

Роль Apache Kafka в системах обработки данных
На сегодняшний момент почти в каждой компании, которая серьезно подходит к вопросам сбора и обработки данных, есть какой-либо брокер сообщений. Это может быть AWS Kinesis, Google PubSub или какой-то еще сервис. Но если мы говорим о компаниях, размещающих сервисы не в облаке, а на своей инфраструктуре, то в качестве брокера чаще всего выступает Apache Kafka.
Что такое Kafka?
Kafka — это сервис, позволяющий в реальном времени и с высокой пропускной способностью передавать сообщения между различными системами. Его используют для различных целей — передача данных в хранилище, потоковая аналитика, взаимодействие между сервисами и т. д.
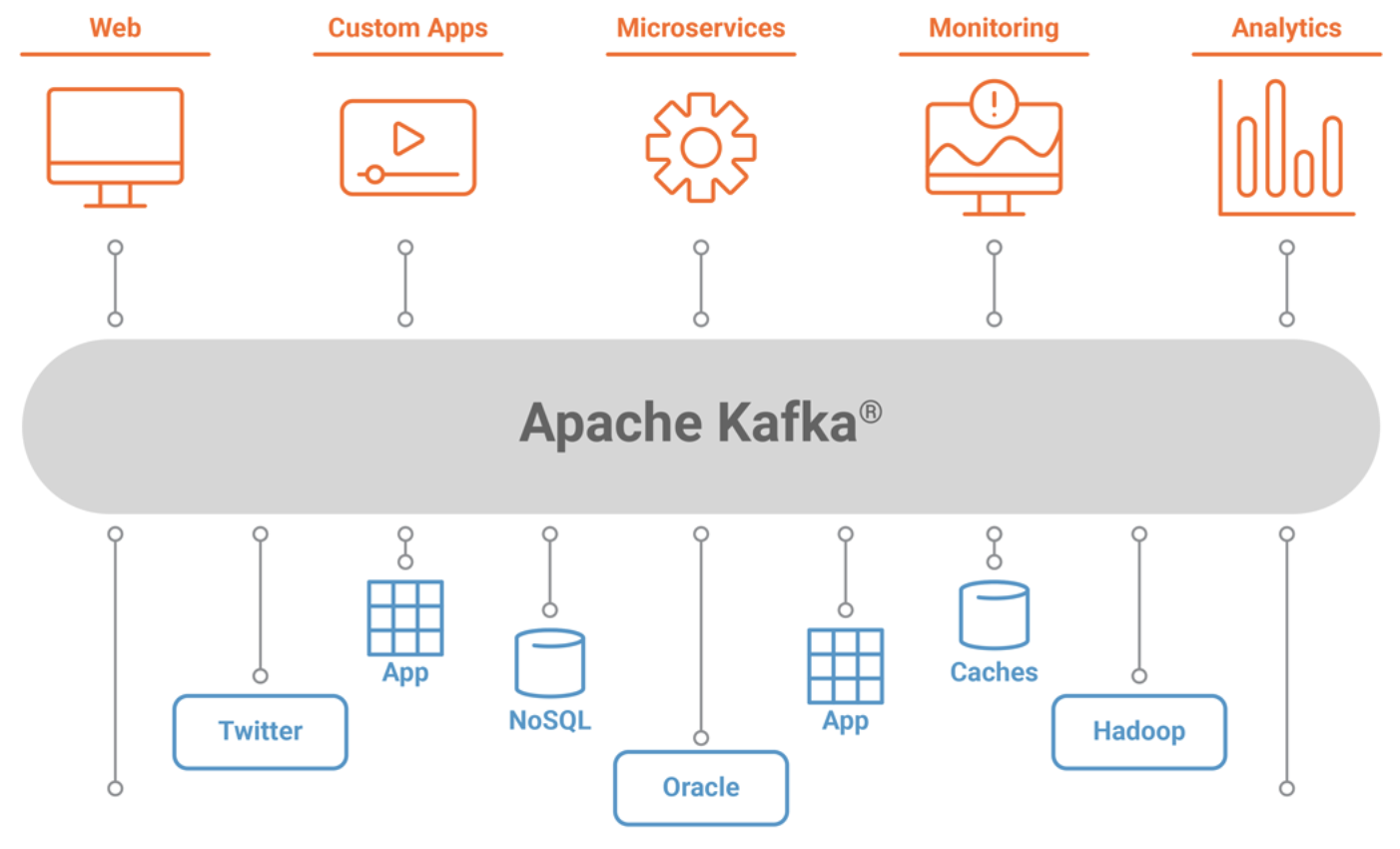
Кафка представляет из себя кластер из нескольких брокеров, каждый из которых обслуживает свою часть общей нагрузки. Каждый поток сообщений в Кафке называется “топик” (англ. topic). Например, в отдельный топик могут литься данные от веб-аналитики, фиксирующей заходы пользователей сайта, в отдельный — данные о заказах, в отдельный — факты подписок на рассылку. Каждый такой топик делится на партиции. Эти партиции равномерно распределяются по всем брокерам кластера для повышения пропускной способности. Клиент, пишущий в топик, называется “producer”, а читающий из топика — “consumer”.
