
Кодирование информации – это процедура преобразования данных. Она относится к основным информационным процессам. Преобразование данных может производиться как с изменением содержания, так и без него. В первом случае пользователю предстоит иметь дело с новой информацией, во втором – с ее переводом с одного языка на другой, но с сохранением имеющегося смысла. Эта операция и называется кодированием.
Данные могут быть закодированы различными способами. Это необходимо для обеспечения более удобного представления сведений, а также сокрытия содержания. Кодирование может быть реализовано относительно самых разных данных – от обычного текста до видео и звука.
Далее предстоит изучить существующие текстовые кодировки. Особое внимание нужно уделить Unicode и UTF-8. Эти варианты шифрования цифровых материалов являются наиболее распространенными в современных компьютерах. Предложенная информация будет полезна как обычным ПК-пользователям, так и IT-специалистам.
Наиболее распространенные кодировки
Кодировкой символов называется процесс присваивания номеров графическим символам. Особенно это касается элементов человеческих языков. Числовые значения, формирующие кодировку, носят название «кодовых точек». Совместно они представляют собой так называемое «кодовое пространство» или «карту символов». Эти компоненты необходимы для шифрования и дешифрования информации.
Буквы и алфавит кодируются при помощи определенных стандартов. Они меняются в зависимости от выбранного человеком языка, а также от операционной системы на устройстве. Наиболее распространенными из них являются:
- ISO;
- ASCII;
- KOI-8;
- CP866;
- Windows 1251;
- Unicode.
Чаще всего пользователи и IT-специалисты имеют дело с ASCII и Unicode (он поддерживает несколько версий). Далее предложенные кодировки будут изучены более подробно. Особое внимание уделено Unicode, а также его разновидности UTF-8.
ASCII – базовая кодировка
ASCII (или «Аски») – это самый первый стандарт кодировки символов. Он предусматривает в своем составе английский алфавит (латиницу). Состоит из 128 уникальных символов. Их можно разделить на:
- печатные элементы;
- специальные (управляющие) символы.
ASCII – таблица, поддерживающая:
- арабские цифры;
- существующие знаки препинания;
- латинские буквы;
- служебные символы.
Данный стандарт предусматривает шифрование символов 7 битами, но со временем он был расширен до 1 байта (или 8 бит). Этот прием позволил задействовать уже не 128, а 256 разнообразных символов. Их можно было закодировать при помощи одного байта.
Существуют разнообразные расширенные ASCII-стандарты. Они начали включать в себя символы национальных языков, а не только ранее существующую латиницу.
ISO
ISO – стандарт, представленный 8 битами. Младшая группа символов здесь представляет собой «базовый» ASCII, а старшая группа отводится под разнообразные языки. Соответствующая кодировка является расширенной версией Аски.
Ее примерами могут быть такие варианты как:
- 8859-0 – новый европейский вариант;
- 8859-5 – поддержка кириллицы;
- 8859-1 – европейские языки и языки алфавита Латинской Америки;
- 8859-2 – Восточная Европа.
ISO 8859-5 – это самая первая попытка внедрения в цифровые устройства специального стандарта шифрования кириллицы. Он до сих пор встречается в некоторых организациях – тех, что занимаются разработкой программного обеспечения с поддержкой обработки кириллических символов. Примерами могут быть решения OpenVMS и разнообразные базы данных.
KOI8-R
Еще один расширенный вариант представления ASCII. Она предназначается для работы с символами русского алфавита. Этот стандарт является очень старым. Он появился раньше некоторых остальных.
Кириллица здесь располагается в верхней части ASCII так, чтобы произношение алфавита соответствовало аналогам английского алфавита в нижней части таблицы. Это значить, что, если убрать в тексте на KOI8 восьмой бит каждого элемента, в итоге получится хорошо читаемая информация, но на английском языке.
KOI8 поддерживает несколько диалектов:
- KOI8-R – для русского языка;
- KOI8-U – для украинского алфавита.
KOI8-R также поддерживает болгарскую кириллицу. С ее помощью удалось сформировать первые кириллические символы для цифровых и компьютерных устройств. На данный момент в Болгарии пользуется спросом другой стандарт – Windows -1251.
KIO8-R имеет огромный спрос в Интернете. Он может рассматриваться как полноценный стандарт для русской кириллицы в Сети.
CP866
Альтернативная кодировка от IBM. Это вторая попытка использовать символы русского алфавита в компьютерной технике. CP866 – это одна из расширенных версий ASCII.
Здесь первая часть полностью совпадает с базовой версией Аски, а нижняя часть позволяла закодировать дополнительные 128 символов. В них были включены как русские буквы, так и псевдографика.
Windows-1251
Windows -1251 – это еще одна расширенная версия ASCII. Данный стандарт был разработан корпорацией Microsoft. Появление соответствующей кодировки связано с ростом развития популярности графических операционных систем.
