

Как анализировать тональность твитов с помощью машинного обучения на PHP
Оригинал статьи: ссылка
Всем доброго!
Что ж, как и обещали, делимся с вами очередным материалом, который мы изучали в рамках подготовки нашего курса по PHP. Надеемся, что он окажется для вас и интересным, и полезным.

Вступление
В последнее время кажется, что все и каждый говорят о машинном обучении. Ваши ленты в социальных сетях забиты сообщениями об ML, Python, TensorFlow, Spark, Scala, Go и т. д .; и если у нас с вами есть что-то общее, то вы можете поинтересоваться, а что насчет PHP?
Да, как насчет машинного обучения и PHP? К счастью, кто-то был достаточно сумасшедшим, чтобы не только задать этот вопрос, но и разработать универсальную библиотеку машинного обучения, которую мы можем использовать в нашем следующем проекте. В этом посте мы рассмотрим PHP-ML — библиотеку для машинного обучения на PHP — и мы напишем класс анализа тональности, который мы сможем позже использовать для нашего собственного чата или твит-бота. Основными задачами этого поста являются:
- Изучение общих понятий, касающиеся машинного обучения и анализа тональности текста
- Обзор возможностей и недостатков PHP-ML
- Определение задачи, которую мы будем решать.
- Доказательство того, что попытка машинного обучения на PHP не является абсолютно безумной целью (опционально)
Что такое машинное обучение?
Машинное обучение — это подмножество области исследований искусственного интеллекта, которое фокусируется на предоставлении «компьютерам возможности учиться, не будучи точно запрограммированным». Это достигается с помощью общих алгоритмов, которые могут «учиться» из определенного набора данных.
Например, одним из распространенных способов использования машинного обучения является классификация. Алгоритмы классификации используются для размещения данных в разных группах или категориях. Некоторые примеры приложений классификации:
- Почтовые спам-фильтры
- Пакеты сегментации рынка
- Системы защиты от мошенников
Машинное обучение — общий термин, который охватывает множество универсальных алгоритмов для разных задач. Есть два основных типа алгоритмов, классифицированных по тому, как они учатся — обучение с учителем и обучение без учителя.
Обучение с учителем
В обучении с учителем мы тренируем наш алгоритм с использованием обучающих данных в виде входного объекта (вектора) и желаемого выходного значения; алгоритм анализирует данные обучения и создает так называемую целевую функцию, которую мы можем применить к новому, немаркированному набору данных.
В оставшейся части этого поста мы сосредоточимся на обучении с учителем, просто потому, что оно наглядней и легче проверять отношения; имейте в виду, что оба алгоритма одинаково важны и интересны; иные утверждают, что обучение без учителя более полезно, поскольку оно исключает необходимость обучающих данных.
Обучение без учителя
Этот тип обучения, напротив, работает без обучающих данных с самого начала. Мы не знаем желаемых результирующих значений набора данных, и мы позволяем алгоритму делать выводы только по выборке; обучение без учителя особенно удобно для выявления скрытых закономерностей в данных.
PHP-ML
Представляю вам PHP-ML, библиотеку, которая утверждает, что является новым подходом к машинному обучению на PHP. Библиотека реализует алгоритмы, нейронные сети и инструменты для предварительной обработки данных, перекрестной проверки и извлечения признаков.
Я буду первым, кто заметит, что PHP — необычный выбор для машинного обучения, поскольку сильные стороны языка не очень хорошо подходят для реализаций машинного обучения. Тем не менее, не все приложения для машинного обучения должны обрабатывать петабайты данных и делать массивные вычисления — для простых приложений нам должно хватить PHP и PHP-ML
Лучший вариант использования, который я могу представить для этой библиотеки прямо сейчас, — это реализация классификатора, будь то что-то вроде спам-фильтра или даже анализа тональности текста. Мы собираемся определить проблему классификации и поэтапно выработать решение, чтобы узнать, как мы можем использовать PHP-ML в наших проектах.
Задача
Чтобы проиллюстрировать процесс внедрения PHP-ML и добавить некоторое машинное обучение в наши приложения, я хотел найти интересную задачу для решения и лучший способ продемонстрировать классификатор — создание класса анализа тональности твитов.
