

График Response Time и его вариации
Чаще всего измеряется в миллисекундах — показывает время ответа на запросы к приложению. Время отклика не должно превышать SLA. Этот график является основным инструментом для поиска точек деградации при проведении нагрузочного тестирования.
Если на графике видны пики, значит, в этот момент приложение не отвечало по какой-то причине — это может являться отправной точкой для дальнейших исследований. Время отклика должно быть равномерным, без пиков для всех операций на протяжении всей ступени нагрузки, а также коррелировать с увлечением нагрузки. Gatling не содержит график «чистого» (среднего, неагрегированного) времени отклика, в отличие от других инструментов.
Кроме графика времени ответа каждого запроса, удобно показывать также линию с суммарным временем ответа (Total Response Time). Если наложить график подаваемой нагрузки (VU/RPS), можно отслеживать корреляцию с увеличением времени отклика от увеличения подаваемой нагрузки (VU/RPS). В Apache JMeter этот график называется Response Times vs Threads.
Далее пойдут графики, на которых может быть множество линий, каждая из которых отображает свой сценарий или запрос. Если у вас сложный тест со множеством операций и нелинейным профилем, советуем отражать в отчете лишь наиболее показательные запросы или группы запросов. Как вариант, можно отражать лишь запросы, превысившие SLA/SLO, чтобы не засорять график и отчет.
Вариации графика
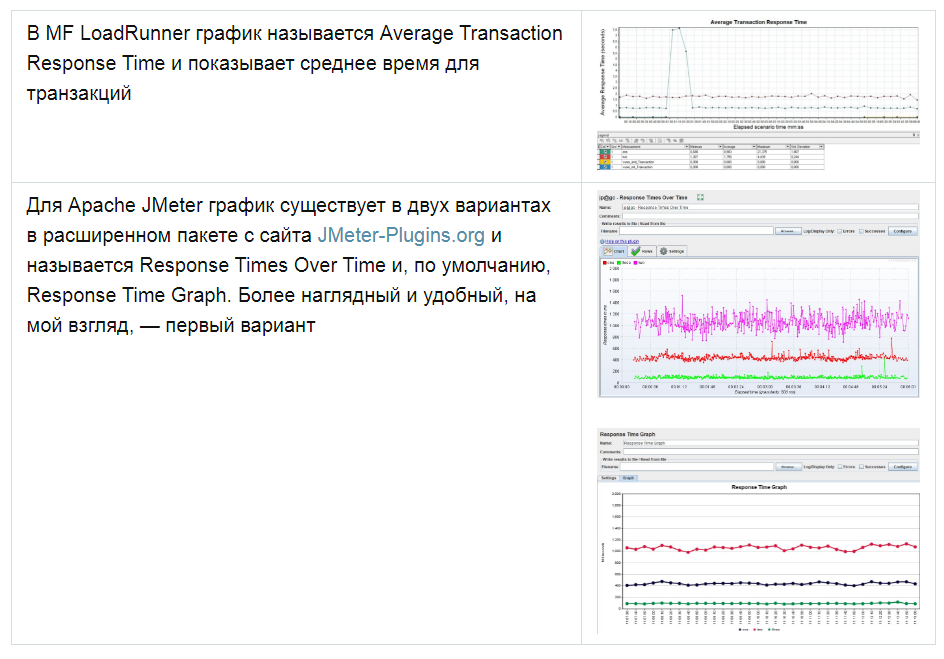
Возможна модификация, в которой применяются перцентили времени отклика и добавляется линия среднего времени отклика по всем запросам. Использование перцентилей здесь будет более правильным решением, так как среднее время отклика очень чувствительно к резким выбросам.
В тестировании производительности чаще всего используется 95 и 99 перцентиль для большей наглядности. Однако, если вы все же смотрите среднее время отклика, вам стоит учитывать при этом стандартное (среднеквадратичное) отклонение.
