

Лучевой поиск для seq2seq модели

В задачах машинного перевода часто используется модель seq2seq (sequence-to-sequence). Данная модель в режиме тестирования последовательно выдаёт распределения по вероятностям слов на текущем шаге t. Более подробно можно прочитать в предыдущей заметке. Далее я буду предполагать знакомство с этой моделью.
Сейчас нас будет интересовать механизм работы модели в режиме тестирования. Поскольку модель выдаёт не детерминированные предсказания, а только распределения по словам, то существует очень много последовательностей слов
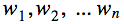 которые будут иметь схожую вероятность (вероятность последовательности – это произведение вероятностей отдельных слов). Напрямую перебрать все последовательности нереально: их
которые будут иметь схожую вероятность (вероятность последовательности – это произведение вероятностей отдельных слов). Напрямую перебрать все последовательности нереально: их
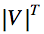 Где |V| – это размер словаря, а T – длина предложения. Поэтому прибегают к эмпирическим методам поиска.
Где |V| – это размер словаря, а T – длина предложения. Поэтому прибегают к эмпирическим методам поиска.
Одним из самых распространенных методов является «лучевой» поиск
Обозначения:

Псевдокод:
1. Выбираем размер «луча» k.
2. Выбираем функцию оценки для текущего шага f.
3. Инициализируем общий счётчик оценки A размером T х k
4. Инициализируем матрицу скрытых состояний декодера 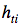 размером T х k
5. Инициализируем T матриц
размером T х k
5. Инициализируем T матриц 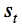 размером k х |V|
6. Непосредственно поиск:
размером k х |V|
6. Непосредственно поиск:
По t=0,..T:
По i=1,..k:
По всем возможным словам v=1,..V:
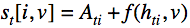
 Использование «луча» размером 2-10 обычно позволяет существенно увеличить качество перевода для seq2seq модели. Отметим, что при этом линейно будет расти вычислительная сложность.
Использование «луча» размером 2-10 обычно позволяет существенно увеличить качество перевода для seq2seq модели. Отметим, что при этом линейно будет расти вычислительная сложность.
Дополнительные материалы можно посмотреть здесь: 1. Поиск в пространстве состояний 2. A Continuous Relaxation of Beam Search for End-to-end Training of Neural Sequence Models 3. Формулы из заметки можно взять здесь.
Есть вопрос? Напишите в комментариях!