

Standard PHP Library: взгляд изнутри

Сегодня речь пойдёт о встроенной в PHP библиотеке SPL. В сети интернет достаточно много справочной информации по разным частям библиотеки. Я решил свести всё воедино. Получилась, этакая, лекция-дайджест.
1. Что такое SPL?
Стандартная библиотека PHP (SPL) — это набор интерфейсов и классов, предназначенных для решения стандартных задач. Не требуется никаких внешних библиотек для сборки этого расширения, и оно доступно по умолчанию в PHP 5.0.0 и выше.
SPL предоставляет ряд стандартных структур данных, итераторов для «оббегания» объектов, интерфейсов, стандартных исключений, некоторое количество классов для работы с файлами и предоставляет ряд функций, например
2. Структуры данных в SPL
2.1. Двусвязный список ( DLL )
Вообще, связный список — это базовая динамическая структура данных, состоящая из узлов, каждый из которых содержит как данные, так и ссылки на следующий и/или предыдущий узел списка.
Зачем они нужны? Их преимущество перед массивом — это структурная гибкость: порядок элементов может не совпадать с порядком расположения данных в памяти, а обход всегда явно задаётся внутренними связями. Списки бывают трёх типов: одно-, дву- и XOR-связные.
Линейный однонаправленный список — это структура данных, состоящая из элементов одного типа, связанных между собой последовательно посредством указателей. Каждый элемент списка имеет указатель на следующий элемент. Последний элемент списка указывает на NULL. Элемент, на который нет указателя, является первым (головным) элементом списка. Здесь ссылка в каждом узле указывает на следующий узел в списке. В односвязном списке можно передвигаться только в сторону конца списка. Узнать адрес предыдущего элемента, опираясь на содержимое текущего узла, невозможно.
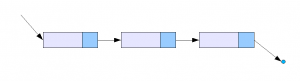
Двусвязный список — это список, ссылки в каждом узле которого указывают на предыдущий и на последующий узел. По двусвязному списку можно эффективно передвигаться в любом направлении — как к началу, так и к концу. В этом списке проще производить удаление и перестановку элементов, так как легко доступны адреса тех элементов списка, указатели которых направлены на изменяемый элемент.
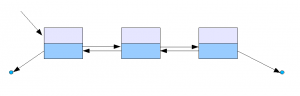
XOR-связный список — структура данных, похожая на обычный двусвязный список, однако в каждом элементе хранящая только один адрес — результат выполнения операции XOR над адресами предыдущего и следующего элементов списка. Чтобы перемещаться по списку, необходимо взять два последовательных адреса и выполнить над ними операцию XOR, которая и даст реальный адрес следующего элемента.
Мы же рассмотрим встроенную в SPL структуру данных — двусвязный список. В SPL он является основой для двух крайне важных и интересных структур. Это стэк и очередь.
Сам класс обеспечивает основные возможности двусвязного списка. Не секрет, что есть два принципа работы с элементами списка — FIFO и LIFO. В DLL можно работать по любому из этих принципов. Это и позволяет реализовывать стэк и очередь.
Все операции итератора, удаления, добавления и т. п. имеют алгоритмическую сложность O(1), что является очень дешёвой операцией.
Вот операции, которые предоставляет SPL класс DLL: — add ( mixed $index , mixed $newval ) – добавление нового значение по указанному индексу; — bottom ( void ) — получает узел, находящийся в начале двусвязного списка; — count ( void ) — подсчитывает количество элементов в двусвязном списке; — current ( void ) — возвращает текущий элемент массива; — getIteratorMode ( void ) — возвращает режим итерации (LIFO, FIFO, DELETE, KEEP); — isEmpty ( void ) — проверяет, является ли двусвязный список пустым; — key ( void ) — возвращает индекс текущего узла; — next ( void ) — перемещает итератор к следующему элементу; — offsetExists ( mixed $index ) — проверяет, существует ли запрашиваемый индекс; — offsetGet ( mixed $index ) — возвращает значение по указанному индексу; — offsetSet ( mixed $index , mixed $newval ) — Устанавливает значение по заданному индексу $index в $newval; — offsetUnset ( mixed $index ) — удаляет значение по указанному индексу $index; — pop ( void ) — удаляет (выталкивает) узел, находящийся в конце двусвязного списка; — prev ( void ) — перемещает итератор к предыдущему элементу; — push ( mixed $value ) — помещает элемент в конец двусвязного списка; — rewind ( void ) — возвращает итератор в начало; — serialize ( void ) — сериализует хранилище; — setIteratorMode ( int $mode ) — устанавливает режим итерации.
Направление итерации (одно из двух): — SplDoublyLinkedList::IT_MODE_LIFO (стэк); — SplDoublyLinkedList::IT_MODE_FIFO (очередь).
