

Data Platform как тренд
Большие данные появляются тогда, когда дешевле хранить информацию, чем выбросить её. К тому же, современный человек склонен к накоплению данных. Но информацию надо не только хранить, а ещё и обрабатывать, получая полезный результат. Сегодня в это инвестируют, что помогает оптимизировать процессы и повышать эффективность бизнеса. Так как же оптимизировать обработку Big Data?
Решение № 1: DWH
Когда-то было принято складывать все имеющиеся данные в структурированные хранилища — data warehouse (DWH), а потом их анализировать. Что тут следует отметить: • бизнес-требования меняются сегодня очень быстро — быстрее, чем можно прогнозировать; • возникает сложность обработки неструктурированных данных (DWH для них – явно не лучшее решение); • хранение в DWH обходится дорого. Когда в хранилище помещается вся информация, мы и платим за всё, то есть мы платим даже за ненужную информацию. А некоторые специалисты утверждают, что лишь 20-35 % хранимой информации обладает реальной пользой. Таким образом мы имеем 65-80 % «паразитных» данных.
Решение № 2: Hadoop
Около десяти лет назад недостатки DWH были учтены, в результате чего появился Hadoop, а люди перешли к обработке неструктурированных данных посредством batch-процессинга. Это снизило расходы, но и принесло ряд минусов: • неэффективная обработка структурированных данных; • результат получается не сразу, да и стоит это недёшево.
Можно сказать, что если для задач очистки данных заметно дешевле Hadoop, то при построении enterprise data warehouse заметно дешевле DWH-решения.
Решение № 3: Data Lake
Озеро данных берёт лучшее из двух вышеописанных подходов. В этом случае данные предварительно обрабатываются (проходят фильтрацию) посредством Hadoop’ов, далее данные помещаются в DWH. Казалось бы, проблемы решены. Но на деле оказалось не так всё радужно: • слишком долго. Типичный data lake включает в себя множество компонентов, которые ещё надо уметь связать. На практике интеграция разрозненных компонентов занимает много времени, не говоря уже о разработке и построении таких кейсов; • плохой ROI — соответственно, требуются большие инвестиции; • недостаток экспертов по администрированию. Как известно, разработчики любят разрабатывать, но очень не любят администрировать. То же самое и со стеками big data: персонал, обслуживающий эти платформы, зачастую не имеет достаточной квалификации в конкретных нишевых стеках.
Фабрики по обработке данных
Трендовое решение – Data Platform/data fabrics. Компонентами такой фабрики могут быть Kafka и Hadoop Spark, а также хранилище данных и пакетная обработка, которые тесно интегрированы друг с другом. Именно таковой является концепция Data Platform. Концепция экономит время для достижения результата, позволяя получать готовый кейс (допустим, для обработки антиспама и логов). Таким образом, когда компания осуществляет внедрение подобных платформ, она получает не только и не столько технологию, сколько готовые рецепты.
Взаимодействие компонентов внутри Data Platform:
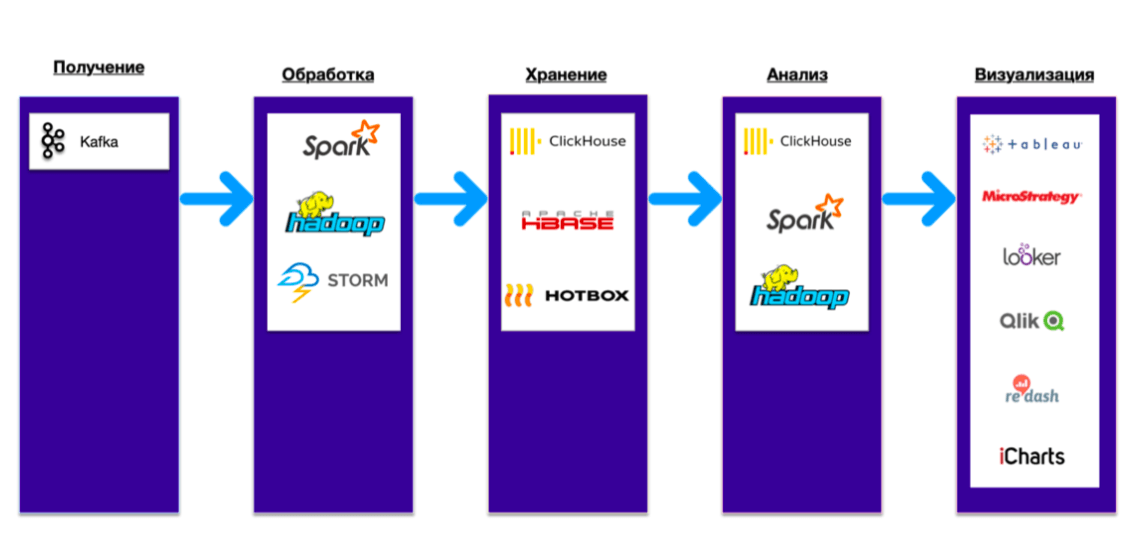
Итак, используя Data Platform компания получает готовые рецепты. Вот их перечень: • в области Big Data: поиск возможностей на рынке, предиктивная аналитика, ad-hoc data, mining; • в сфере бизнес-аналитики: анализ операционной деятельности, озёра данных, поддержка решений, data warehousing, ad-hoc-аналитика, ETL/ELT; • в машинном обучении: нейросети, Deep learning, искусственный интеллект, распознавание образов; • в области безопасности: выявление спама в комментариях и письмах, защита от злоумышленников, fraud detection; • в ритейле и e-commerce: анализ чеков, формирование специальных предложений, внешняя монетизация, управление поставками; • в телекоммуникациях: Customer 360, обработка CDR, оптимизация расходов, предиктивная аналитика неполадок; • в сфере финансов и банковского обслуживания: онлайн- и офлайн-скоринг, fraud detection, финансовый анализ.
Статья написана по материалам блога MCS.Mail.ru.