В Windows-1251 была убрана псевдографика. За счет этой особенности образовалась целая новая группа стандартов кодирования, которая выступала расширенной интерпретацией ASCII. Текстовые символы здесь могут быть зашифрованы при помощи всего 1 байта информации. Соответствующая группа была отнесена к ANSI-кодировкам. Они были разработаны американским институтом стандартизации. ANSI поддерживали не только кириллицу, но и русский алфавит. Windows-1251 – наглядный тому пример.
Вместо псевдографики здесь было выделено пространство для:
- славянских языков;
- знаков русской типографии.
В Windows-1251 отсутствует символ ударения. Совместимость с CP866 этот вариант не поддерживает.
Сейчас Windows-1251 активно используется в операционных системах Windows. Он чаще всего встречается в старых версиях ОС – начала 90-х годов. Кириллица в Windows-1251 отображается в алфавитном порядке.
Unicode
Unicode – это универсальный способ шифрования информации. Он появился из-за невозможности уместить в одном байте все языковые группы южно-восточной Азии. Unicode был разработан в 1991 году некоммерческой организацией «Консорциум Юникода».
Этот подход активно используется в Интернете. Коды в нем разделяются на несколько областей. Одна из них включает в себя символы ASCII. Далее размещаются символы других систем письменности, технические символы и разнообразные пунктуационные знаки. Некоторая часть кодов зарезервирована для использования в будущем.
Unicode имеет несколько версий:
- UTF-32;
- UTF-16;
- UTF-8.
Юникод можно рассматривать как частичную реализацию ISO. На данный момент он предусматривает около 40 000 распределенных под символы позиций из 65 535 доступных (по 2 байта на каждый элемент или букву). В 1998 году Unicode получил возможность шифрования и дешифрования знака «евро».
Далее предстоит рассмотреть версии Unicode более подробно. Особое внимание будет уделено UTF8 — как самому распространенному варианту Юникода.
UTF-32
Первая реализация Unicode. Цифра в ее названии указывает на биты, используемые для шифрования одного символа или знака. 32 бита – это 4 байта информации. Это значит, что для шифрования одной буквы в UTF-32 требуется 4 байта.
Данный подход привел к тому, что при переводе документа из ASCII в Unicode его вес значительно увеличивался. А именно – в 4 раза. Подобные изменения стали неоправданными – основная масса европейских стран не нуждалось в огромном количестве символов. UTF-32 со временем стал устаревать. Ему на замену пришел новый вариант Юникода.
UTF-16
UTF-16 – более совершенная и удобная разработка Unicode. По умолчанию он используется для всех символов, используемых в компьютерной технике. Здесь для шифрования одного символа необходимо использовать 2 байта или 16 бит.
Используя UTF-16, получится закодировать 65 536 символов. Они выступают базовым пространством всего Юникода. UTF-16 уменьшил размер исходного документа при преобразовании с ASCII в 2 раза, а не в 4.
UTF-16 все равно не принес особого удовлетворения. Особенно это касалось тех, кто говорит и пишет преимущественно на английском языке. Получаемые документы с использованием этого стандарта все равно были достаточно большими.
UTF-16 можно увидеть в любой Windows. Для просмотра соответствующей таблицы необходимо:
- Перейти в «Пуск».
- Посетить службу «Служебные». Она находится в разделе «Программы»–«Стандартные».
- Выбрать в открывшемся меню «Таблица…».
- В дополнительных параметрах открывшегося окна установить Юникод.
Кодировка UTF 16 в конечном итоге смогла поддерживать около 1 миллиона символов, доступных для шифрования. Но достаточно большой объем исходных файлов, в которых использовался рассматриваемый стандарт, привел к образованию новой версии Юникода.
Новая версия Unicode
UTF-8 – самая последняя версия Юникода. Она будет рассмотрена более подробно далее. UTF-8 – 8-битный формат преобразования Unicode. Он является одним из общепринятых и стандартизированных текстовых кодировок. С помощью него удается хранить символы в Unicode.
Соответствующая кодировка стала широко использоваться. Она встречается о веб-пространствах и операционных системах. UTF-8 появился 2 сентября 1992 года. Он также называется Юникодом с переменной длиной.
Несмотря на цифру 8 в названии стандарта, она все равно обладает разной длиной. Каждый символ может быть закодирован последовательностью от 1 до 6 байт включительно. Чаще всего стандарт требует до 4 байт для шифрования одного элемента текста.
Кириллица в этой версии Юникода кодируется при помощи 2 байт, а грузинские и символы некоторых других языков мира – 3 байтами и более.
UTF-8 обладает наилучшей совместимостью со старыми операционными системами, в которых использовались символы по 1 байту. Рассматриваемый стандарт выделяется тем, что он поддерживает базовую часть ASCII в своем составе. Это позволяет приложениям, не понимающим Юникод, работать с UTF-8.