Распределение Response Time
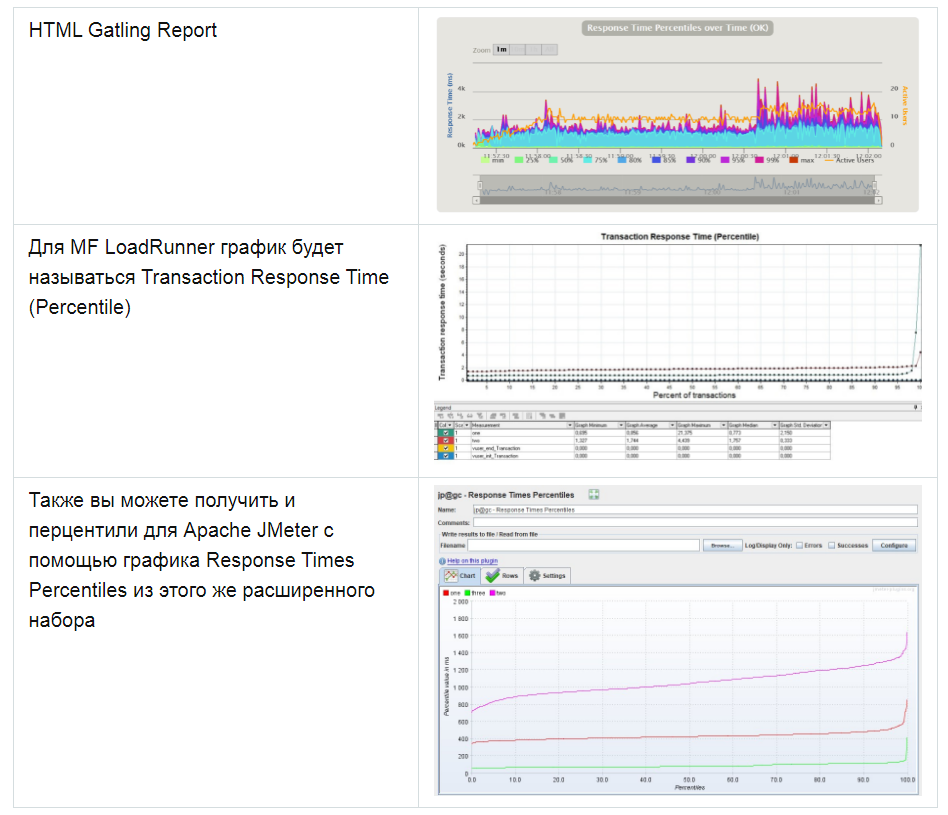
Также есть прекрасные графики, показывающие зависимость распределения времени от количества запросов.
Этот вид графиков чем-то напоминает индикаторы, но показывает более полную картину распределения времени, без обрезки перцентилями или другими агрегатами. С помощью графика можно более наглядно определить границы для групп индикаторов. У MF LoadRunner такого графика нет.
Latency
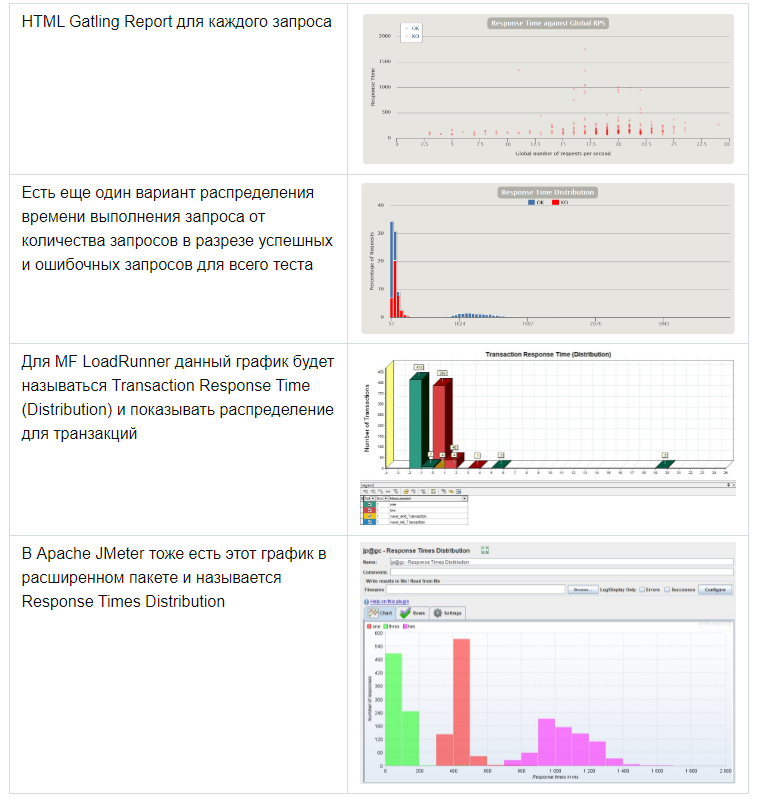
Из этой метрики также можно выделить дополнительный параметр Latency (миллисекунды) — время задержки (чаще всего под этим понимают Network Latency). Этот параметр показывает время между окончанием отправки запроса до получения первого ответного пакета от системы.
С помощью этого параметра можно измерять также задержки на сетевом уровне, если параметр будет расти. Желательно, чтобы он стремился к нулю. Этот тип графиков в основном используются при глубоком анализе и поиске проблем производительности. Этого графика из коробки нет в Gatling. В MF LoadRunner этот график называется Average Latency Graph в блоке Network Virtualization Graphs, если у вас установленные агенты мониторинга.
Bandwidth
Аналогично метрике выше можно выделить параметр Bandwidth (килобит в секунду) — ширину пропускания канала. Он показывает, какой максимальный объем данных может быть передан за единицу времени.
Изменяя этот параметр на инструменте нагрузки, можно моделировать различные источники подключений к приложению: мобильная связь 4G или проводная сеть. В бесплатной версии Gatling этого графика нет, он есть лишь в платной версии Gatling FrontLine. Этот график из коробки есть лишь в MF LoadRunner, находится в том же блоке, что и Latency, и называется Average Bandwidth Utilization Graph.