Одним из ключевых требований, необходимых для создания успешных проектов машинного обучения, является достоверный исходный набор данных. Наборы данных имеют решающее значение, поскольку они позволят нам обучать наш классификатор по уже классифицированным примерам. Поскольку в последнее время в средствах массовой информации вокруг авиакомпаний произошел значительный шум, что может подойти лучше, чем твиты от клиентов авиакомпаний?
К счастью, данные в виде набора твитов уже доступны нам благодаря Kaggle.io. С помощью этой ссылки вы можете скачать базу данных твиттера US Airline Sentiment с их сайта.
Решение
Давайте начнем с изучения набора данных, над которым мы будем работать. Необработанный набор данных имеет следующие столбцы:
- tweet_id
- airline_sentiment
- airline_sentiment_confidence
- negativereason
- negativereason_confidence
- airline
- airline_sentiment_gold
- name
- negativereason_gold
- retweet_count
- text
- tweet_coord
- tweet_created
- tweet_location
- user_timezone
И выглядит как в примере:
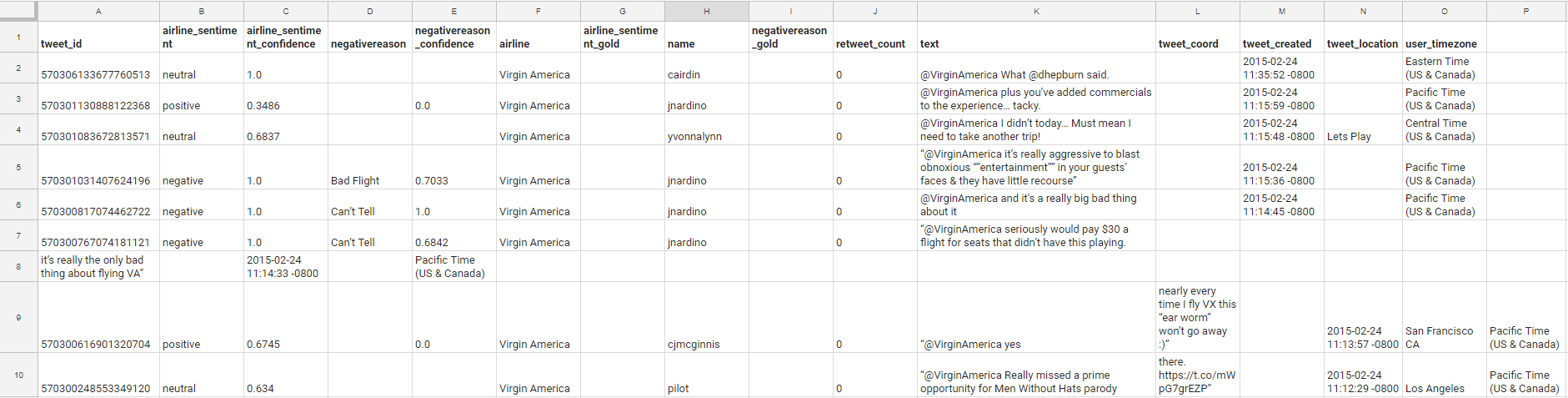
Файл содержит 14 640 твитов — для нас это достаточный набор данных. Теперь, имея такое количество доступных нам столбцов, у нас есть больше данных, чем нам нужно для нашего примера; для практических целей нас интересуют только следующие столбцы:
- text
- airline_sentim
Где text — свойство, а airline_sentiment — цель. Остальные столбцы можно отбросить, поскольку они не будут использоваться для нашего упражнения. Начнем с создания проекта и инициализации сборщика, используя следующий файл:
{ "name": "amacgregor/phpml-exercise", "description": "Example implementation of a Tweet sentiment analysis with PHP-ML", "type": "project", "require": { "php-ai/php-ml": "^0.4.1" }, "license": "Apache License 2.0", "authors": [ { "name": "Allan MacGregor", "email": "amacgregor@allanmacgregor.com" } ], "autoload": { "psr-4": {"PhpmlExercise\\": "src/"} }, "minimum-stability": "dev" }
composer install
Если вам нужно введение в Composer, см. здесь.
