

DataOps в BigData: методы и средства реализации
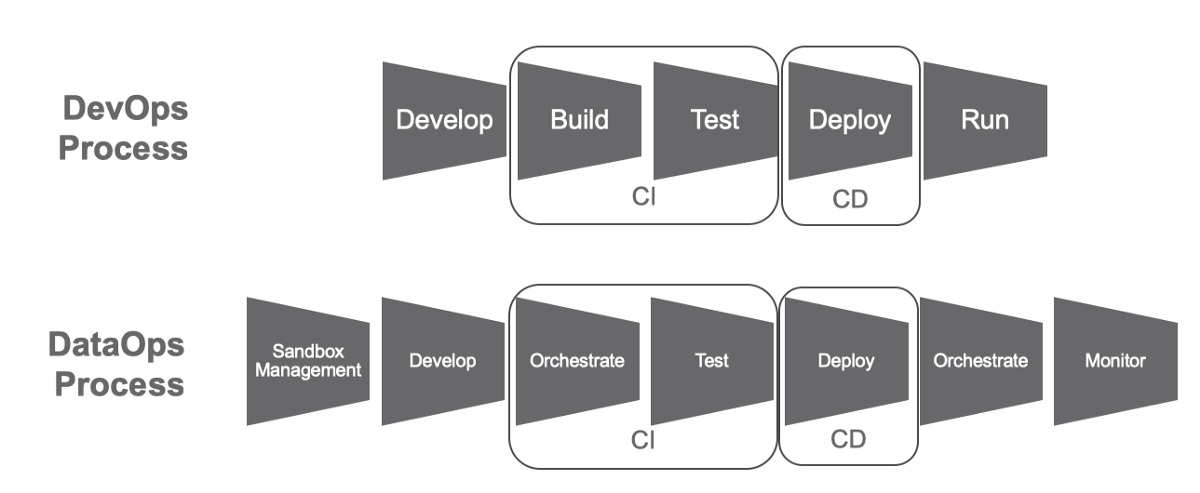
Как и в случае с DevOps, когда разработка и эксплуатация, по сути, интегрированы в единый процесс взаимодействия специалистов по разработке кода, тестированию, развертыванию и поддержке, концепция DataOps тоже реализует идею по непрерывной интеграции, доставке и обработке данных. Для этого в проектах Big Data применяют:

Конвейер данных
Для бесперебойной работы конвейера данных для Data-Driven company (иными словами -- для цифрового предприятия) его IT-инфраструктура должна обеспечивать ряд процессов. Перечислим их:
- оркестрация информационных потоков — подразумевается движение больших данных по маршрутной карте с сопутствующим описанием всех источников данных, а также модели представления и интеграции этих данных. Кроме этого, описываются шаги процесса анализа данных. Для решения вышеописанных задач подходят такие инструменты, как Apache Oozie (это планировщик процессов заданий Apache Hadoop), DataKitchen (это платформа DataOps-поддержки полного цикла аналитической обработки -- сокращает сроки подготовки и доставки данных необходимого качества), BMC Control-M (известное решение по автоматизации пакетной обработки), Reflow (это уже система инкрементальной обработки различных данных в облаке посредством произвольных программ, которые упакованы в контейнеры Docker);
- автоматизированное тестирование/обеспечение качества данных — речь идет о проверке и очистке информации на каждом этапе обработки данных. Тут можно применять такие инструменты, как ICEDQ (программный софт для автоматизации тестирования в контексте работы с ETL-хранилищами/средствами миграции данных), а также Naveego (представляет собой облачную платформу по построению информационных витрин и панелей, главная цель которой -- мониторинг состояния данных);
- автоматическое распределение — это непрерывное перемещение кода/конфигураций по всем этапам CRISP-DM, начиная с постановки задачи с точки зрения бизнеса, заканчивая внедрением. В данном случае будут полезны классические DevOps-инструменты, тот же Jenkins, обеспечивающий непрерывную поставку программного обеспечения с автоконтролем всех существующих этапов жизненного цикла ПО, начиная с написания кода, заканчивая автоматическим тестированием и развертыванием в соответствующих эксплуатационных средах;
- управление «песочницами» и развертывание моделей данных — подразумевается формирование воспроизводимых сред по работе с данными посредством DevOps: это и бесшовная интеграция, и ускорение процессов по извлечению данных для бизнеса, и разработка, и развертывание программных приложений и аналитических моделей (DSFlow, Domino, Open Data Group);
- виртуализация данных/управление тестовыми данными -- сюда же следует включить защиту данных и мониторинг их производительности. Среди инструментов можно отметить Delphix и Redgate;
- интеграция и унификация данных, включая использование Machine Learning. Инструменты: Tamr, Switchboard Software;
- мониторинг и управление производительностью облачных и локальных решений — речь идет о наблюдении за текущими процессами по хранению и обработке больших данных, а также о выявлении аномалий. В этом случае среди инструментов нужно выделить SelectStar (служит для мониторинга БД), MapR (представляет собой конвергентную платформу по работе с Big Data, которая объединяет инструменты реалтайм-аналитики и операционные бизнес-приложения), Unravel (средство по управлению производительностью и по работе с программными приложениями и платформами Big Data), Quobole (представляет собой облачную платформу Вig Data as a Service).
По материалам https://www.osp.ru/.