

Структура данных DAWG

Существует огромное количество задач, связанных с обработкой текстов: машинный перевод, фильтрация спама, data mining, спеллчекеры, научные задачи такие, как работа с последовательностями ДНК, и многие другие.
Почти все эти задачи объединяет то, что тексты состоят из отдельных слов, а для эффективного хранения данных требуются специфические структуры данных. Почему? Что это за структуры данных, за счёт каких особенностей текстовых данных они эффективны? Давайте разбираться на примере DAWG.
Что такое DAWG?
DAWG (Deterministic Acyclic Word Graph, также DAFSA — Deterministic Acyclic Finite State Automaton) — структура данных, которая часто используется в ситуациях, когда нужна быстрая, компактная коллекция, в которой можно использовать слова в качестве ключей и связанную с ними дополнительную информацию (например, частоту использования, грамматические свойства и прочее). При этом количество слов для языка с богатой морфологией такого, как русский или финский, будет исчисляться миллионами за счёт разных словоформ одной и той же лексемы, например: — ворон; — ворона; — ворону; — и т.д.
Для создания словаря всегда можно прибегнуть к проверенному средству — хеш-таблице, однако в случае необходимости хранения нескольких миллионов слов размеры такого словаря будут весьма существенными — порядка десятков или даже сотен мегабайт.
Что, если для эффективного хранения слов использовать более «продвинутую» схему, которая использует то, что многие слова похожи или частично совпадают?
Схема простая: давайте «складывать» вместе слова, которые начинаются на одну и ту же букву, затем «складывать» вместе продолжения слов с одинаковой второй буквой и т.д.
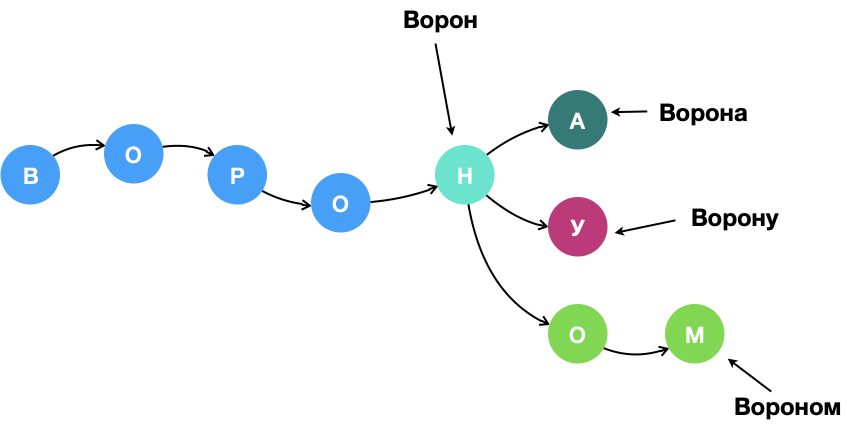 Рис. 1.«Связанные» вместе слофовормы лексемы «ворон». Цветами, кроме синего, выделены узлы, в которых хранятся конкретные лексемы, остальные узлы «пустые».
Рис. 1.«Связанные» вместе слофовормы лексемы «ворон». Цветами, кроме синего, выделены узлы, в которых хранятся конкретные лексемы, остальные узлы «пустые».
При поиске или извлечении слова из реализованного таким образом словаря достаточно «спуститься» по рёбрам дерева, пока не закончатся буквы в слове-запросе или пока не будет достигнуто условие остановки: нет подходящего ребра для перехода — значит, нет и целевого слова. Время поиска слова в trie равно O(n), где n — количество символов в слове (как правило, для вычисления хеша от строки всё равно надо “обойти” все символы строки и выполнить над ними набор операций, что дает то же O(n) действий для хеш-таблиц).
