

Форматы файлов в Big Data: ORC
Optimized Row Columnar (ORC) — это оптимизированный строково-столбчатый файловый формат, предлагающий эффективный способ хранения данных. Целью его разработки было преодоление ограничения других форматов. ORC хранит данные в максимально компактном виде, пропуская ненужные детали. При этом формат не требует построения сложных и больших индексов, обслуживаемых вручную.
Давайте посмотрим, какие существуют преимущества у этого формата: 1. Один файл на выходе любой задачи — это снижает нагрузку на узел имен (NameNode). 2. Поддерживается тип данных Hive, включая DateTime. Также поддерживаются сложные и десятичные типы данных (list, map, struct, union). 3. Возможно одновременное считывание того же файла различными процессами RecordReader. 4. Можно разделить файлы без сканирования этих файлов на предмет наличия маркеров. 5. Оценивается максимально возможное выделение памяти кучи на процессы чтения и записи в футере файла. 6. Сохранение метаданных осуществляется в бинарном формате сериализации Protocol Buffers, а этот формат, как известно, позволяет добавлять/удалять поля.
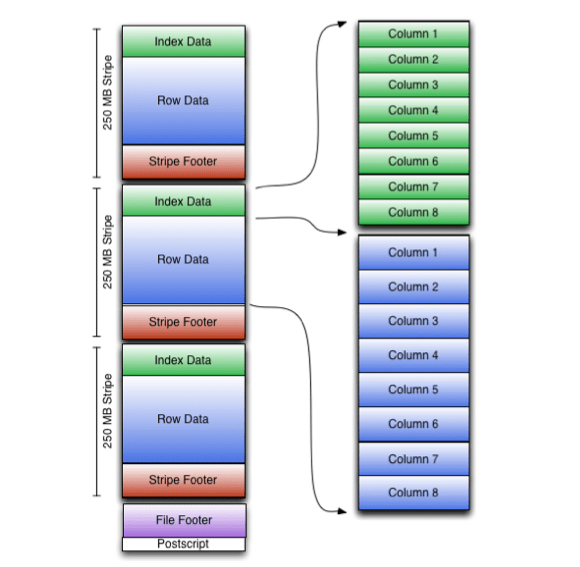
Формат ORC осуществляет хранение коллекции строк в одном файле, причем внутри коллекции хранение строчных данных реализуется в столбчатом формате.
Также ORC-файл хранит группы строк, называемых полосами (stripes), плюс он хранит дополнительную информацию в футере. В конце файла есть postscript, содержащий параметры сжатия, а также размер сжатого футера.
Размер полосы по дефолту — 250 Мб. Благодаря этому, чтение из HDFS производится эффективнее, т. к. осуществляется это чтение большими непрерывными блоками.
Что касается футера файла, то в нем записан список файловых полос, число строк на полосу, а также тип данных по каждому столбцу. Кроме этого, там же отмечено результирующее значение count, max, min и sum, причем по каждому столбцу.
Каталог местоположений потока находится в футере полосы. Строчные данные применяются в процессе сканирования таблиц.
Еще существуют индексные данные, включающие минимальные и максимальные значения как для каждой позиции строк в столбце, так и для каждого столбца. На практике ORC-индексы применяются лишь для выбора полос и групп строк и не применяются для ответов на запросы.
По материалам блога MCS.Mail.ru.