

Алгоритм хеширования данных: просто о сложном
Криптографические хэш-функции распространены очень широко. Они используются для хранения паролей при аутентификации, для защиты данных в системах проверки файлов, для обнаружения вредоносного программного обеспечения, для кодирования информации в блокчейне (блок — основной примитив, обрабатываемый Биткойном и Эфириумом). В этой статье пойдет разговор об алгоритмах хеширования: что это, какие типы бывают, какими свойствами обладают.
В наши дни существует много криптографических алгоритмов. Они бывают разные и отличаются по сложности, разрядности, криптографической надежности, особенностям работы. Алгоритмы хеширования — идея не новая. Они появилась более полувека назад, причем за много лет с принципиальной точки зрения мало что изменилось. Но в результате своего развития хеширование данных приобрело много новых свойств, поэтому его применение в сфере информационных технологий стало уже повсеместным.
Что такое хеш (хэш, hash)?
Хеш или хэш — это криптографическая функция хеширования (function), которую обычно называют просто хэшем. Хеш-функция представляет собой математический алгоритм, который может преобразовать произвольный массив данных в строку фиксированной длины, состоящую из цифр и букв.
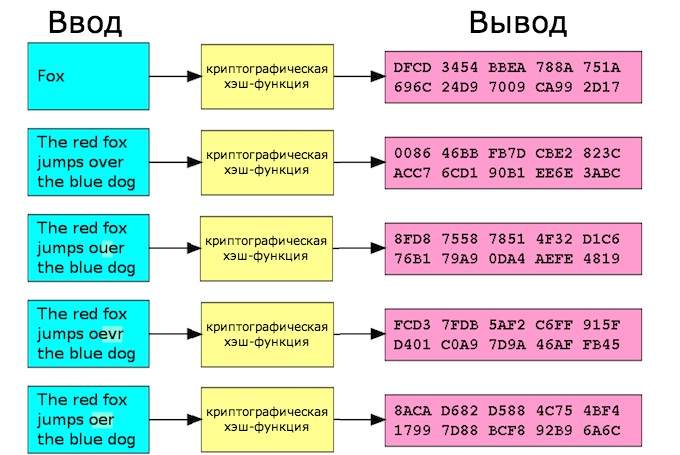
Основная идея используемых в данном случае функций — применение детерминированного алгоритма. Речь идет об алгоритмическом процессе, выдающем уникальный и предопределенный результат при получении входных данных. То есть при приеме одних и тех же входных данных будет создаваться та же самая строка фиксированной длины (использование одинакового ввода каждый раз приводит к одинаковому результату). Детерминизм — важное свойство этого алгоритма. И если во входных данных изменить хотя бы один символ, будет создан совершенно другой хэш.
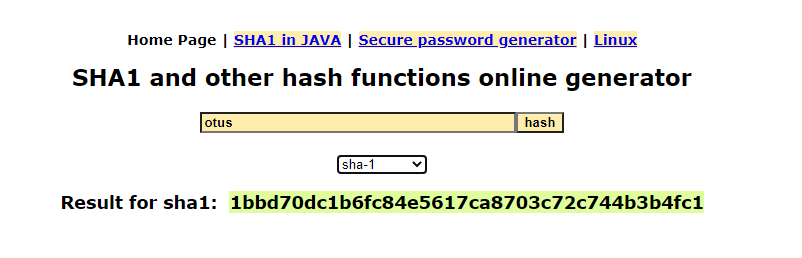
Убедиться в этом можно на любом онлайн-генераторе. Набрав слово «Otus» и воспользовавшись алгоритмом sha1 (Secure Hashing Algorithm), мы получим хеш 7576750f9d76fab50762b5987739c18d99d2aff7. При изменении любой буквы изменится и результат, причем изменится полностью. Мало того, если просто поменять регистр хотя бы одной буквы, итог тоже будет совершенно иным: если написать «otus», алгоритм хэш-функции отработает со следующим результатом: 1bbd70dc1b6fc84e5617ca8703c72c744b3b4fc1. Хотя общие моменты все же есть: строка всегда состоит из сорока символов.
В предыдущем примере речь шла о применении хэш-алгоритма для слова из 4 букв. Но с тем же успехом можно вставить слово из 1000 букв — все равно после обработки данных на выходе получится значение из 40 символов. Аналогичная ситуация будет и при обработке полного собрания сочинений Льва Толстого.