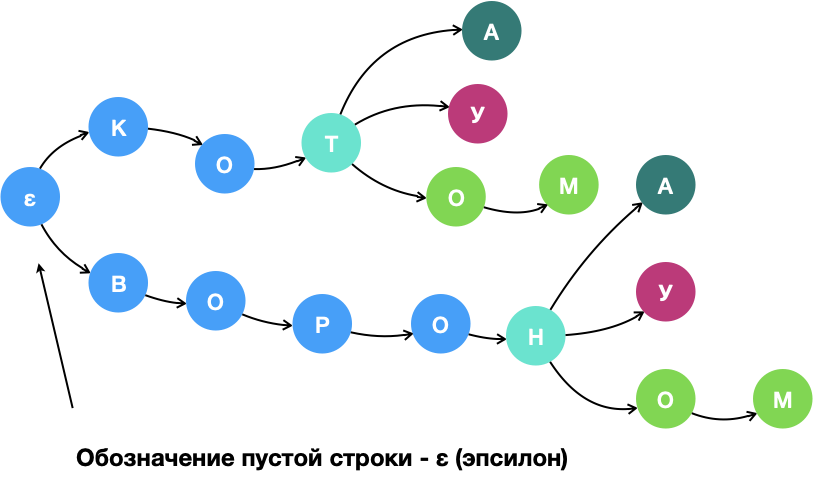 Рис. 2. Trie из разных форм лексем «кот» и «ворон». В корне trie — пустая строка. Для наглядности буквы помещены на узлы, хотя они соответствуют правилам перехода между узлами, то есть рёбрам.
Рис. 2. Trie из разных форм лексем «кот» и «ворон». В корне trie — пустая строка. Для наглядности буквы помещены на узлы, хотя они соответствуют правилам перехода между узлами, то есть рёбрам.
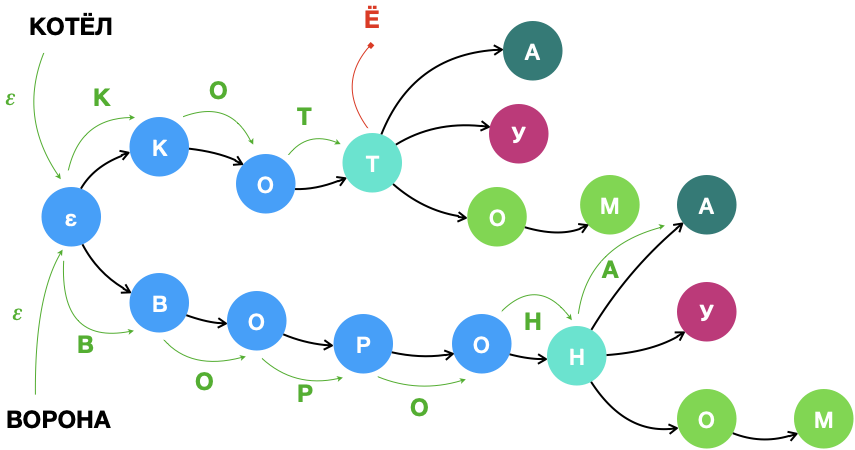 Рис. 3. Поиск лексем «ворона» и «котёл» в trie.
Рис. 3. Поиск лексем «ворона» и «котёл» в trie.
Знакомые с графами могут заметить, что trie является направленным ациклическим графом (DAG), с рёбрами которого связаны символы, которые сопоставляются со словом-запросом при переходе между узлами.
Определение выше «не строго» описывает логику, которая используется при построении trie или префиксного дерева. Однако у trie есть недостаток: его «ветвистость» — повторяющиеся окончания слов встречаются во многих «ветвях». Вероятно, можно оптимизировать затраты памяти на хранение trie, не снижая при этом скорости поиска, если «связать» повторяющиеся участки вместе.
Часто построение DAWG начинается с построения trie, а затем выполняется его «минимизация». Какие алгоритмы используются для минимизации trie? Задача выглядит нетривиальной.
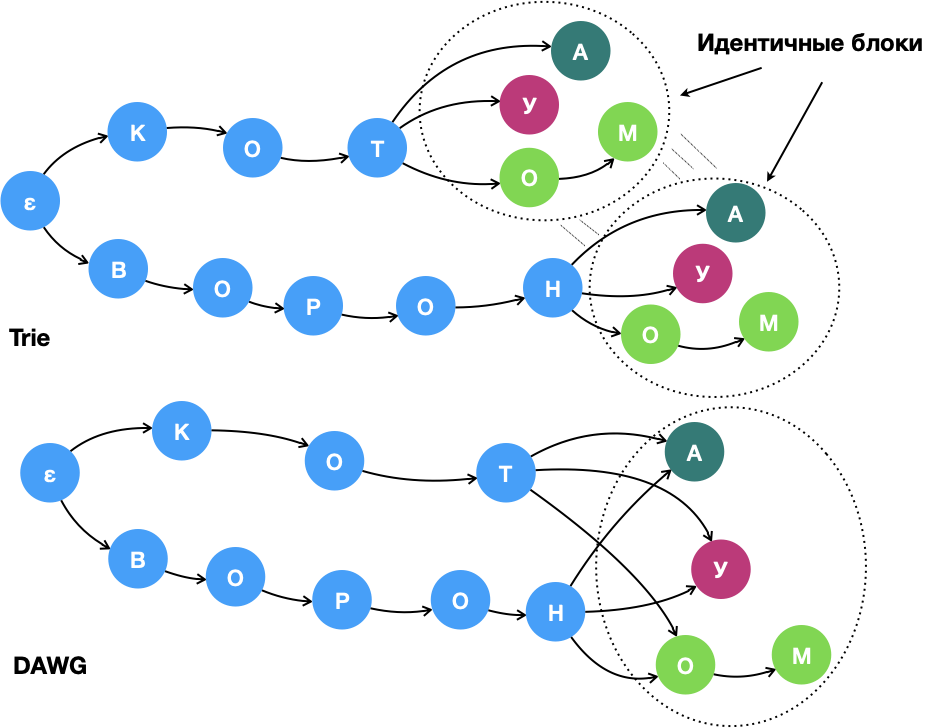 Рис. 4. Трансформация trie в DAWG при помощи минимизации графа.