Поведение итератора (одно из двух): — SplDoublyLinkedList::IT_MODE_DELETE (элементы удаляются итератором); — SplDoublyLinkedList::IT_MODE_KEEP (итератор обходит элементы, не удаляя их); — shift ( void ) — удаляет узел, находящийся в начале двусвязного списка; — top ( void ) — получает узел, находящийся в конце двусвязного списка; — unserialize ( string $serialized ) — десериализует хранилище; — unshift ( mixed $value ) — вставляет элемент в начало двусвязного списка; — valid ( void ) — проверяет, содержит ли узлы двусвязный список.
2.1.1. SplStack
SplStack — это наследник DLL, реализующий структуру стэка. Стэк — это абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO.
Вот пример реализации простого стэка:
push('1'); $stack->push('2'); $stack->push('3'); echo $stack->count(); // 3 echo "\n"; echo $stack->top(); // 3 echo "\n"; echo $stack->bottom(); // 1 echo "\n"; echo $stack->serialize(); // i:6;:s:1:"1";:s:1:"2";:s:1:"3"; echo "\n"; // извлекаем элементы из стека echo $stack->pop(); // 3 echo "\n"; echo $stack->pop(); // 2 echo "\n"; echo $stack->pop(); // 1 echo "\n";
Наследует основные операции от DLL.
2.1.2. SplQueue
SplQueue – структура для создания очереди. Очередь — абстрактный тип данных с дисциплиной доступа к элементам FIFO. Добавление элемента (принято обозначать словом enqueue — поставить в очередь) возможно лишь в конец очереди, выборка — только из начала очереди (что принято называть словом dequeue — убрать из очереди), при этом выбранный элемент из очереди удаляется.
По сути – то же самое, что стэк, только FIFO:
setIteratorMode(SplQueue::IT_MODE_DELETE); $queue->enqueue('one'); $queue->enqueue('two'); $queue->enqueue('qwerty'); $queue->dequeue(); $queue->dequeue(); echo $queue->top(); // qwerty
2.2. SplHeap
SplHeap — древовидная структура: каждый узел больше или равен своим потомкам, при этом для сравнения используется внедренный метод сравнения, который является общим для всей кучи. SplHeap реализует основную функциональность кучи и является абстрактным классом.
 От SplHeap наследуются два класса:
От SplHeap наследуются два класса:
insert('111'); $heap->insert('666'); $heap->insert('777'); echo $heap->extract(); // 777 echo "\n"; echo $heap->extract(); // 666 echo "\n"; echo $heap->extract(); // 111 echo "\n"; echo "SplMinHeap \n"; $heap = new SplMinHeap(); $heap->insert('111'); $heap->insert('666'); $heap->insert('777'); echo $heap->extract(); // 111 echo "\n"; echo $heap->extract(); // 666 echo "\n"; echo $heap->extract(); // 777 echo "\n";
2.3. SplPriorityQueue
Обеспечивает основные функциональные возможности приоритетной очереди, реализованный при помощи кучи (max-heap). Сортировка производится в зависимости от приоритета. Далее следует обычный алгоритм вытаскивания элементов из структуры.
setExtractFlags(SplPriorityQueue::EXTR_DATA); // получаем только значения элементов $queue->insert('Q', 1); $queue->insert('W', 2); $queue->insert('E', 3); $queue->insert('R', 4); $queue->insert('T', 5); $queue->insert('Y', 6); $queue->top(); while($queue->valid()) { echo $queue->current(); $queue->next(); } //YTREWQ
2.4. SplFixedArray
Представляет собой массив с фиксированным количеством элементов. SplFixedArray хранит данные в непрерывном виде, доступные через индексы, а обычные массивы реализованы в виде упорядоченных хэш-таблиц. Данный вид массива работает быстрее, чем обычные массивы, но существуют некоторые ограничения: 1) в качестве ключей могут быть только целые числа > 0; 2) длина может быть изменена, но это затратная операция.
Тут стоит уделить внимание тому, как же реализованы массивы в PHP – именно те, с которыми мы обычно работаем. На уровне PHP, массив — это упорядоченный список, скрещенный с мэпом. Грубо говоря, PHP смешивает эти два понятия, в итоге получается, с одной стороны, очень гибкая структура данных, с другой стороны, возможно, не самая оптимальная.
На уровне C (да и вообще на системном уровне) не бывает массивов с нефиксированным размером. Каждый раз, когда вы создаете массив в C, вы должны указать его размер, чтобы система знала, сколько нужно памяти на него выделить.
Тогда как это реализовано в PHP?
Когда вы создаёте пустой массив, PHP создаёт его с определённым размером. Если вы заполняете массив и в какой-то момент достигаете и превышаете этот размер, то создаётся новый массив с вдвое большим размером, все элементы копируются в него и старый массив уничтожается.
