

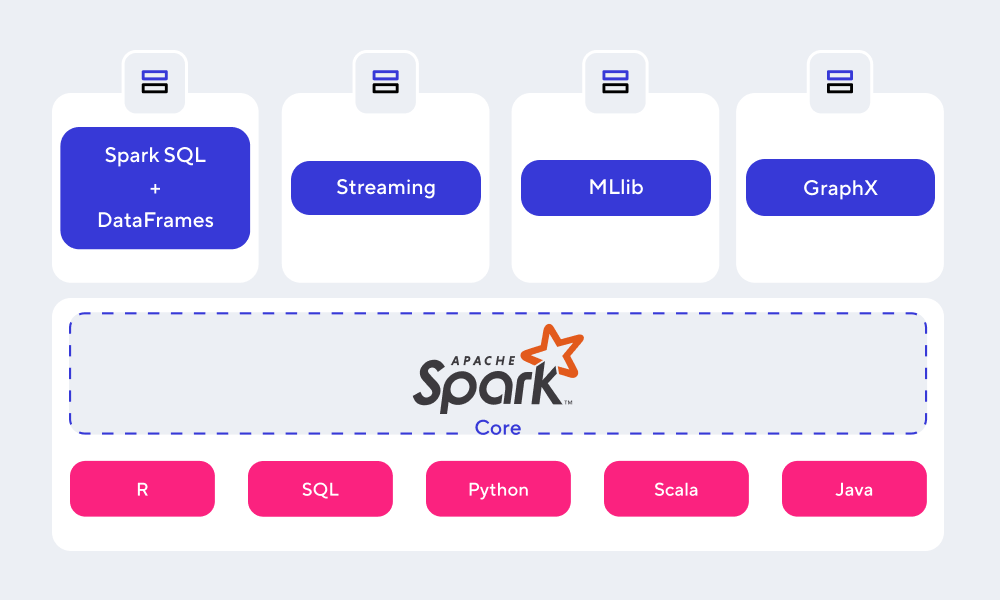
Основные компоненты Apache Spark
Apache Spark — платформа, используемая в Big Data для крупномасштабной обработки данных и кластерных вычислений. Spark осуществляет обработку данных непосредственно в оперативной памяти, то есть он редко обращается к диску, следовательно, работает весьма быстро.
Apache Spark является полностью совместимым с экосистемой Hadoop и может легко встраиваться в существующие решения. У него отсутствует свое хранилище данных, и он способен работать с разными источниками: Hive, HDFS, S3, HBase, Cassandra и пр. Также он поддерживает несколько языков программирования. Среди них -- Java, Scala, Python, R, SQL.
На практике Spark применяется в целях обработки данных, к примеру, для фильтрации, очистки, сортировки, валидации и т. д. Вот как можно отобразить его место в процессе работы с Big Data:
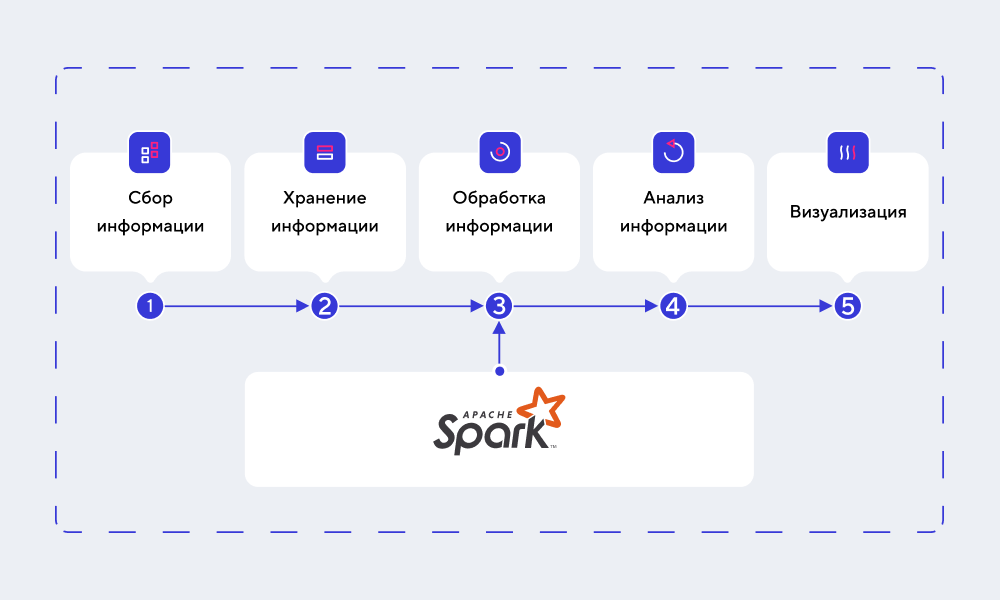
Ниже рассмотрим основные функциональные компоненты Spark.
Apache Spark Core
Представляет собой базовый движок для обработки данных, находящийся, по сути, в основе всей описываемой платформы. При этом ядро осуществляет взаимодействие с системами хранения, а также управляет памятью, планирует/распределяет нагрузку в кластере. Кроме того, Core отвечает за поддержку API языков программирования.
Spark SQL
Специальный модуль, который упрощает работу со структурированными данными, а также позволяет выполнять SQL-запросы. Его основная задача -- сделать так, чтобы дата-инженеры особо не задумывались о распределенной природе хранения данных, а могли полноценно сосредоточиться на сценариях использования этих данных.
Streaming
Предназначен для обеспечения масштабируемой, высокопроизводительной и отказоустойчивой потоковой обработки данных в режиме реального времени. Для Spark в качестве источников данных могут выступать такие системы, как Kafka, Flume, Kinesis и прочие.
MLlib
Представляет собой масштабируемую Machine Learning-библиотеку низкого уровня. В ней реализованы разнообразные ML-алгоритмы, к примеру, регрессия, кластеризация, классификация, коллаборативная фильтрация.
GraphX
Нужен для манипуляций над графами и для их параллельной обработки. Компонент GraphX способен измерять связность графов, среднюю длину пути, распределение степеней и прочие показатели. Вдобавок к вышесказанному, он способен соединять графы и довольно быстро преобразовывать их. Также присутствует библиотека с реализацией алгоритма PageRank.
По материалам https://mcs.mail.ru/blog/.