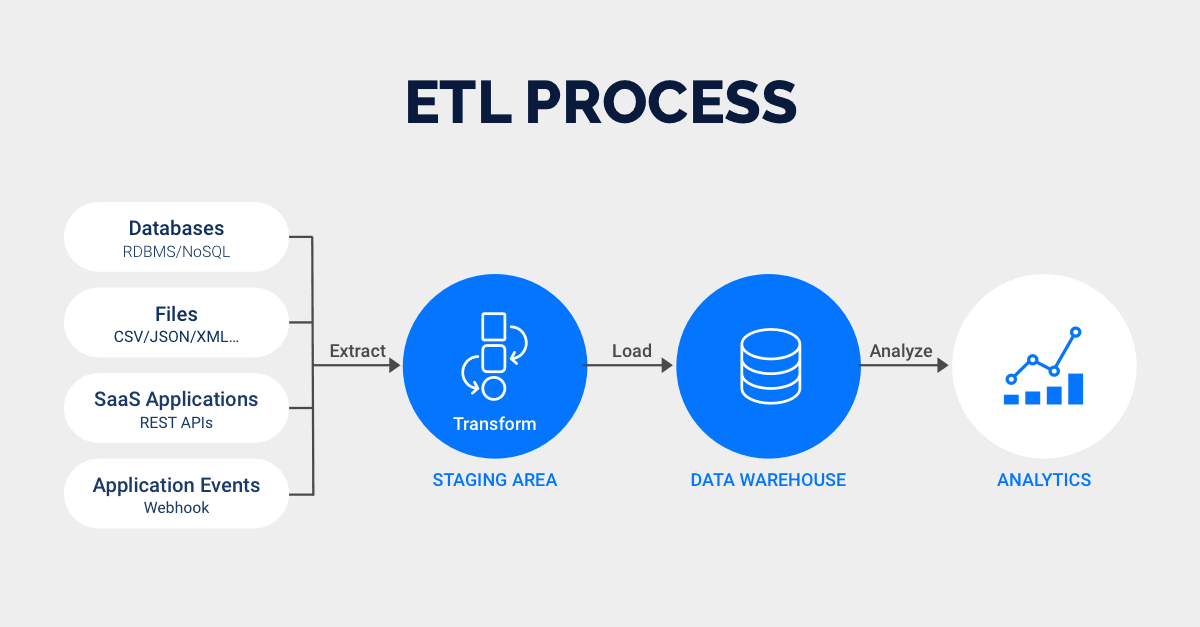
Остается добавить, что если ETL-процессы слишком сложны, имеет смысл их разбить на цепочку более простых.
Источники: - https://issoft.by/blog/razbiraemsya-chto-takoe-etl-na-primere-par/; - https://habr.com/ru/company/newprolab/blog/358530/.