

Опции с томами в "Spark on Kubernetes"
Уже начиная со Spark версии 2.4, в случае применения Spark on Kubernetes появилась возможность монтировать 3 типа томов. Рассмотрим их подробнее:
- emptyDir. Эта директория изначально пуста и существует до тех пор, пока работает под. По сути, она полезна именно для временного хранения. Поддерживать ее можно посредством SSD, диска ноды либо сетевого хранилища;
- hostpath. В данном случае в ваш под монтируется директория непосредственно из текущей ноды;
- статически и заблаговременно создаваемый PersistentVolumeClaim. Не что иное, как Kubernetes-абстракция, предназначенная для различных типов персистентного хранилища. Как уже было упомянуто выше, пользователь должен создавать PersistentVolumeClaim заранее. Остается добавить, что существование тома к поду не привязано.

Начиная со Spark версии 3.1, у пользователей появились 2 новых варианта:
- NFS;
- динамически создаваемый PersistentVolumeClaims.
Давайте рассмотрим их более детально.
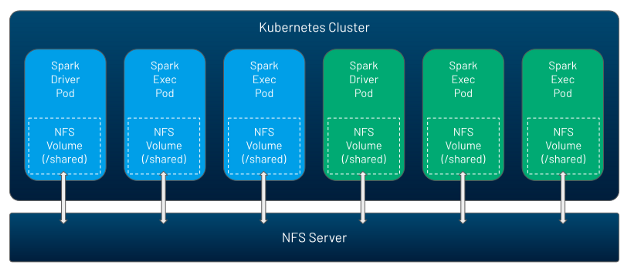
NFS (Network File System)
NFS представляет собой том, который могут несколько подов использовать в одно и то же время, причем этот том можно наполнить данными заранее. По сути, речь идет о способе обмена информацией, конфигурациями и кодом между Spark-приложениями или же между драйвером и исполнителем непосредственно внутри какого-либо Spark-приложения. Так как в Kubernetes отсутствует NFS-сервер, вы можете запускать его самостоятельно либо задействуя облачный сервис.
После того, как NFS создан, этот том можно без труда монтировать в Spark-приложение посредством следующих настроек:

Таким образом, NFS представляет собой популярный способ обмена данными, производимый между любыми Spark-приложениями. Ну и тот факт, что теперь он может работать поверх Kubernetes, разумеется, не может не радовать.
PVC
Второй момент — динамический PVC. Считается, что PVC представляет собой более удобный способ применения персистентных томов. Раньше надо было сначала создавать PVC, ну а потом их монтировать. Это имело свои минусы, ведь в случае применения динамического выделения пользователь не знает, сколько можно создать исполнителей в процессе работы приложения, то есть можно констатировать, что старый способ был несколько неудобен. Кроме того, приходилось самому "чистить" ненужные PersistentVolumeClaims либо мириться с потерей места в хранилище.
Но вот, появился Spark версии 3.1, и все стало динамическим и автоматизированным. Теперь при инициализации Spark-приложения либо в ходе динамического выделения, когда пользователь запрашивает новых исполнителей, в Kubernetes динамически формируется и создается PersistentVolumeClaims, который в автоматическом режиме предоставляет новый PersistentVolumes запрошенного класса хранилища. При этом в случае удаления пода ассоциированные с этим подом ресурсы удаляются тоже автоматически.
По материалам https://towardsdatascience.com/apache-spark-3-1-release-spark-on-kubernetes-is-now-generally-available-65cccbf1436b.