

Пишем скрипт для поиска с помощью Python и OpenCV
В этой статье мы рассмотрим, как в кратчайшие сроки написать Python-скрипт, который пригодится для подсчёта числа книг на изображении. Для работы будем использовать библиотеку алгоритмов компьютерного зрения OpenCV.
Какова задача?
Посмотрите на фото ниже:

На изображении мы видим 4 книги и различные отвлекающие предметы: конфету, магниты, кофе, чашку. Наша задача — найти эти 4 книги с помощью машинного зрения и не определить как книгу ни один другой предмет.
Чтобы выполнить эту задачу, мы, кроме вышеупомянутой библиотеки OpenCV, будем использовать также и NumPy, поэтому эти библиотеки понадобится установить.
Приступаем к поиску
Открываем редактор кода, создаём новый файл с именем find_books.py и начинаем:
# -*- coding: utf-8 -*- # импортируем нужные пакеты import numpy as np import cv2 # загружаем изображение, меняем цвет на оттенки серого и уменьшаем резкость image = cv2.imread("example.jpg") gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) gray = cv2.GaussianBlur(gray, (3, 3), 0) cv2.imwrite("gray.jpg", gray)
Прежде всего, надо выполнить импорт библиотеки OpenCV. Обратите внимание, что загрузка изображения с диска обрабатывается с помощью функции cv2.imread. Тут мы просто загружаем его с диска, после чего преобразуем цветовую гамму в оттенки серого.
Кроме этого, мы немного размываем изображение, дабы уменьшить ВЧ-шумы и увеличить точность приложения. После исполнения кода изображение будет выглядеть следующим образом:

То есть мы выполнили загрузку изображения с диска, преобразовали фото в оттенки серого, а потом немного размыли изображение.
Что же, давайте определим контуры объектов на изображении:
# распознаём контуры edged = cv2.Canny(gray, 10, 250) cv2.imwrite("edged.jpg", edged)
Теперь изображение выглядит так:
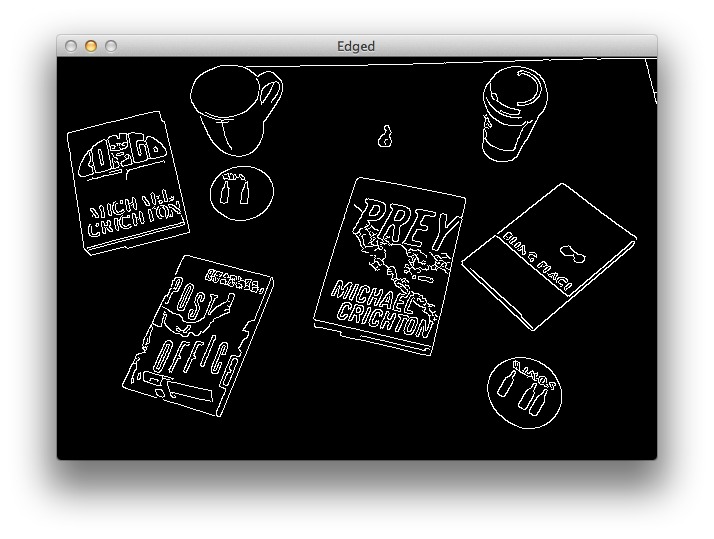
Итак, мы определили на изображении контуры объектов. Но, как видно, часть контуров не закрыта, а между контурами есть промежутки. Дабы убрать промежутки, существующие между белыми пикселями, задействуем операцию «закрытия»:
# создаём и применяем закрытие kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7)) closed = cv2.morphologyEx(edged, cv2.MORPH_CLOSE, kernel) cv2.imwrite("closed.jpg", closed)
Вуаля, теперь пробелы в контурах закрыты:
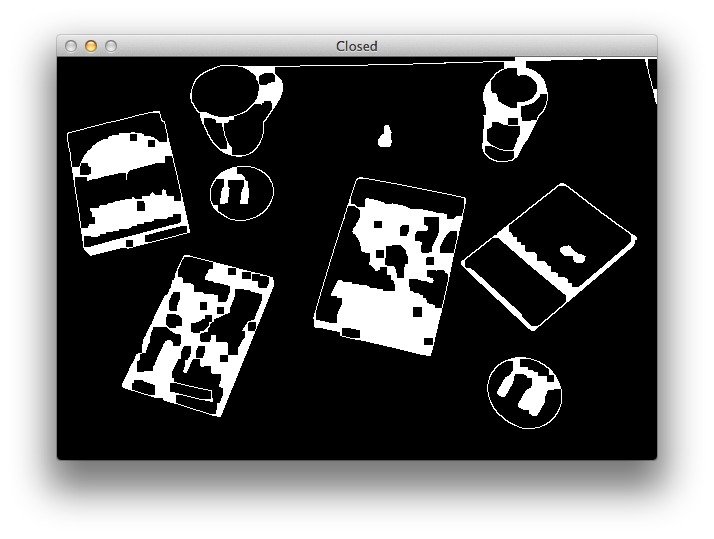
Следующий этап — фактическое обнаружение контуров объектов. Теперь задействуем функцию cv2.findContours:
# находим контуры в изображении и подсчитываем число книг cnts = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[1] total = 0
Теперь несколько слов о геометрии книги. Как известно — это прямоугольник, который, соответственно, имеет 4 вершины. Следовательно, если при рассмотрении контура мы обнаружим наличие 4-х вершин, мы сможем предположить, что перед нами именно книга. Чтобы это проверить, надо выполнить цикл по каждому контуру:
# выполняем цикл по контурам for c in cnts: # сглаживаем контур peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.02 * peri, True) # если у контура есть четыре вершины, это, скорее всего, книга if len(approx) == 4: cv2.drawContours(image, [approx], -1, (0, 255, 0), 4) total += 1
При этом для каждого из контуров производится вычисление периметра (с помощью cv2.arcLength), а потом происходит аппроксимация (сглаживание) контура с помощью cv2.approxPolyDP.
Зачем выполняем аппроксимацию? Дело в том, что контур может и не быть идеальным прямоугольником, так как зашумление и тени на изображении всё же оказывают влияние. Когда мы аппроксимируем контур, мы эту проблему решаем.
В конце концов, мы осуществляем проверку, что у аппроксимируемого контура действительно есть 4 вершины. Если это так, мы рисуем вокруг книги контур с одновременным увеличением счётчика общего числа книг.
Давайте завершим этот пример и покажем полученное изображение и число книг, которые удалось найти:
# покажем результирующее изображение print("Я нашёл {0} книг на этой картинке".format(total) cv2.imwrite("output.jpg", image))
На этом этапе наше фото будет выглядеть так:

