

Шпаргалка по разновидностям нейронных сетей. Часть 1

Существует много различных нейронных сетей, причём новые виды архитектуры появляются постоянно, а некоторые из них очень похожи между собой. В связи с этим мы подготовили шпаргалку по нейронным сетям, которая поможет вам не запутаться во всём их многообразии. В статье вы найдёте как элементарные, так и продвинутые конфигурации.
Нейросети прямого распространения

Нейросети прямого распространения (feed forward neural networks, FFNN либо FF) и перцептроны (perceptrons, P) являются очень прямолинейными и передают данные от входа к выходу. Описываются в виде слоёного торта, в котором каждый слой включает входные и скрытые (выходные) клетки.
Простейшая сеть может применяться в виде модели логических вентилей и состоит из 2-х входных клеток и одной выходной.
Обычно такие сети обучаются по методу обратного распространения ошибки. На практике используются нечасто, но их нередко комбинируют с другими типами.
Нейросети радиально-базисных функций
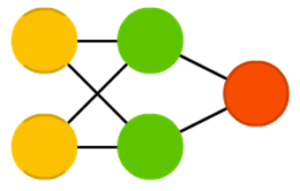
Нейросеть радиально-базисных функций (radial basis function, RBF) — это та же FFNN, но использующая радиальные базисные функции в качестве функций активации. В принципе, больше такие сети ничем особым не выделяются.
Нейросеть Хопфилда
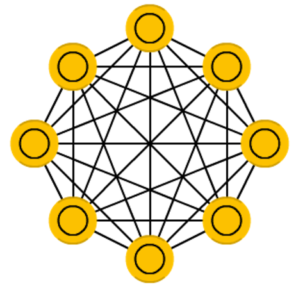
Нейросеть Хопфилда (Hopfield network, HN) представляет собой полносвязную нейросеть, обладающую симметричной матрицей связей. При получении входной информации каждый узел является входом, который в процессе обучения превращается в скрытый, а потом становится выходом.
Такую нейросеть часто называют сетью с ассоциативной памятью. Можно провести аналогию с человеком, который, видя половину таблицы, способен представить и 2-ю половину. Эта нейронная сеть работает схожим образом: получая наполовину «зашумленную» таблицу она восстанавливает её полностью.
Цепи Маркова
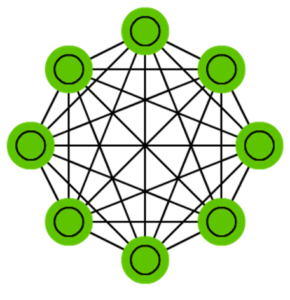
Цепи Маркова (Markov chains, MC либо discrete time Markov Chains, DTMC) являются предшественниками сетей Хопфилда (HN) и машин Больцмана (BM). Смысл этих цепей можно представить следующим образом: какие у меня шансы попасть в один из последующих узлов, когда я нахожусь в данном? Можно сказать, что каждое последующее состояние зависит от предыдущего. Но на деле цепи Маркова нейронными сетями не являются, хотя они очень похожи. Кстати, они не обязательно полносвязны.
Машина Больцмана
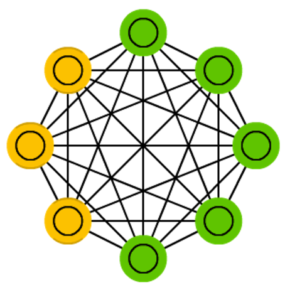
Считается, что машина Больцмана (Boltzmann machine, BM) весьма похожа на сеть Хопфилда, однако в ней некоторые нейроны отмечены входными, а некоторые — скрытыми. Причём в дальнейшем входные нейроны превращаются в выходные.
BM — стохастическая сеть. Она обучается по методу обратного распространения ошибки либо путём использования алгоритма сравнительной расходимости. В общих чертах обучающий процесс напоминает оный у нейросети Хопфилда.
Ограниченная машина Больцмана
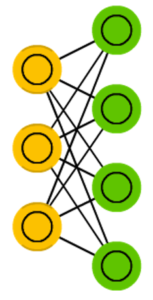
Ограниченная машина Больцмана (restricted Boltzmann machine, RBM) весьма похожа на обычную машину Больцмана и, разумеется, на нейросеть Хопфилда. Главная разница заключается в ограниченности — здесь нейроны одного типа между собой не связаны.
Ограниченную RBM вы можете обучать, как и нейросети прямого распространения, но существует нюанс: вместо прямой передачи информации и обратного распространения ошибки следует передавать информацию сначала в прямом направлении, потом в обратном. После осуществляется обучение путём прямого и обратного распространения ошибки.
Автокодировщик
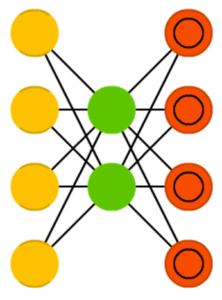
Автокодировщик (autoencoder, AE) напоминает FFNN, но является, скорее, просто иным способом применения нейронных сетей прямого распространения, чем принципиально другой архитектурой. Основная идея — автоматическое кодирование данных (в плане сжатия, а не шифрования).
Сама нейросеть по виду напоминает песочные часы, т. к. в ней скрытые слои меньше выходного и входного, при этом она симметрична.