Чтобы убедиться, что мы установили все правильно, давайте создадим быстрый скрипт, который будет загружать наш файл данных Tweets.csv и убедимся, что он содержит нужные нам данные. Скопируйте следующий код как reviewDataset.php в корень нашего проекта:
<?php namespace PhpmlExercise; require __DIR__ . '/vendor/autoload.php'; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('datasets/raw/Tweets.csv',1); foreach ($dataset->getSamples() as $sample) { print_r($sample); }
Теперь запустим скрипт reviewDataset.php, и посмотрим на результат:
Array( [0] => 569587371693355008 ) Array( [0] => 569587242672398336 ) Array( [0] => 569587188687634433 ) Array( [0] => 569587140490866689 )
Пока что это не выглядит полезным, не так ли? Давайте посмотрим на класс CsvDataset, чтобы лучше понять, что происходит внутри:
<?php public function __construct(string $filepath, int $features, bool $headingRow = true) { if (!file_exists($filepath)) { throw FileException::missingFile(basename($filepath)); } if (false === $handle = fopen($filepath, 'rb')) { throw FileException::cantOpenFile(basename($filepath)); } if ($headingRow) { $data = fgetcsv($handle, 1000, ','); $this->columnNames = array_slice($data, 0, $features); } else { $this->columnNames = range(0, $features - 1); } while (($data = fgetcsv($handle, 1000, ',')) !== false) { $this->samples[] = array_slice($data, 0, $features); $this->targets[] = $data[$features]; } fclose($handle); }
Конструктор CsvDataset принимает три аргумента:
- Путь к исходному CSV-файлу
- Целое число, определяющее количество свойств в нашем файле
- Логическое значение, указывающее, является ли первая строка заголовком
Если посмотреть немного внимательнее, мы увидим, что класс делит CSV-файл на два внутренних массива: образцы и цели. Образцы содержат все функции, предоставляемые файлом, а цели содержат известные значения (отрицательные, положительные или нейтральные).
Исходя из вышесказанного, мы можем видеть, что формат, которым должен следовать наш CSV-файл, выглядит следующим образом:
| feature_1 | feature_2 | feature_n | target |
Нам нужно будет создать чистый набор данных только с теми столбцами, с которыми нам нужно продолжать работать. Давайте назовем этот скрипт generateCleanDataset.php:
<?php namespace PhpmlExercise; require __DIR__ . '/vendor/autoload.php'; use Phpml\Exception\FileException; $sourceFilepath = __DIR__ . '/datasets/raw/Tweets.csv'; $destinationFilepath = __DIR__ . '/datasets/clean_tweets.csv'; $rows =[]; $rows = getRows($sourceFilepath, $rows); writeRows($destinationFilepath, $rows); /** * @param $filepath * @param $rows * @return array */ function getRows($filepath, $rows) { $handle = checkFilePermissions($filepath); while (($data = fgetcsv($handle, 1000, ',')) !== false) { $rows[] = [$data[10], $data[1]]; } fclose($handle); return $rows; } /** * @param $filepath * @param string $mode * @return bool|resource * @throws FileException */ function checkFilePermissions($filepath, $mode = 'rb') { if (!file_exists($filepath)) { throw FileException::missingFile(basename($filepath)); } if (false === $handle = fopen($filepath, $mode)) { throw FileException::cantOpenFile(basename($filepath)); } return $handle; } /** * @param $filepath * @param $rows * @internal param $list */ function writeRows($filepath, $rows) { $handle = checkFilePermissions($filepath, 'wb'); foreach ($rows as $row) { fputcsv($handle, $row); } fclose($handle); }
Ничего сложного, достаточно, чтобы выполнить эту работу. Давайте выполним его с помощью phpgenerateCleanDataset.php.
Теперь давайте двигаться дальше и укажем нашему скрипту reviewDataset.php на чистый набор данных:
Array ( [0] => @AmericanAir That will be the third time I have been called by 800-433-7300 an hung on before anyone speaks. What do I do now??? ) Array ( [0] => @AmericanAir How clueless is AA. Been waiting to hear for 2.5 weeks about a refund from a Cancelled Flightled flight & been on hold now for 1hr 49min )
БАМ! Это те данные, с которыми мы можем работать! До сих пор мы создавали простые скрипты для управления данными. Дальше мы создадим новый класс в src/class/SentimentAnalysis.php.