Среди плюсов Кафки можно выделить следующие: ● Отказоустойчивость. ● Простота использования. ● Высокая пропускная способность. ● Горизонтальное масштабирование. ● Возможность долгосрочного хранения истории сообщений. ● Большое число интеграций для сервисов и библиотек для разных языков.
Роль Kafka в системах обработки данных
Главный вопрос, который может возникнуть, — зачем нам этот “посредник” между различными системами? Не проще ли будет отправлять данные напрямую? Это ведь дополнительная точка для потенциального отказа системы.
Приведем пару аргументов: 1. Кафка позволяет унифицировать протокол обмена данными между разными системами. Допустим, у вас есть 3 сервиса, поставляющие данные, и 2 сервиса, потребляющие данные. Часто потреблять данные нужно не из одного сервиса, а из нескольких. Между каждой парой сервисов придется писать отдельную интеграцию из-за разницы в реализациях (язык, тип базы и т. д.). В пределе количество таких “перемычек” между разными сервисами достигает 32 = 6. То есть нужно будет написать 6 разных коннекторов. Это выглядит просто. Но что, если систем будет 20 и 5? Это уже 255 = 100 коннекторов. И так далее. Кафка же дает универсальный интерфейс. Для каждого сервиса будет достаточно написать только интеграцию с кафкой. А это уже 20 + 5 = 25 перемычек, что намного проще. Не говоря о том, что для многих сервисов и языков интеграция с Кафкой уже реализована. 2. Кафка выступает временным хранилищем между источником и приемником. Если у вас произошла авария или вам нужно банально обновить приемник, вы можете не беспокоиться о потере данных при наличии Кафки. Данные из источника останутся в хранилище Кафки и их можно будет дочитать после запуска системы-приемника. 3. Кафка выступает “буфером” для нагрузки. Если источник внезапно выдал большой объем данных, система-приемник может упасть под нагрузкой. Если же между ними стоит Кафка, она примет на себя нагрузку и благодаря высокой отказоустойчивости и пропускной способности сможет принять и сохранить данные, пока система-приемник будет не спеша вычитывать их в своем темпе. 4. Кафка жизненно важна для реалтайм-аналитики, так как позволяет доставлять данные с очень низкими задержками. При попытке использовать обычную СУБД в качестве промежуточного хранилища для потоков данных вы очень быстро столкнетесь с высокой нагрузкой на базу и долгими задержками доставки данных. Кафка же была изначально создана именно для поставки потоков данных в режиме реального времени и позволяет добиться задержек в несколько миллисекунд. Кроме того, большинство фреймворков для потоковой обработки данных (Spark Streaming, Apache Flink) отлично интегрированы с Кафкой “из коробки”.
Заключение
На текущий момент Кафка стала обязательным элементом для реализации множества архитектур обработки данных. Крайне желательно внедрить Кафку, если: ● у вас сложная топология обмена данными, включающая большое число источников и приемников, основанных на различных технологиях; ● вам необходимо предоставлять аналитику в режиме реального времени; ● вы хотите повысить надежность вашей системы доставки данных.
Учитывая, что с каждым годом роль потоковой обработки данных и реалтайм-аналитики только увеличивается, необходимость внедрения Кафки или аналогичного брокера в систему обработки данных будет становиться всё более актуальной.