Для обучения можно использовать обратное распространение ошибки, подавая входную информацию и задавая ошибку, равную разнице между выходом и входом.
Разреженный автокодировщик
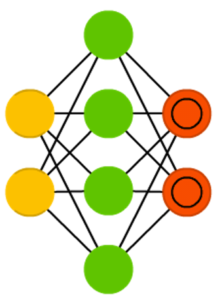
Разреженным автокодировщиком (sparse autoencoder, SAE) в некоем смысле называют противоположность обычного кодировщика. Вместо обучения нейросети отображению информации в меньшем «объёме» узлов, мы осуществляем увеличение их количества. В итоге сеть не сужается к центру, а раздувается.
Эти нейросети полезны при работе с большим числом мелких свойств набора данных. Если обучать нейросеть, как обычный автокодировщик, полезного ничего не выйдет. Именно поэтому кроме входных данных нужно дополнительно подавать специальный фильтр разреженности, пропускающий лишь определённые ошибки.
Вариационные автокодировщики
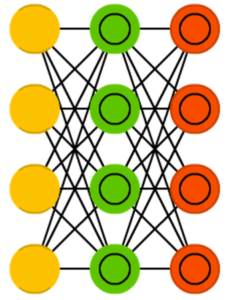
Вариационные автокодировщики (variational autoencoder, VAE) имеют структуру с AE-архитектурой, но обучают их приближению вероятностного распределения входных образцов. В этом VAE берут начало от машин Больцмана, но опираются они на байесовскую математику. Обобщив, скажем, что такая нейросеть принимает в расчёт влияния нейронов.
Шумоподавляющие автокодировщики
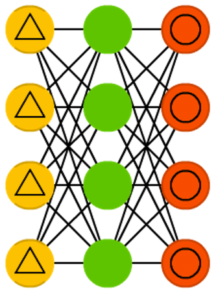
Шумоподавляющие автокодировщики (denoising autoencoder, DAE) представляют собой AE, где входная информация подаётся в зашумленном состоянии. Ошибка вычисляется так же, то есть выходные данные сравнивают с зашумленными. В результате нейросеть учится обращать внимание на более широкие свойства, так как маленькие могут меняться вместе с шумом.
Нейросеть «deep belief»
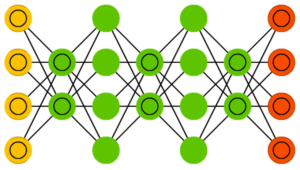
Нейросетью типа «deep belief» (deep belief networks, DBN) называют архитектуру, где сеть включает в себя нескольких соединённых RBM либо VAE. Данные сети обучаются поблочно, при этом каждому блоку надо лишь уметь закодировать предыдущий. Это техника «жадного обучения», т. к. она заключается в выборе оптимальных локальных решений, которые не гарантируют оптимальный конечный результат.
Кроме того, используя метод обратного распространения ошибки, мы можем обучить нейросеть отображать информацию в виде вероятностной модели. А если задействовать обучение без учителя, то стабилизированную модель мы сможем использовать при генерации новых данных.
Свёрточные нейросети
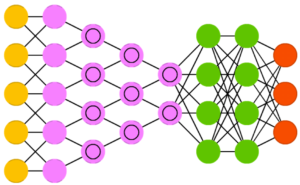
Свёрточные нейронные сети (convolutional neural networks, CNN) и глубинные свёрточные нейросети (deep convolutional neural networks, DCNN) существенно отличаются от других видов. Как правило, их применяют для обработки изображений, иногда для аудио.
Типичный способ использования — классификация изображений: если на фото кошка, нейросеть выдаст «кошка», если есть пёс — «пёс». Нейросети этого типа обычно используют «сканер», который не парсит все данные за один раз. При наличии фото 200×200, не будут обрабатываться сразу все 40 тыс. пикселей, т. к. сеть сначала выполнит считывание квадрата 20x20 (обычно из верхнего левого угла), потом переместится на 1 пиксель, считает новый квадрат, и т. п. Полученные таким образом входные данные будут переданы с помощью свёрточных слоёв, где не все узлы соединены между собой. Собственно говоря, слои эти могут сжиматься с глубиной, при этом часто применяются степени двойки: 32, 16, 8, 4, 2, 1.
На практике к концу CNN прикрепляют FFNN для последующей обработки данных. Эти сети уже называют глубинными (DCNN).
Развёртывающие нейросети
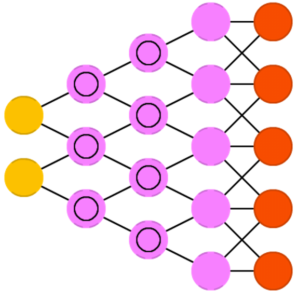
Развёртывающие нейросети (deconvolutional networks, DN) — их ещё называют обратные графические сети — являются обратными к свёрточным нейросетям. Допустим, вы передаёте слово «кошка», а нейросеть генерирует изображения с кошками, похожими на реальные изображения кошек.
Развёртывающие нейросети тоже возможно объединять с FFNN. Стоит сказать и то, что во многих случаях нейросети передаётся не строка, а бинарный вектор (к примеру, <0, 1> — значит кошка, <1, 0> — собака, <1, 1> — и собака, и кошка).