

Мифы про Count(1) vs Count(*)

Многие наверняка знают про то, что если написать Count(*) по таблице, получите количество строк в таблице. Довольно часто я встречаю мнение, что лучше писать Count(1), так как это будет использовать меньше ресурсов сервера, потому что вы указываете скалярное выражение вместо всех полей таблицы.
Так что же использовать?
SELECT COUNT(*) FROM Sales.CustomerTransactions; Или же SELECT COUNT(1) FROM Sales.CustomerTransactions;
Возможно, когда-то для некоторых СУБД это было правдой и Count(1) экономил ресурсы, но не для SQL Server — даже в далёкой версии 2005 оба выражения работали одинаково эффективно.
Давайте в этом убедимся
Выполним запрос и посмотрим на актуальный план:
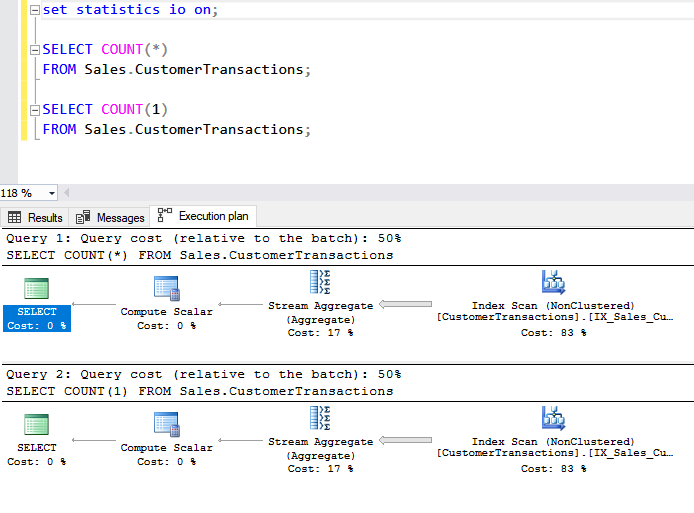 Видим, что план одинаковый и оптимизатор оценивает стоимость выполнения обоих запросов, как равную. Теперь посмотрим на часть по статистике ввода-вывода:
Видим, что план одинаковый и оптимизатор оценивает стоимость выполнения обоих запросов, как равную. Теперь посмотрим на часть по статистике ввода-вывода:
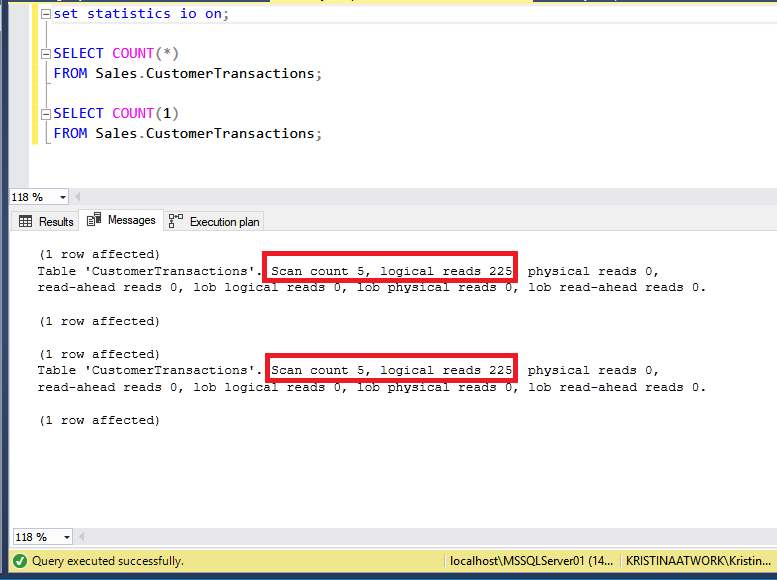
Количество сканирований и логических чтений для обоих запросов абсолютно идентично. Значит оба варианта равноценны по производительности для SQL Server. Обращаю внимание, что для других РСУБД результат может быть иной.
Миф о том, что Count(1) менее ресурсоёмкий возник довольно давно и связан с тем, что символ звездочка
Также есть ситуации, когда пишут
А вы используете в своем проекте Count(1)? Пишите в комментариях!