

Архитектура Hadoop
Hadoop представляет собой свободно распространяемый фреймворк, а также набор утилит и библиотек. Он используется при разработке и выполнении распределённых программ, функционирующих на кластерах из множества узлов (сотен и даже тысяч). По сути, речь идёт о технологиях, предназначенных для хранения и обработки больших данных.
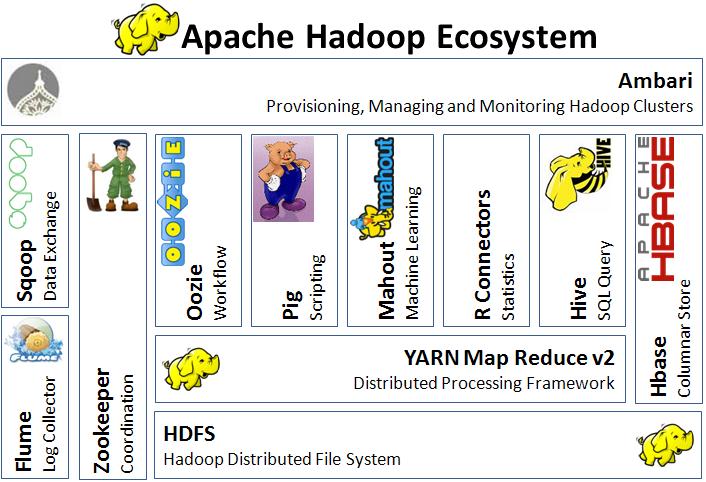
Из чего состоит Hadoop?
Проект разрабатывался на Java с учётом вычислительной парадигмы MapReduce (приложение делится на множество одинаковых элементарных заданий, выполняемых на распределённых компьютерах (нодах) кластера и сводимых в единый результат).
Архитектурная концепция Hadoop предполагает наличие четырёх модулей: 1. Hadoop Common – комплект инфраструктурных программных библиотек и утилит, используемых в других решениях и родственных проектах, в том числе и для управления распределёнными файлами, а также для создания нужной инфраструктуры. 2. HDFS (Hadoop Distributed File System) – распределённая файловая система. Это технология хранения файлов на разных серверах данных (узлах, DataNodes), причём их адреса располагаются на специальном сервере имён (мастере, NameNode). Благодаря репликации информационных блоков, HDFS-система обеспечивает надёжное хранение файлов больших размеров. Файлы распределены между узлами вычислительного кластера поблочно. 3. YARN (Yet Another Resource Negotiator) – система планирования заданий и управления кластером, называемая ещё MapReduce 2.0 (MRv2). Эта система представляет собой набор системных программ (демонов), которые обеспечивают совместное применение, масштабирование и надёжность работы распределённых приложений. По сути, YARN — это интерфейс между аппаратными ресурсами кластера и приложениями. 4. Hadoop MapReduce – платформа программирования и осуществления распределённых MapReduce-вычислений с применением большого количества компьютеров (nodes, узлов), которые образуют кластер.

Некоторые инструменты Hadoop: • HBase — NoSQL СУБД, которая эффективно поддерживает случайное чтение и запись; • Pig — среда выполнения и язык обработки; • SPARK — перечень инструментов по реализации распределённых вычислений; • Hive — хранилище данных с SQL-интерфейсом; • ZooKeeper — хранилище конфигурационной информации и прочие.
Разнообразие в экосистеме Hadoop делает «слонёнка» универсальным инструментом, изменяющимся с течением времени. При этом в настоящее время вокруг Hadoop сформировалась целая экосистема технологий и связанных проектов, используемых для интеллектуального анализа больших данных (Data Mining), в том числе и посредством машинного обучения (Machine Learning).
Кем и где используется Hadoop?
Hadoop используют разные компании, включая крупные и хорошо известные: eBay, Facebook, Amazon, IBM, AliExpress, Yahoo! и пр. При этом не существует единой схемы работы с данными для любой компании, так как работа всех сервисов специфична. Также на основную функциональность накладываются дополнительные фичи, которые специально разработаны для конкретных компаний.
Основные области применения Hadoop: • контекстные и поисковые механизмы высоконагруженных интернет-магазинов и web-сайтов; • хранение и сортировка больших объёмов данных, разбор содержимого огромных файлов; • быстрая обработка графических данных.
Если интересуют подробности об этой экосистеме, добро пожаловать на наш курс! Он рассчитан на Data-инженеров, которые желают поглубже изучить Spark, Hadoop, Hive.
Источники: • https://ru.wikipedia.org/wiki/Hadoop; • https://m.habr.com/ru/post/240405/; • https://www.ibm.com/developerworks/ru/library/bd-hadoopyarn/index.html; • https://www.ibm.com/developerworks/ru/library/l-hadoop/index.html.