

Массив как способ структурирования данных
Когда данные образованы в структуру, можно их эффективно обрабатывать и успешно ими управлять. В этой статье будет рассмотрена такая структура данных, как массив. Данный способ структурирования хорошо известен в программировании и широко используется для решения различных практических задач.
Что такое массив?
Массив (array) представляет собой структуру данных, содержащую упорядоченный набор однотипных элементов. Тут следует привести несколько коротких терминов: — элементы массива — его составляющие компоненты, которые расположены в смежных местах памяти — соответствующих ячейках памяти; — длина — общее число элементов; — индекс — обозначение (имя, номер) позиции отдельного элемента. Индекс — это ссылка, обеспечивающая доступ к соответствующему элементу; — размерность — количество индексов.
Концепция
Концептуальную схему этой структуры данных можно увидеть на картинке ниже:
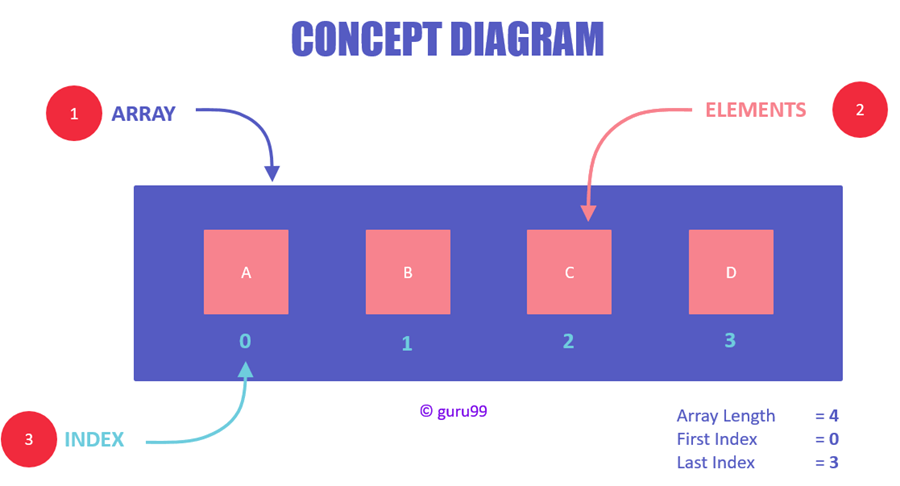
Что иллюстрирует диаграмма: 1. Массив можно назвать контейнером элементов. 2. У элементов есть значения, и они имеют определенный тип данных. 3. У каждого элемента есть свой индекс, который, как уже было сказано выше, применяется для выполнения доступа к этому элементу.
На очередной диаграмме можно увидеть, как объявляется массив в таких языках программирования, как Python и C ++. Глядя на синтаксис, можно сделать вывод, что при общей схожести возможны небольшие различия.
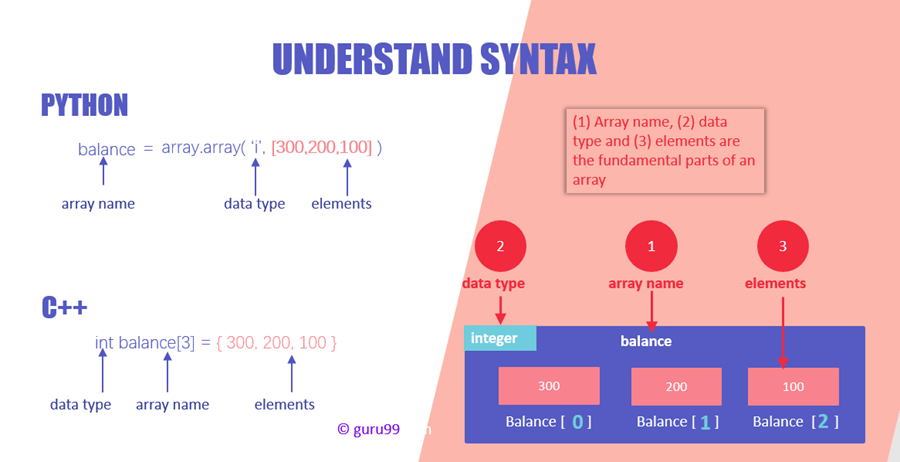
Объявление осуществляется тремя блоками данных: • именем массива (его можно в дальнейшем использоваться в качестве ссылки на коллекцию); • типом данных (к примеру, int (Integer), если речь идет о целых числах); • элементами — значениями данных.
