

Анализируем данные: структура Series в Pandas
Обработка и анализ данных – важнейшая часть работы специалиста по системному анализу. В этом может помочь Pandas — программная высокоуровневая библиотека, написанная на Python. Главными структурами данных в ней являются Series и DataFrame. Не понимая их работу, выполнить качественный анализ будет невозможно.
Series — объект, напоминающий одномерный массив (к примеру, список в Python). Отличительная черта — ассоциированные метки или так называемые индексы, расположенные, вдоль каждого элемента списка. Это особенность и превращает Series в ассоциативный массив либо словарь в Python.
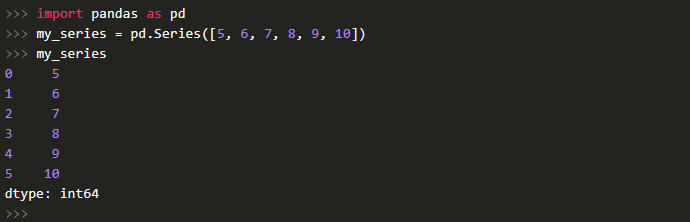
В строковом представлении Series индекс находится слева, а элемент справа. Если же индекс не задан явно, pandas автоматически создаст RangeIndex от 0 до N-1, где N — общее число элементов. Кроме того, следует учесть, что в Series существует тип хранимых элементов (в примере это int64, ведь мы передавали целочисленные значения).
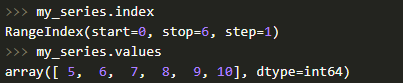
Также у объекта Series есть атрибуты, посредством которых вы сможете получить список элементов и индексы — values и index соответственно.
Доступ к элементам Series осуществляется по индексу этих элементов.

При этом мы можем задавать индексы явно:

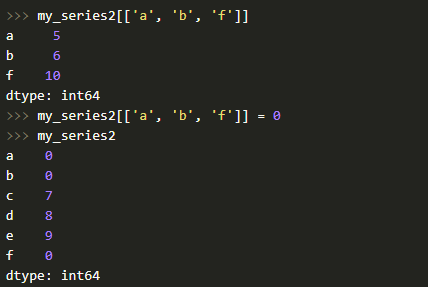
Также есть возможность осуществлять выборку по нескольким индексам и выполнять групповое присваивание:
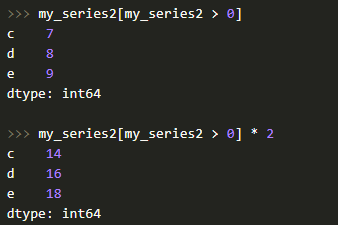
Что касается фильтрации, то это тоже не проблема для Series, плюс можно применять математические операции и т. д.:
Но если сам объект Series напоминает словарь, где ключ — это индекс, а значение — сам элемент, то мы можем сделать следующее:
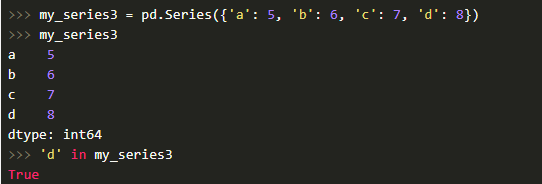
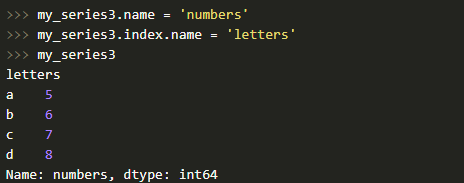
У объекта Series и его индекса присутствует атрибут name, который задает имя объекту и индексу.
Индекс мы можем поменять без проблем, присвоив список атрибуту index объекта Series.
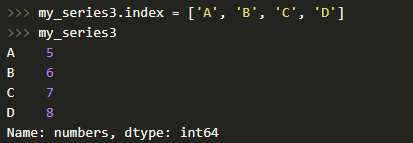
Также имейте в виду, что список с индексами по длине в обязательном порядке должен совпадать с числом элементов в Series.
По материалам блога https://khashtamov.com/ru/.