

Клиент-серверная архитектура в HighLoad-системах

Если сервис недоступен пользователям определённое время, это плохо, но не смертельно. Зато потерять данные клиента — попросту недопустимо. Именно поэтому важно скрупулёзно оценивать применяемые технологии хранения данных. Кроме того, важно обеспечить избыточность при построении клиент-серверной архитектуры. Об этом и поговорим.
Наиболее простым примером распределённой системы является классическая клиент-серверная модель. В нашем случае сервер является точкой синхронизации, которая даёт возможность осуществлять совместные и скоординированные действия сразу нескольким клиентам.
Рассмотрим упрощённую схему клиент-серверного взаимодействия:
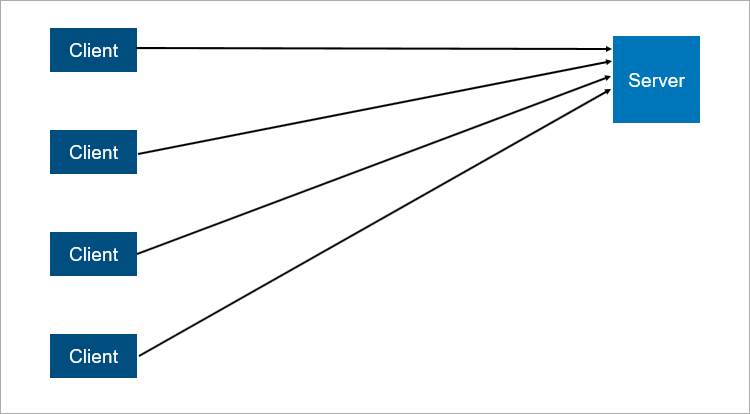
Что тут ненадёжного? Все мы знаем, что сервер может упасть. А когда это произойдёт, все клиенты работать не смогут. Дабы избежать этой ситуации, было придумано подключение master-slave (теперь его называют leader-follower). Суть проста: существуют 2 сервера, клиенты взаимодействуют с главным сервером, а на второй сервер осуществляется репликация данных.
Схема клиент-серверной архитектуры с репликацией данных на фолловера:
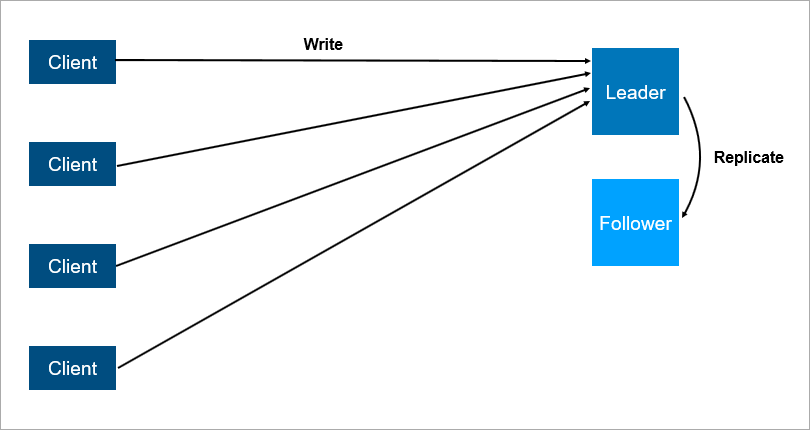
Разумеется, вышеописанная система надёжнее, ведь если главный сервер упадёт, на фолловере есть копия всех данных, которую можно быстро поднять.
Тут имеет значение и то, каким образом устроена репликация. Если репликация синхронная, транзакцию надо сохранять одновременно как на лидере, так и на фолловере, что бывает медленно. Если же репликация асинхронная, после аварийного переключения мы можем потерять часть данных.
Но давайте представим, что лидер упадет ночью во время спокойного и крепкого сна. Да, данные на фолловере есть, однако никто ведь фолловеру не сказал, что теперь он лидер, следовательно, клиенты к нему подключиться не смогут. Но мы можем наделить фолловер логикой, в результате чего он начнёт считать себя главным, когда будет потеряна связь с лидером. Но и здесь есть подводные камни: split brain — конфликт, при котором связь между лидером и фолловером нарушается, и оба начинают думать, что они являются главными.