На самом деле для реализации массивов в PHP используется вполне себе стандартная структура данных Hash Table. Этот самый Hash Table хранит в себе указатель на самое первое и последнее значения, указатель на текущее значение, кол-во элементов, представленных в массиве, массив указателей на Bucket-ы (о них далее), и ещё кое-что. Есть две главные сущности, первая — это собственно сам Hash Table, и вторая — это Bucket (далее ведро).
В вёдрах хранятся сами значения, то есть на каждое значение — своё ведро. Но помимо этого в ведре хранится оригинал ключа, указатели на следующее и предыдущее вёдра (они нужны для упорядочивания массива, ведь в PHP ключи могут идти в любом порядке, в каком вы захотите), и, опять же, ещё кое-что.
Таким образом, когда вы добавляете новый элемент в массив, если такого ключа там ещё нет, то под него создаётся новое ведро и добавляется в Hash Table. У Hash Table есть некий массив указателей на вёдра, при этом вёдра доступны в этом массиве по некоему индексу, а этот индекс можно вычислить, зная ключ ведра.
То, что происходит после переполнения массива, называется rehash. И именно тут происходит операция копирования массива, о которой я сказал ранее. И именно по этой причине в PHP нельзя применять стандартные оценки сложности сортировок и других алгоритмов при работе со стандартными массивами.
Теперь вернёмся к нашему SplFixedArray. Учитывая описание данной структуры, можно смело сказать, что это реализация массива в классическом его понимании. Данная структура хорошо подходит для нумерованных списков.
3. Итераторы
Раз уж мы говорим о структурах данных, то стоит упомянуть и такие механизмы, как итераторы.
Итератор – это интерфейс, предоставляющий доступ к элементам коллекции (массива или контейнера) и навигацию по ним.
Обработка объектов итераторов очень похожа на обработку массивов. Многие начинающие программисты начинают с использования итераторов для массивов. Но реальные преимущества итераторы дают при переборе большого количества гораздо более сложных данных, чем простой массив.
Цикл
При создании структур данных итераторы могут существенно повлиять на производительность, так как позволяют организовать отложенную загрузку данных. Отложенная загрузка даёт возможность получать данные только тогда, когда они нужны. Также можно манипулировать данными (фильтровать, преобразовывать и так далее) перед передачей их пользователю.
Решение об использовании итераторов всегда остаётся за разработчиком. Итераторы имеют ряд преимуществ, но в некоторых случаях их применение может оказаться избыточным (например, для небольших наборов данных). Поэтому нужно принимать во внимание все факторы проекта.
В SPL существует несколько типов итераторов. Я рассмотрю, на мой взгляд, самые популярные.
3.1. ArrayIterator
Позволяет сбрасывать и модифицировать значения и ключи в процессе итерации по массивам и объектам. Конструктор принимает массив в качестве параметра и предоставляет набор методов для его обработки.
$value) { echo $key . ": " . $value . " "; }
Обычно используется
Обратите внимание, что, хотя ArrayObject и ArrayIterator ведут себя как массивы в данном контексте, они являются объектами. Попытка использовать встроенные функции для массивов, например,
Использование ArrayIterator ограничивается одномерными массивами. Тогда, когда можно обрабатывать многомерные массивы, нужно использовать RecursiveArrayIterator.
$value) { echo $key . ": " . $value . " "; }
3.2. DirectoryIterator
Итератор для работы с директориями:
"; }
С помощью набора различных методов, таких как
getExtension(), $this->ext); } } //Создаём новый итератор $dir = new FileExtensionFilter(new DirectoryIterator("./")); // Создан итератор в итераторе
В SPL также имеется RecursiveDirectoryIterator, который можно использовать также, как и RecursiveArrayIterator. Есть одна особенность. RecursiveDirectoryIterator не возвращает пустых директорий: если директория содержит много поддиректорий, но без файлов, результат будет пустым.
4. SPL функции
Помимо прочего, SPL предоставляет набор очень удобных функций, которые позволяют строить мощную архитектуру каркасов приложений:
— class_implements — возвращает список интерфейсов, реализованных в заданном классе или интерфейсе;
— class_parents — возвращает список родительских классов заданного класса;
— class_uses — возвращает список трэйтов, используемых заданным классом;
— iterator_apply — вызывает функцию для каждого элемента в итераторе;
— iterator_count — подсчитывает количество элементов в итераторе;
— iterator_to_array — копирует итератор в массив;
— spl_autoload_call — попытка загрузить описание класса всеми зарегистрированными методами
Ну что ж, лекция окончена. Буду рад ответить на возникшие вопросы, пишите их в комментариях.