Криптостойкость функций хеширования
Говоря о криптостойкости, предполагают выполнение ряда требований. То есть хороший алгоритм обладает несколькими свойствами: — при изменении одного бита во входных данных, должно наблюдаться изменение всего хэша; — алгоритм должен быть устойчив к коллизиям; — алгоритм должен быть устойчив к восстановлению хешируемых данных, то есть должна обеспечиваться высокая сложность нахождения прообраза, а вычисление хэша не должно быть простым.
Проблемы хэшей
Одна из проблем криптографических функций хеширования — неизбежность коллизий. Раз речь идет о строке фиксированной длины, значит, существует вероятность, что для каждого ввода возможно наличие и других входов, способных привести к тому же самому хешу. В результате хакер может создать коллизию, позволяющую передать вредоносные данные под видом правильного хэша.
Цель хороших криптографических функций — максимально усложнить вероятность нахождения способов генерации входных данных, хешируемых с одинаковым значением. Как уже было сказано ранее, вычисление хэша не должно быть простым, а сам алгоритм должен быть устойчив к «атакам нахождения прообраза». Необходимо, чтобы на практике было чрезвычайно сложно (а лучше — невозможно) вычислить обратные детерминированные шаги, которые предприняты для воспроизведения созданного хешем значения.
Если S = hash (x), то, в идеале, нахождение x должно быть практически невозможным.
Алгоритм MD5 и его подверженность взлому
MD5 hash — один из первых стандартов алгоритма, который применялся в целях проверки целостности файлов (контрольных сумм). Также с его помощью хранили пароли в базах данных web-приложений. Функциональность относительно проста — алгоритм выводит для каждого ввода данных фиксированную 128-битную строку, задействуя для вычисления детерминированного результата однонаправленные тривиальные операции в нескольких раундах. Особенность — простота операций и короткая выходная длина, в результате чего MD5 является относительно легким для взлома. А еще он обладает низкой степенью защиты к атаке типа «дня рождения».
Атака дня рождения
Если поместить 23 человека в одну комнату, можно дать 50%-ную вероятность того, что у двух человек день рождения будет в один и тот же день. Если же количество людей довести до 70-ти, вероятность совпадения по дню рождения приблизится к 99,9 %. Есть и другая интерпретация: если голубям дать возможность сесть в коробки, при условии, что число коробок меньше числа голубей, окажется, что хотя бы в одной из коробок находится более одного голубя.

Вывод прост: если есть фиксированные ограничения на выход, значит, есть и фиксированная степень перестановок, на которых существует возможность обнаружить коллизию.
Когда разговор идет о сопротивлении коллизиям, то алгоритм MD5 действительно очень слаб. Настолько слаб, что даже бытовой Pentium 2,4 ГГц сможет вычислить искусственные хеш-коллизии, затратив на это чуть более нескольких секунд. Всё это в ранние годы стало причиной утечки большого количества предварительных MD5-прообразов.
SHA1, SHA2, SHA3
Secure Hashing Algorithm (SHA1) — алгоритм, созданный Агентством национальной безопасности (NSA). Он создает 160-битные выходные данные фиксированной длины. На деле SHA1 лишь улучшил MD5 и увеличил длину вывода, а также увеличил число однонаправленных операций и их сложность. Однако каких-нибудь фундаментальных улучшений не произошло, особенно когда разговор шел о противодействии более мощным вычислительным машинам. Со временем появилась альтернатива — SHA2, а потом и SHA3. Последний алгоритм уже принципиально отличается по архитектуре и является частью большой схемы алгоритмов хеширования (известен как KECCAK — «Кетч-Ак»). Несмотря на схожесть названия, SHA3 имеет другой внутренний механизм, в котором используются случайные перестановки при обработке данных — «Впитывание» и «Выжимание» (конструкция «губки»).
Что в будущем?
Вне зависимости от того, какие технологии шифрования и криптографические новинки будут использоваться в этом направлении, все сводится к решению одной из двух задач: 1) увеличению сложности внутренних операций хэширования; 2) увеличению длины hash-выхода данных с расчетом на то, что вычислительные мощности атакующих не смогут эффективно вычислять коллизию.
И, несмотря на появление в будущем квантовых компьютеров, специалисты уверены, что правильные инструменты (то же хэширование) способны выдержать испытания временем, ведь ни что не стоит на месте. Дело в том, что с увеличением вычислительных мощностей снижается математическая формализация структуры внутренних алгоритмических хэш-конструкций. А квантовые вычисления наиболее эффективны лишь в отношении к вещам, имеющим строгую математическую структуру.
Источники: • https://vc.ru/crypto/47132-algoritmy-heshirovaniya-prostoe-obyasnenie-slozhnogo; • https://www.kaspersky.ru/blog/the-wonders-of-hashing/3633/.