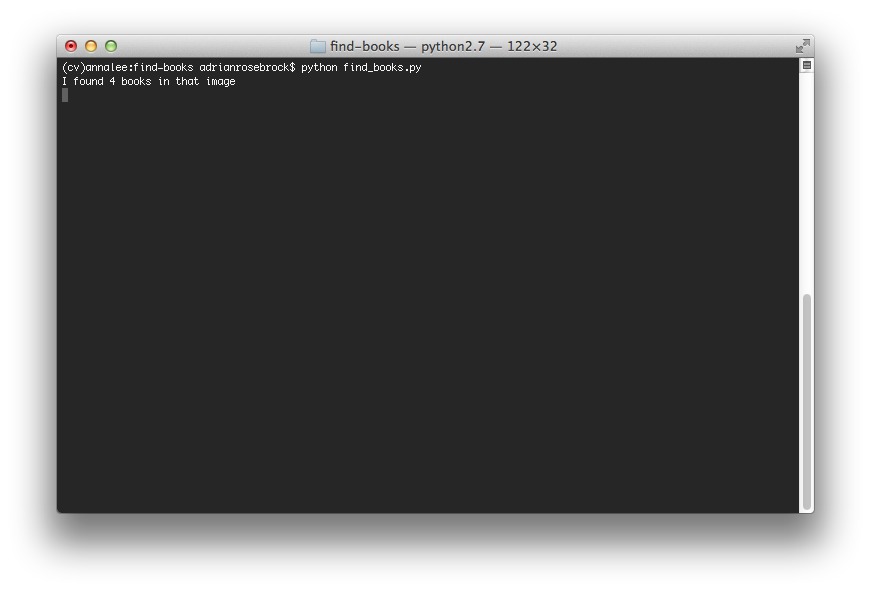
Что касается терминала, то он нам покажет, что мы успешно нашли 4 книги и проигнорировали посторонние предметы:
Делаем выводы
Итак, мы показали, как можно найти книги на фотографиях с помощью простых методов обработки изображений, а также компьютерного зрения, Python и OpenCV.
Кратко перескажем суть подхода: 1. Загружаем изображение с диска, преобразуем его в оттенки серого. 2. Немного размываем изображение. 3. Применяем детектор контуров Canny с целью обнаружения объектов на изображении. 4. Закрываем промежутки в контурах. 5. Находим контуры объектов на изображении. 6. Применяем контурную аппроксимацию для определения, был ли контур прямоугольником и, соответственно, книгой.
По материалам статьи «A guide to finding books in images using Python and OpenCV».