

NLP-конвейер
Некоторые задачи, возникающие при обработке естественного языка, ранее решались посредством классических ML-алгоритмов. В результате для решения большинства из них нужен был тщательный выбор архитектуры, не говоря уже о кропотливом ручном сборе и обработке признаков. Но сегодня нейросети способны выдавать более точные результаты, если сравнивать с теми же классическими моделями. К тому же, сформирован общий подход для решения NLP-задач -- NLP-конвейер.
Конвейер NLP -- что это?
Важно отметить, что реализация практически любой сложной задачи, как правило, предполагает построение пайплайна, то бишь конвейера.
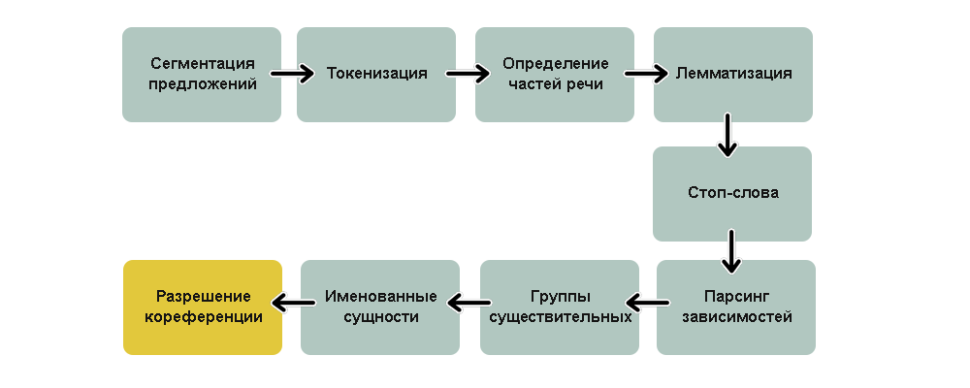
Суть такого подхода заключается в разбиении одной основной задачи на ряд последовательных подзадач, каждая из которых решается отдельно. При построении пайплайна можно выделить:
- предобработку входных данных;
- построение модели.
Рассмотрим основные этапы данного процесса:
1.Первые 2 шага пайплайна, выполняемые для решения практически любых NLP-задач, — сегментация (текст делится на предложения) и токенизация (предложения делятся на токены -- отдельные слова).
2.Вычисляются признаки каждого токена. Речь идет о вычислении контекстно-независимых признаков, то есть признаки не зависят от соседних с токеном слов.
Наиболее часто используемый признак — часть речи.

3.Определяется значимость и фильтрация стоп-слов. Речь идет о таких вспомогательных словах, как, к примеру, «and», «the», «a». Их отмечают в качестве стоп-слов и отсеивают.

4.Происходит разрешение кореференции. Существует множество местоимений типа he, she, it. Человек способен проследить взаимосвязь этих слов от предложения к предложению, тогда как NLP-модель не в курсе, что означают местоимения, так как рассматривает за раз лишь одно предложение.

5.Выполняется парсинг зависимостей. Цель — построить дерево, где каждый токен имеет единственного родителя. В качестве корня может быть главный глагол. Кроме того, надо установить тип связи между 2-мя словами:
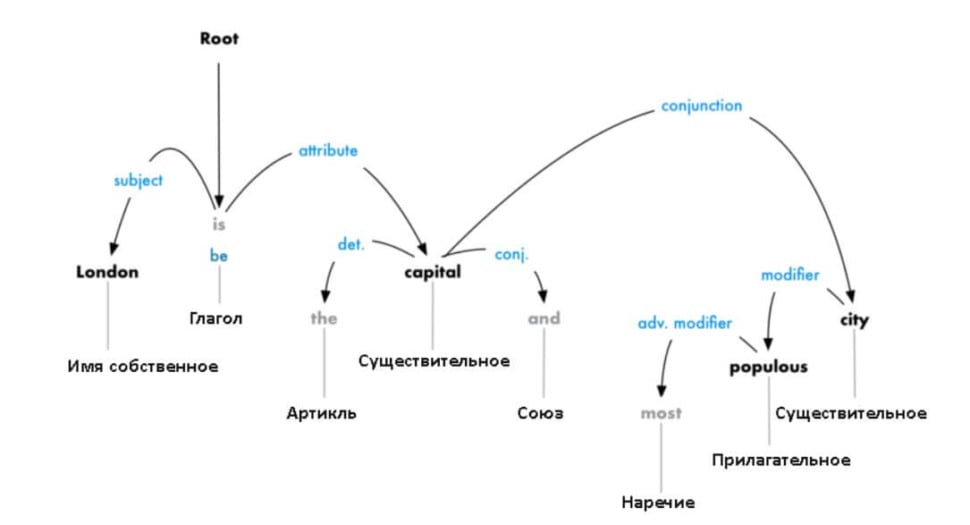
6.Перевод обработанного текста в форму вектора. Вышеуказанный шаг позволит сформировать векторные представления слов. Следовательно, у слов, применяемых в одном и том же контексте, векторы будут похожи.
7.Построение модели с учетом поставленной цели. В качестве примера можно привести модель для классификации либо генерации новых текстов.
На этом все, однако указанный пример построения пайплайна не единственно верный, т. к. все зависит от решения конкретной задачи. Тем не менее, описанный пайплайн представляет собой наиболее типичные подходы, которые позволяют извлекать максимальную практическую пользу из NLP.
По материалам https://tproger.ru.
P. S. Желаете освоить современные NLP-технологии? Добро пожаловать на авторский курс от Otus!