Рис. 4. Трансформация trie в DAWG при помощи минимизации графа.
К счастью, взгляд на DAWG под немного другим углом помогает нам увидеть в нём детерминированный конечный автомат. В этом случае trie — это детерминированный конечный автомат, который отклоняет либо принимает строки, поданные на вход, и который можно упростить. Для упрощения можно использовать один из алгоритмов минимизации конечных автоматов.
Хотя, в принципе, строить DAWG можно и сразу, минуя стадию Trie.
Важно понимать, что при минимизации не все одинаковые участки объединяются: объединение одинаковых участков не должно приводить к «добавлению» новых слов в словарь и образованию циклов.
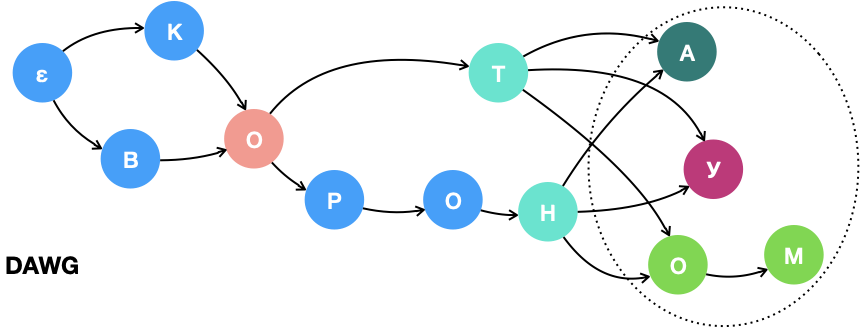 Рис. 5. «Неправильная» минимизация добавила лишние слова: «вот», «воту», в «вотом», «корон», «корона», … (слово «корона» существует, но его не было в словаре).
Рис. 5. «Неправильная» минимизация добавила лишние слова: «вот», «воту», в «вотом», «корон», «корона», … (слово «корона» существует, но его не было в словаре).
После построения DAWG на заданном наборе строк мы получаем структуру данных-словарь, работающую «под капотом» как конечный автомат и способную проверить, есть ли целевое слово в словаре, и, при необходимости, извлечь данные о слове.
Поскольку, в отличие от trie, в одном узле может «находиться» более одного слова, то данные об отдельных словах приходится хранить в дополнительной структуре данных (например, списке). Это усложнение, однако, компенсируется эффективностью DAWG.
Рассмотрим пример библиотеки pymorphy2 (статья о реализации) для обработки естественного языка. Запись примерно трёх миллионов русских слов потребовала для хранения в зависимости от структуры данных при схожей скорости обработки (количество извлекаемых слов/сек): — словарь — около 600 Мб; — trie — 70 Мб; — DAWG — 7 Мб.
Делаем выводы
DAWG — эффективная в плане потребления памяти и скорости извлечения слов структура данных, которая часто используется в области обработки естественных языков. Также DAWG можно воспринимать как детерминированный конечный автомат без циклов (DAFSA — Deterministic Acyclic Finite State Automaton). Время, затрачиваемое на поиск строки в DAWG, равно O(1) относительно строк и O(n) относительно количества символов в строке.
Экономия памяти, достигаемая DAWG, зависит от конкретного набора строк, на котором строится автомат, но для естественных языков может снижать расход памяти на порядки.