

Зачем Big Data нужен Kubernetes?
Контейнеризация обеспечивает нам непрерывную интеграцию и поставку ПО (CI/CD), что соответствует современному подходу DevOps. И правда, упаковав в контейнер программное окружение, мы сможем быстро развернуть микросервис на рабочем сервере, безопасно взаимодействуя с прочими приложениями. И многим хорошо знаком Docker Compose, позволяющий описывать и запускать многоконтейнерные приложения. Но если нам нужно обеспечить действительно сложный порядок запуска огромного количества таких контейнеров (допустим, нескольких тысяч, как это нередко бывает в Big Data-системах), то не обойтись без эффективного средства управления ими – инструмента оркестрации. Как раз в этом и заключается основное назначение Kubernetes.
Причём Kubernetes — это не просто фреймворк для оркестрации контейнеров, а полноценная платформа управления контейнерами, позволяющая параллельно запускать множество задач, которые распределены по тысячам приложений (микросервисов) и расположены на разных кластерах (клиентских серверах, публичном облаке, собственном дата-центре и т. п.).
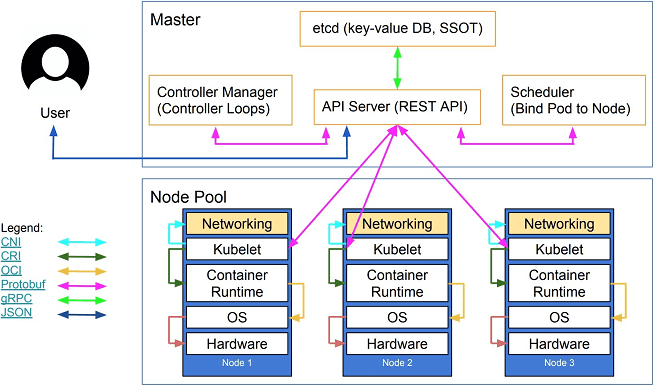
Контейнер в Kubernetes – это программный компонент самого низкого уровня абстракции, а для межпроцессного взаимодействия несколько контейнеров инкапсулируются в поды. И задача Kubernetes — динамически распределять ресурсы узла между подами, для чего на каждом узле посредством встроенного агента внутреннего мониторинга Kubernetes cAdvisor осуществляется непрерывный сбор данных об использовании ресурсов и производительности.
Что имеет особое значение для проектов Big Data, так это Kubelet – компонент Kubernetes, который работает на узлах, автоматически обеспечивая запуск, остановку и управление контейнерами, организованными в поды. В случае нахождения проблемы с каким-либо подом, Kubelet попытается повторно развернуть его и выполнить перезапуск.
Как и в случае с HDFS (популярная файловая система для решений Big Data), в Kubernetes-кластере любой узел регулярно посылает на master heartbeat message — сообщения диагностического характера. И если мастер обнаруживает сбой на каком-нибудь узле, Replication Controller старается перезапустить нужные поды на другом узле, который работает корректно.
Принципы работы Kubernetes:
Примеры использования Kubernetes
Как уже было сказано выше, K8s предназначается для управления множеством контейнеризированных микросервисов. Именно поэтому нет ничего удивительного в том, что такая технология приносит максимальную выгоду как раз в Big Data-проектах.
К примеру, Kubernetes используют: — сервис знакомств Tinder; — компания Huawei; — сервис поиска автомобильных попутчиков BlaBlaCar; — евроцентр ядерных исследований (CERN) и множество других компаний, которые работают с большими данными и нуждаются в современных инструментах для отказоустойчивого и быстрого развёртывания приложений.
Остаётся добавить, что из-за цифровизации предприятий и распространения DevOps-подхода, спрос на навыки владения Kubernetes также растёт и в отечественных компаниях. Вывод прост — Kubernetes сегодня — это must have для современного DevOps-инженера и разработчика Big Data.