<?php namespace PhpmlExercise\Classification; /** * Class SentimentAnalysis * @package PhpmlExercise\Classification */ class SentimentAnalysis { public function train() {} public function predict() {} }
Наш класс Sentiment будет нуждаться в двух функциях в нашем классе анализа тональности:
- Обучающая функция, которая будет принимать образцы и метки набора данных, а также некоторые дополнительные параметры.
- Функция прогнозирования, которая будет принимать немаркированный набор данных и назначить набор меток на основе данных обучения.
В корне проекта создайте скрипт classifyTweets.php. Мы будем использовать его для создания и тестирования нашего класса анализа тональностей. Вот шаблон, который мы будем использовать:
<?php namespace PhpmlExercise; use PhpmlExercise\Classification\SentimentAnalysis; require __DIR__ . '/vendor/autoload.php'; // Step 1: Load the Dataset // Step 2: Prepare the Dataset // Step 3: Generate the training/testing Dataset // Step 4: Train the classifier // Step 5: Test the classifier accuracy
Шаг 1. Загрузка набора данных
У нас уже есть базовый код, который мы можем использовать для загрузки CSV в объект данных из наших предыдущих примеров. Мы будем использовать тот же код с несколькими незначительными изменениями:
<?php ... use Phpml\Dataset\CsvDataset; ... $dataset = new CsvDataset('datasets/clean_tweets.csv',1); $samples = []; foreach ($dataset->getSamples() as $sample) { $samples[] = $sample[0]; }
Здесь создается массив, содержащий только свойства — в данном случае текст твита, который мы собираемся использовать для обучения нашего классификатора.
Шаг 2: Подготовка набора данных
Сейчас передача необработанного текста в классификатор приведёт к потере пользы и точности, поскольку твиты существенно отличаются друг от друга. К счастью, существуют способы работы с текстом при попытке применить алгоритмы классификации или машинного обучения. В этом примере мы будем использовать следующие два класса:
- Token Count Vectorizer: этот класс преобразует коллекцию образцов текста в вектор количества токенов. По сути, каждое слово в нашем твитте становится уникальным числом и отслеживается количество вхождений слова в конкретном образце текста.
- Tf-idf Transformer: сокращение для term frequency – inverse document frequency(частота слова – обратная частота вхождения слова в документ), представляет собой числовую статистику, используемую для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса.
Начнем с нашего векторизатора текста:
<?php ... use Phpml\FeatureExtraction\TokenCountVectorizer; use Phpml\Tokenization\WordTokenizer; ... $vectorizer = new TokenCountVectorizer(new WordTokenizer()); $vectorizer->fit($samples); $vectorizer->transform($samples);
Затем применим Tf-idf Transformer:
<?php ... use Phpml\FeatureExtraction\TfIdfTransformer; ... $tfIdfTransformer = new TfIdfTransformer(); $tfIdfTransformer->fit($samples); $tfIdfTransformer->transform($samples);
Наш массив образцов теперь находится формате, понятном нашему классификатору. Мы еще не закончили, нам нужно пометить каждый образец соответствующим настроением.
Шаг 3. Создание набора учебных материалов
К счастью, PHP-ML уже умеет это делать, и код довольно прост:
<?php ... use Phpml\Dataset\ArrayDataset; ... $dataset = new ArrayDataset($samples, $dataset->getTargets());
Мы могли бы использовать этот набор данных и обучать наш классификатор. Однако нам не хватает набора тестовых данных для использования в качестве проверки, поэтому мы собираемся немного «считтерить» и разделить наш исходный набор данных на два: набор учебных материалов и гораздо меньший набор данных, который будет использоваться для проверки точности нашей модели.