Особенности массивов
Есть ряд общих свойств, которыми можно охарактеризовать array: • элементы хранятся в смежных ячейках памяти; • индекс обычно меньше, чем общее число элементов (это потому, что индексация начинается с нуля); • синтаксически, любая переменная, которая объявлена в качестве массива, способна хранить несколько значений; • практически все языки программирования имеют схожее «понимание» массивов, однако объявлять и инициализировать их они могут по-разному; • имя, тип данных и элементы — общие составляющие любых инициализаций.
Основные виды массивов по структуре
Структура данных может быть разной. Чаще всего сегодня используют одномерные и двумерные массивы. В одномерных у элемента есть только один индекс. Представим одномерный массив с именем A. Чтобы получить доступ к i-ому элементу, надо указать имя массива и индекс (номер) необходимого элемента: A[i].
В двумерном массиве (в матрице) структура представлена в виде таблицы. Доступ в матрицу производится также еще и по номерам строки и столбца, на пересечении которых и находится нужный элемент:
A[i, j]
Здесь A — имя массива, i – номер строки, j – номер столбца в матрице.
Хотя в различных языках программирования работа с такими структурами данных может отличаться, однако главные принципы в большинстве случаев неизменны. В известном языке Pascal обращение к 2-мерному массиву будет осуществляться именно так, как в примере выше: A[i, j]. А вот уже в языке C++ обращение будет следующим: A[i][j].
Какие еще бывают массивы?
Выше описывались массивы, которые относят к статическому типу — число элементов фиксировано и постоянно. Но есть и другие массивы, размер которых может меняться в процессе выполнения программы, — динамические. Они характеризуются непостоянностью размера, и это неплохо, ведь работа становится более гибкой. Но следует учесть, что сам процесс обработки таких структур усложняется, что не может не влиять и на быстродействие операции. Правило «За все нужно платить» никто не отменял.
Второй момент, который стоит упомянуть, связан с однородностью массива. Однородность — важный критерий статической структуры данных. Если же однородность отсутствует, такой массив называют гетерогенным. Использование гетерогенных структур оправдано во многих случаях, но имеет недостатки, которые справедливы для структур динамических.
Зачем они вообще нужны?
Для применения существует масса причин, вот 2 основные: • массивы — одна из наиболее подходящих структур для реализации в коде однотипных данных и хранения в одной переменной нескольких значений; • операция поиска в такой структуре данных является более простой и быстрой, то есть один из профитов заключается в том, что экономится время обработки.
Также стоит напомнить, что недостаточно просто выбрать в качестве структуры массив. Дополнительно нужно определиться и со способом его представления, ведь сам по себе массив — это лишь общее обозначение. Разработчику же надо выбирать наиболее подходящий вид массива с учетом поставленной задачи.
Еще не конец: данные других типов
Какие еще структуры данных следует знать: — связные (связанные) списки. Группа узлов, вместе образующих последовательность. Каждый узел включает в себя фактические данные (они хранятся и бывают представлены любым типом данных) и ссылку-указатель на следующий узел последовательности; — стеки. Так называемая «стопка книг». Можно вставлять либо удалять компоненты только из начала (невозможно взять интересующую книгу из середины стопки, предварительно не взяв книги, лежащие сверху); — очереди. Стоящий первым обслуживается первым (принцип FIFO — first in, first out); — множества. Данные хранятся без определенного порядка, причем значение не повторяются; — Map. Данные хранятся в парах ключ-значение, каждый ключ является уникальным; — хэш-таблицы. В данных этого типа реализуется интерфейс map, позволяющий хранить пары ключ-значение. Вычисление индекса происходит с помощью функции, называющейся хэш-функцией; — двоичное дерево поиска. Каждое дерево имеет корневой узел, последний имеет 0 либо более дочерних узлов, каждый дочерний узел имеет 0 либо более дочерних узлов и т. п.; — префиксное дерево. Своеобразное дерево поиска. Данные хранятся в шагах, каждый шаг — узел дерева. Часто применяется для хранения слов; — двоичная куча. В каждом узле не больше двух детей. Все уровни заполнены полностью; — графы. Совокупности узлов (их называют вершинами) и связей (их называют ребрами) между этими вершинами. Сами графы еще называют сетями.
Источники: • https://coderlessons.com/tutorials/kompiuternoe-programmirovanie/osnovy-algoritmov/3-massiv-v-strukturakh-dannykh; • https://proglib.io/p/data-structures/; • https://kvodo.ru/osnovnye-struktury-dannyh.html.
Нашли ошибку в тексте? Напишите об этом в комментарии!