

Функции потерь Дискриминатора: стабилизация обучения

В первом посте я в общих чертах рассказал о том, что такое генеративные состязательные сети. Идея заставить соревноваться две нейронные сети выглядит очень просто и красиво, однако при реализации для конкретных задач обязательно возникают трудности. В этот раз я расскажу о том, как немножко изменить функции потерь так, чтобы стабилизировать процесс обучения.
Предобучение Дискриминатора
Функция потерь для Генератора имеет вид: 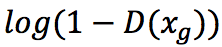 Однако на первых порах Дискриминатору достаточно просто отличить реальные данные от сгенерированных. Более того, некоторые авторы рекомендуют предобучать Дискриминатор так, чтобы он изначально имел некоторое представление о данных. Это приводит к тому, что значения функции потерь быстро становятся нулевыми, что препятствует градиентному спуску и обучению Генератора.
Однако на первых порах Дискриминатору достаточно просто отличить реальные данные от сгенерированных. Более того, некоторые авторы рекомендуют предобучать Дискриминатор так, чтобы он изначально имел некоторое представление о данных. Это приводит к тому, что значения функции потерь быстро становятся нулевыми, что препятствует градиентному спуску и обучению Генератора.
Поэтому уже сам Гудфеллоу в своей статье рекомендует заменять
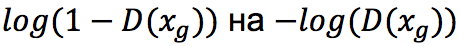 – функцию с экстремумами в тех же точках, однако «насыщающуюся», только если Дискриминатор начинает безоговорочно верить Генератору (чего на практике, конечно, не должно происходить).
– функцию с экстремумами в тех же точках, однако «насыщающуюся», только если Дискриминатор начинает безоговорочно верить Генератору (чего на практике, конечно, не должно происходить).
Переполнение экспонент
Пожалуй, ещё более важный трюк, относящийся не только к GAN’ам, связан с переполнением экспонент. Для задач классификации типичной функцией активации выходного слоя является логистический сигмоид:
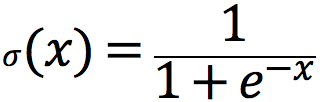 При вычислении этой функции достаточно относительно небольших отрицательных значений «x» для того, чтобы вылететь за пределы float. В связи с этим логистическую функцию потерь часто переписывают следующим образом. В исходном виде она распадается на сумму двух логарифмов:
При вычислении этой функции достаточно относительно небольших отрицательных значений «x» для того, чтобы вылететь за пределы float. В связи с этим логистическую функцию потерь часто переписывают следующим образом. В исходном виде она распадается на сумму двух логарифмов:
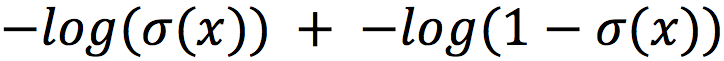 Где «x» – активации последнего слоя сети.
Где «x» – активации последнего слоя сети.
Рассмотрим их по отдельности:
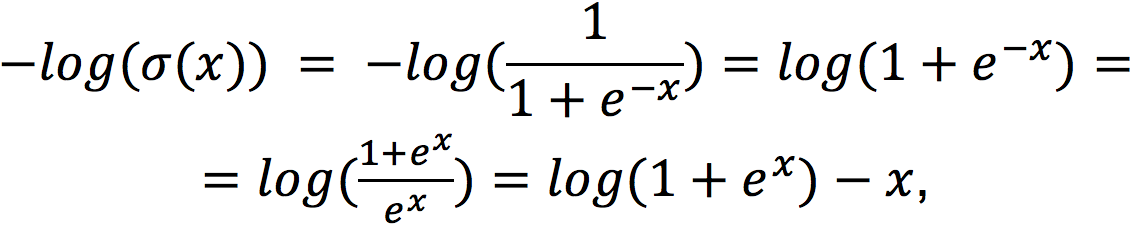 то есть,
то есть,
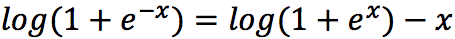 Если для положительных значений «x» мы сможем вычислять левую часть этого равенства, а для отрицательных – правую вместо исходного логарифма от сигмоиды, то проблема с переполнением экспоненты отпадёт. Оказывается, не так сложно это записать в одну формулу:
Если для положительных значений «x» мы сможем вычислять левую часть этого равенства, а для отрицательных – правую вместо исходного логарифма от сигмоиды, то проблема с переполнением экспоненты отпадёт. Оказывается, не так сложно это записать в одну формулу:
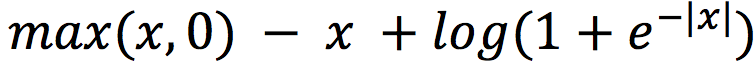 После всех проделанных нами преобразований легко проверить, что эта формула и есть -log(σ(x)), а для -log(1-σ(x)) аналогичную формулу вывести вы можете сами, однако ответ я вам сразу скажу:
После всех проделанных нами преобразований легко проверить, что эта формула и есть -log(σ(x)), а для -log(1-σ(x)) аналогичную формулу вывести вы можете сами, однако ответ я вам сразу скажу:
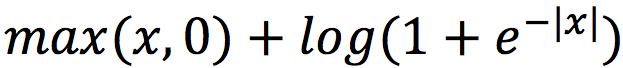 Теперь мы можем легко переписать функцию потерь Дискриминатора:
Теперь мы можем легко переписать функцию потерь Дискриминатора:
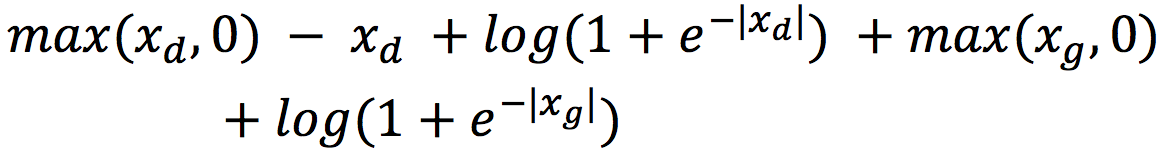 Где xg и xd обозначают соответственно сгенерированные примеры и примеры из обучающей выборки.
Где xg и xd обозначают соответственно сгенерированные примеры и примеры из обучающей выборки.
В следующий раз я расскажу вам про то, как кучи земли могут помочь в обучении Генератора.
Остались вопросы? Напишите в комментариях!