<?php ... use Phpml\CrossValidation\StratifiedRandomSplit; ... $randomSplit = new StratifiedRandomSplit($dataset, 0.1); $trainingSamples = $randomSplit->getTrainSamples(); $trainingLabels = $randomSplit->getTrainLabels(); $testSamples = $randomSplit->getTestSamples(); $testLabels = $randomSplit->getTestLabels();
Этот подход называется перекрестной проверкой. Этот термин исходит из статистики и может быть определен следующим образом:
Перекрёстная прове́рка (кросс-проверка, скользящий контроль, англ. cross-validation) — метод оценки аналитической модели и её поведения на независимых данных. При оценке модели имеющиеся в наличии данные разбиваются на k частей. Затем на k−1 частях данных производится обучение модели, а оставшаяся часть данных используется для тестирования. Процедура повторяется k раз; в итоге каждая из k частей данных используется для тестирования. В результате получается оценка эффективности выбранной модели с наиболее равномерным использованием имеющихся данных.
— Wikipedia.com
Шаг 4: Обучение классификатора
Наконец, мы готовы вернуться и реализовать наш класс SentimentAnalysis. Если вы еще не заметили, огромная часть машинного обучения связана со сбором и обработкой данных; фактическая реализация моделей машинного обучения имеет тенденцию быть гораздо менее вовлеченной.
У нас есть три алгоритма классификации, чтобы реализовать класс анализа настроений:
- Метод опорных векторов
- Метод k-ближайших соседей (KNearestNeighbors)
- Наивный байесовский классификатор (NaiveBayes)
Для этого упражнения мы будем использовать самый простой из всех, классификатор NaiveBayes, поэтому давайте продолжим и изменим наш класс, чтобы реализовать обучающую функцию:
<?php namespace PhpmlExercise\Classification; use Phpml\Classification\NaiveBayes; class SentimentAnalysis { protected $classifier; public function __construct() { $this->classifier = new NaiveBayes(); } public function train($samples, $labels) { $this->classifier->train($samples, $labels); } }
Как вы можете видеть, мы позволяем PHP-ML делать всю тяжелую работу за нас. Мы просто создаем небольшую абстракцию для нашего проекта. Но как мы узнаем, действительно ли наш классификатор тренируется и работает? Время использовать наши testSamples и testLabels.
Шаг 5: Проверка точности классификатора
Прежде чем мы сможем продолжить тестирование нашего классификатора, нам необходимо реализовать метод прогнозирования:
<?php ... class SentimentAnalysis { ... public function predict($samples) { return $this->classifier->predict($samples); } }
И еще раз, PHP-ML выручает нас. Давайте изменим класс classifyTweets следующим образом:
<?php ... $predictedLabels = $classifier->predict($testSamples);
Наконец, нам нужен способ проверить точность нашей обучаемой модели; к счастью, PHP-ML это тоже охватывает, и у них есть несколько метрических классов. В нашем случае нас интересует точность модели. Давайте посмотрим на код:
<?php ... use Phpml\Metric\Accuracy; ... echo 'Accuracy: '.Accuracy::score($testLabels, $predictedLabels);
Мы должны увидеть что-то вроде:
Accuracy: 0.73651877133106%
Заключение
Эта статья получилось слишком большой, так что давайте повторим то, что мы узнали:
- Наличие хорошего набора данных с самого начала имеет решающее значение для реализации алгоритмов машинного обучения.
- Разницу между обучением с учителем и без.
- Значение и использование перекрестной проверки в машинном обучении.
- Что векторизация и трансформация необходимы для подготовки наборов текстовых данных для машинного обучения.
- Как реализовать анализ тональности настроений твитов, используя классификатор NaiveBayes PHP-ML.
Этот пост также послужил введением в библиотеку PHP-ML и, надеюсь, дал вам представление о том, что может сделать библиотека, и о том, как она может быть встроена в ваши собственные проекты.
Наконец, этот пост ни в коем случае не является всеобъемлющим, и есть много возможностей учиться, совершенствовать и экспериментировать; вот некоторые идеи, чтобы вы начали рассуждать о том, как развивать направление:
- Замените алгоритм NaiveBayes методом опорных векторов.
- Если вы попытаетесь запустить полный набор данных (14 000 строк), вы, вероятно, заметите, насколько увеличится нагрузка на память. Попытайтесь реализовать постоянство модели, чтобы ее не нужно было обучать в каждом прогоне.
- Переместите генерацию набора данных в собственный класс-помощник.
THE END