

Отличие метрики от функции потерь
Во время собеседования у начинающего ML-специалиста могут спросить, чем именно отличается метрика от функции потерь? Давайте разберемся.

Метрика — это то, что мы в действительности хотим минимизировать либо максимизировать. Понятно, что метрики бывают совершенно разные. Существуют продуктовые метрики (к примеру, доход) -- используя Machine Learning, их можно оптимизировать косвенно. Но вообще, как правило, в ML-курсах зачастую разговор идет про обычные офлайн-метрики, посредством которых мы понимаем, насколько хорошо решена задача.
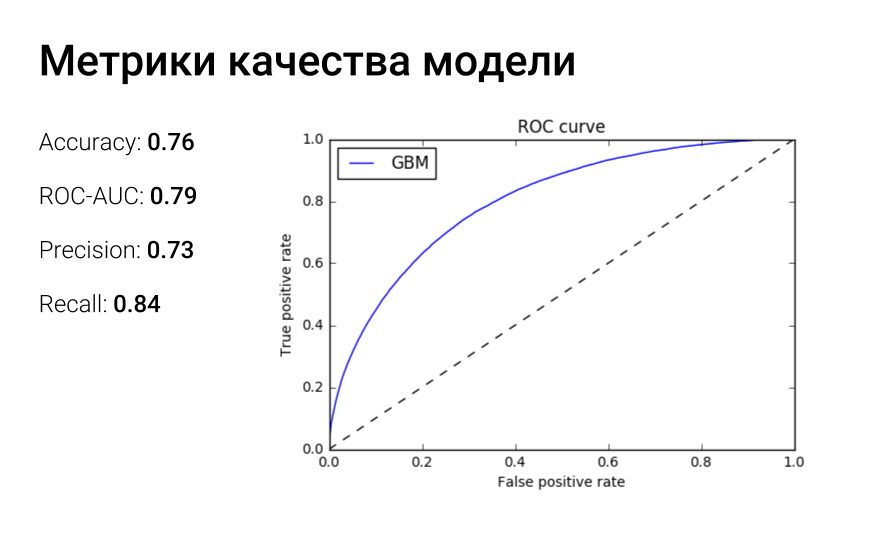
Идем далее. При измерении качества решения задачи бинарной классификации мы можем применять такие метрики, как accuracy (доля правильно классифицированных объектов), точность, полнота и т. п. Однако вышеперечисленные метрики имеют один весомый недостаток: они не являются дифференцируемыми, то есть невозможно оптимизировать их напрямую. Нам же хочется свести нашу задачу к оптимизации какого-нибудь хорошего функционала — таким образом и возникает функция потерь.
Иногда метрика и функция потерь совпадают. К примеру, в обоих качествах мы можем задействовать в задаче регрессии среднеквадратичную ошибку (MSE). Однако для задачи классификации, как мы уже рассмотрели выше, это не так.
По материалам tproger.ru.