Для решения вышеописанных проблем организуют auto failover — в этом случае добавляется третий, «свидетельский» сервер (witness). Такой сервер гарантирует наличие лишь одного лидера. Если же лидер отваливается, фолловер включится автоматически в кратчайшие сроки. Разумеется, в такой схеме клиенты должны знать адреса лидера и фолловера заранее. Также должна быть реализована логика автопереподключения между ними.
На схеме ниже видно, что witness гарантирует наличие одного лидера. И если лидер отваливается, включение фолловера происходит автоматически:
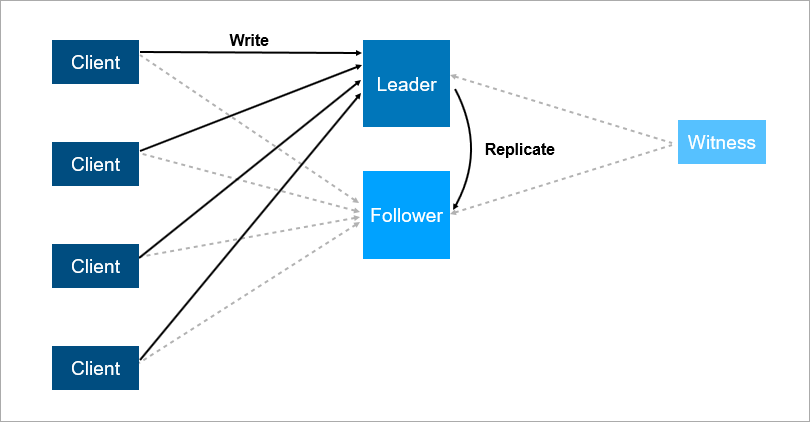
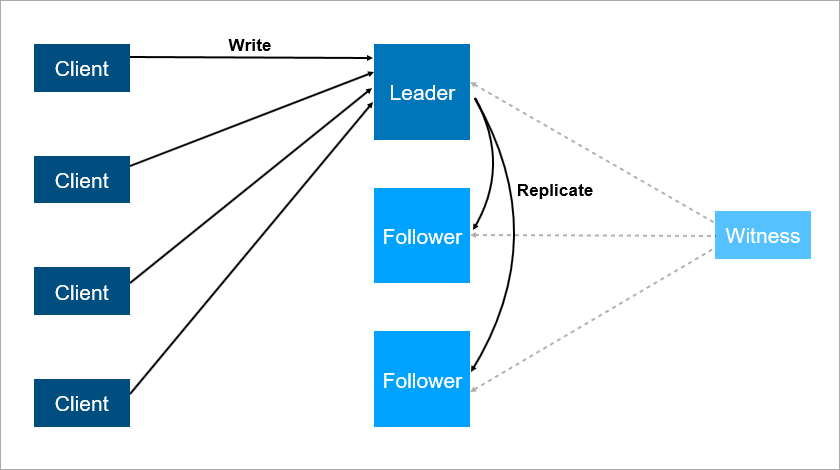
Но есть минусы и у этой схемы. Допустим, вы обновляете на лидер-сервере операционную систему. А до этого вручную переключили на фолловера нагрузку — вдруг он падает, и сервис становится недоступен. Это катастрофа… Чтобы от неё застраховаться, надо добавить 3-й резервный сервер — то есть мы говорим об ещё одном фолловере. Вуаля — надёжность увеличивается, то есть 2 сервера — это мало, лучше три: один на обслуживании, второй упал, но есть третий и катастрофы не происходит.
Вот, как это может выглядеть:
Делаем вывод
Итак, избыточность должна быть. Мало того, она должна быть равной двум, так как избыточности, которая равняется единице, явно недостаточно для достижения требуемого уровня надёжности. Кстати, именно поэтому в дисковых массивах стали вместо RAID5 использовать схему RAID6, которая переживает падение сразу 2-х дисков.
Статья подготовлена по материалам блога компании Pyrus.