

Регулярные выражения
Если вы когда-либо работали с командной строкой, вы, вероятнее всего, использовали маски имён файлов. Допустим, если хотели полностью удалить файлы в текущей директории, начинающиеся на букву «d», писали команду
В принципе, регулярные выражения — это схожий инструмент, однако более мощный. Он позволяет искать строки, проверять их на соответствие определённому шаблону и т. п. Англоязычное название — Regular Expressions либо просто RegExp. Можно сказать, что регулярные выражения — это язык, описывающий шаблоны строк.
Реализация данного инструмента на разных языках программирования различается, правда, не очень сильно. В этой статье мы поговорим о регулярных выражениях в контексте их реализации на Perl.

Основы синтаксиса
Для начала отметим, что любая строка уже сама по себе — это регулярное выражение. Например, выражению
Регулярные выражения имеют спецсимволы, их нужно экранировать. Список выглядит следующим образом:
. ^ $ * + ? { } [ ] \ | ( )
Для экранирования используют
Набор символов
Допустим, надо найти в тексте все междометия, которые обозначают смех. Мы не можем написать просто
К примеру, паттерну
Большинство спецсимволов внутри набора не нуждается в экранировании, но применение перед ними «\» не будет ошибкой. Нужно экранировать символы «^» и «\», рекомендуется экранировать «]» и «-». Последний применяется для задания диапазонов, но об этом ниже.
Если мы после «[» запишем символ «^», набор получит обратный смысл, а подходящим станет считаться любой символ, кроме тех, что указаны. К примеру, паттерну
Если вернуться к нашему случаю, то после написания
Предопределённые классы символов
Для ряда часто используемых наборов есть специальные шаблоны. Так, для пробела, табуляции и переноса строки применяют
Если вы указанные выше классы напишете с прописной буквы (\S, \D, \W), они поменяют смысл на противоположный.
Кроме всего прочего, с помощью регулярных выражений можно проверить, где находится строка по сравнению с остальным текстом. Допустим, выражение
Таким образом, паттерн
Диапазоны
Иногда возникает необходимость обозначить определённый набор, включающий в себя буквы, к примеру, от «б» до «ф». Чтобы не писать
Механизм особенно полезен для русского языка в силу отсутствия конструкции, аналогичной
Квантификаторы в регулярных выражениях (указатели количества повторений)
Что делать, когда в нашем «смеющемся» междометии окажется между буквами «х» более, чем одна гласная («Хаахааа»)? Подготовленное нами ранее регулярное выражение уже помочь не сможет. А значит, не обойтись без использования квантификаторов.
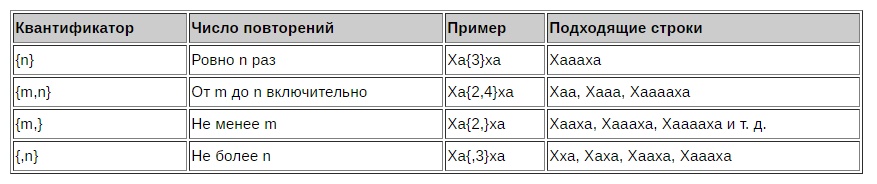
Здесь следует отметить, что квантификатор применяется только к тому символу, который расположен перед ним. Часто используемые конструкции имеют в языке регулярных выражений особые обозначения:

Итак, благодаря квантификаторам, можно улучшить шаблон для тех же междометий, написав
«Ленивая» квантификация и регулярные выражения
Представим, что у нас есть задача по поиску всех HTML-тегов в строке:
<p><b>Otus</b> — моя <i>любимая</i> школа онлайн-образования!</p>
Очевидно, что простое решение
p><b>Otus</b> — моя <i>любимая</i> школа онлайн-образования!</p
Так происходит потому, что по умолчанию квантификатор в регулярных выражениях функционирует по, если можно так выразиться, «жадному алгоритму», то есть пытается вернуть самую длинную строку, которая отвечает условию.
Проблема решается двумя способами:
1. Используется выражение
«Ревнивая» квантификация и регулярные выражения
Порой, для повышения скорости поиска (например, если строка не соответствует регулярному выражению) алгоритму запрещают возвращаться к предыдущим шагам поиска в целях нахождения возможных соответствий для оставшейся части регулярного выражения. Это «ревнивая» квантификация. Квантификатор становится таковым при добавлении к нему справа символа
Скобочные группы
Для шаблона «смеющегося» междометия осталось всего ничего — учесть то обстоятельство, что буква «х» способна встречаться больше, чем один раз, допустим, «Хахахахааахахооо», да и вообще, слово может не заканчиваться на «х». Можно задействовать квантификатор для группы
Итак, регулярное выражение преобразуется в
Обратная связь — запоминание результата поиска по группе
Результат поиска по скобочной группе сохраняется в отдельной ячейке памяти, а доступ к ней разрешён для применения в последующих частях регулярного выражения. Если вернуться к задаче поиска HTML-тегов на странице, давайте представим, что нужно не только найти теги, но и определить их названия. В данном случае поможет регулярное выражение
<p><b>Otus</b> — моя <i>любимая</i> школа онлайн-образования!</p>
Вот результат поиска по всему регулярному выражению:
«<p>», «<b>», «</b>», «<i>», «</i>», «</p>».
А вот итог поиска по 1-й группе:
«p», «b», «/b», «i», «/i», «/i», «/p».
Вы можете ссылаться на результат поиска по группе с помощью регулярного выражения
Когда выражение берётся в скобки лишь для использования в её отношении квантификатора, то сразу после первой скобки следует добавить
С применением данного механизма мы легко перепишем всё регулярное выражение, приведя его к следующему виду:
[Хх]([аоие])х?(?:\1х?)*
Перечисление
Желаете проверить, соответствует ли строка хотя бы одному из шаблонов? Воспользуйтесь аналогом булевого оператора OR, записываемого посредством символа
Удобно применять перечисления внутри скобочных групп. Так, регулярное выражение
Используя данный оператор, мы легко добавим к регулярному выражению для поиска междометий способность распознавать смех типа «Ахахаах» — это единственная усмешка, начинающаяся с гласной:
[Хх]([аоие])х?(?:\1х?)*|[Аа]х?(?:ах?)+
Полезные сервисы по регулярным выражениям
Проверить своё регулярное выражение и потренироваться можно на специальных сервисах: RegExr, Regex101, Regexpal.
Если хотите понять, как работает регулярное выражение, попавшее к вам в руки, используйте Regexper — это сервис, который способен строить понятные диаграммы на основе регулярных выражений.
Также существует визуальный конструктор функций JS, предназначенный для работы с регулярными выражениями — это RegExp Builder.
Помните: не всегда следует решать задачу с помощью регулярных выражений (вспоминаем известный анекдот про программиста и проблему, которая превратилась в две проблемы). В некоторых случаях, к примеру, лучше написать развёрнутый автомат конечных состояний.