Данный метод шифрования поддерживает не только совместимость с Аски, но и любые 7-битные символы. Они будут отображаться «как есть». Остальные выдают пользователям мусор (шум). Из-за этого, если в дешифрованном документе много пространства занимают знаки препинания, пробел и латинские буквы, новый стандарт выигрывает по объему по сравнению с UTF-16.
Принцип кодирования
Зашифровать информацию при помощи UTF-8 получится в несколько шагов. Этот принцип стандартизирован в RFC 3629. Он включает в себя следующие шаги:
- Определить количество байтов (так называемых октетов), необходимых для шифрования того или иного символа. Номер элемента нужно взять из стандарта Unicode.
- Установить старшие биты первого октета так, чтобы они соответствовали количеству необходимых октетов, определенных на предыдущем шаге. Это приводит к тому, что нужно использовать записи: 0xxxxxxx – для шифрования с одним октетом, 110xxxxx – для двух октетов, 1110xxxx – при трех байтах и 11110xxx – если нужно использовать 4 октета.
- Если для шифрования необходимо выделить более одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 10xxxxxx. За счет этого удается легко отличить первый октет в потоке. Его старшие биты никогда не будут равны 10xxxxxxx.
- Установить значащие биты октетов в соответствии с номером символа Юникода, представленном в двоичном коде. Заполнение начинается с младших битов номера символа. Они подставляются в младшие биты последнего октета. Далее операция продолжается справа налево до первого октета. Свободные биты первого октета требуется заполнить нулями.
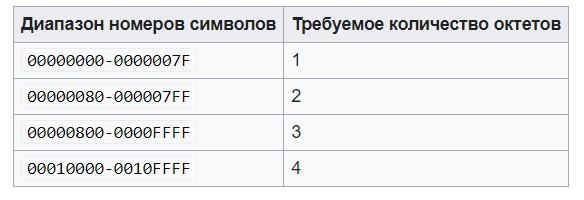
Выше можно увидеть таблицу, которая поможет выполнить первый шаг в заданном алгоритме при определении октетов.
Алгоритм дешифрования
Основы 8-битного кодирования были представлены выше. Текст, зашифрованный в UTF8, необходимо расшифровывать для дальнейшего использования. Организации и частные лица часто пользуются для этого специальными программами-декодировщиками. Они могут быть созданы при помощи самых разных языков программирования.
Примером может послужить сервис «Декодер онлайн». Пользоваться им рекомендуется так:
- Выставить в левой части в выпадающем списке под «Декодер онлайн» значение UTF-8.
- Указать форму представления преобразованного исходного текста.
- Вставить в пустую область (в поле слева) данные, которые требуется расшифровать.
- Нажать на кнопку «Расшифровать».
Результат преобразования появится в окне справа. Самостоятельно дешифрование проводить не рекомендуется – это долгий и не всегда простой процесс.
Установка в HTML и PHP
UTF-8 – версия Юникода с переменной длиной. Она предусматривает шифрование разным количеством байт. Данный вариант широко используется в Интернете. Примером могут послужить веб-страницы.
Чтобы установить UTF8 для HTML-документа, необходимо задействовать тег <meta>. Он помогает объединять в себе значения метатегов в виде атрибутов.
Метатеги нужны при передаче и хранении информации, предназначенной для браузеров, а также различных поисковых систем. У <meta> есть атрибут charset. Он поможет установить кодировку веб-сайта:

UTF-8 и другие форматы кодировок можно задавать отдельным элементам на сайте. Примером служит ссылка. Для реализации задачи необходимо также использовать атрибут charset. Его значение – это желаемый способ кодирования:

Многие страницы в Интернете являются динамически созданными. Для их формирования используются серверные языки разработки. Наиболее распространенным вариантом является PHP. У него есть функция header(), используемая для установки и модификации значений заголовка. Она предусматривает следующий синтаксис:

Для корректного задания в PHP кодировки UTF-8 необходимо использовать вызов header() в исходном коде выше всех остальных HTML-тегов/
Работа с базами данных
Рассматриваемый вид Юникода, использующий от 1 до 6 байт для шифрования, часто встречается при работе с базами данных. Далее будет приведен пример выставления UTF-8 в MySQL. Эта СУБД выступает наиболее распространенной среди всех существующих. Она часто используется в сайтостроении.
Для установки UTF-8 с переменным количеством байт необходимо использовать документ my.ini. Его можно обнаружить по пути:/usr/local/mysql-5.5. В соответствующем документе необходимо поменять значение сразу нескольких полей на UTF-8:
- default-character-set;
- character-set-server;
- init-connect = «set names».
После этого предстоит добавить строчку skip-character-set-client-handshake. Аналогичные изменения можно применять не только для всех баз данных сервера, но и для отдельно взятых БД. Для этого нужно действовать через пользовательский интерфейс оболочки PHPMyAdmin.
Какие кодировки существуют для современных компьютеров и сколько байт они используют для шифрования одного символа, понятно. Лучше разобраться с UTF-8, ASCII и другими методами кодирования помогут специальные компьютерные курсы.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!


