

Sharding в построении отказоустойчивого сервиса
В предыдущих заметках мы рассказывали про горизонтальное масштабирование, CQRS и архитектурный паттерн Event Sourcing. Но, как известно, в системах с Event Sourcing нет строгой согласованности. А это значит, что нам можно задействовать сразу несколько хранилищ, причем без синхронизации между этими хранилищами.
Так как задача заключается в построении быстрого и отказоустойчивого сервиса, то мы можем: • разделить файлы по типам. К примеру, изображения и видео можно декодировать, выбрав наиболее эффективный формат; • разделить аккаунты по странам. Эта схема архитектуры предоставляет такую возможность автоматически, но вообще, необходимость в этом может возникнуть и по законодательным причинам.
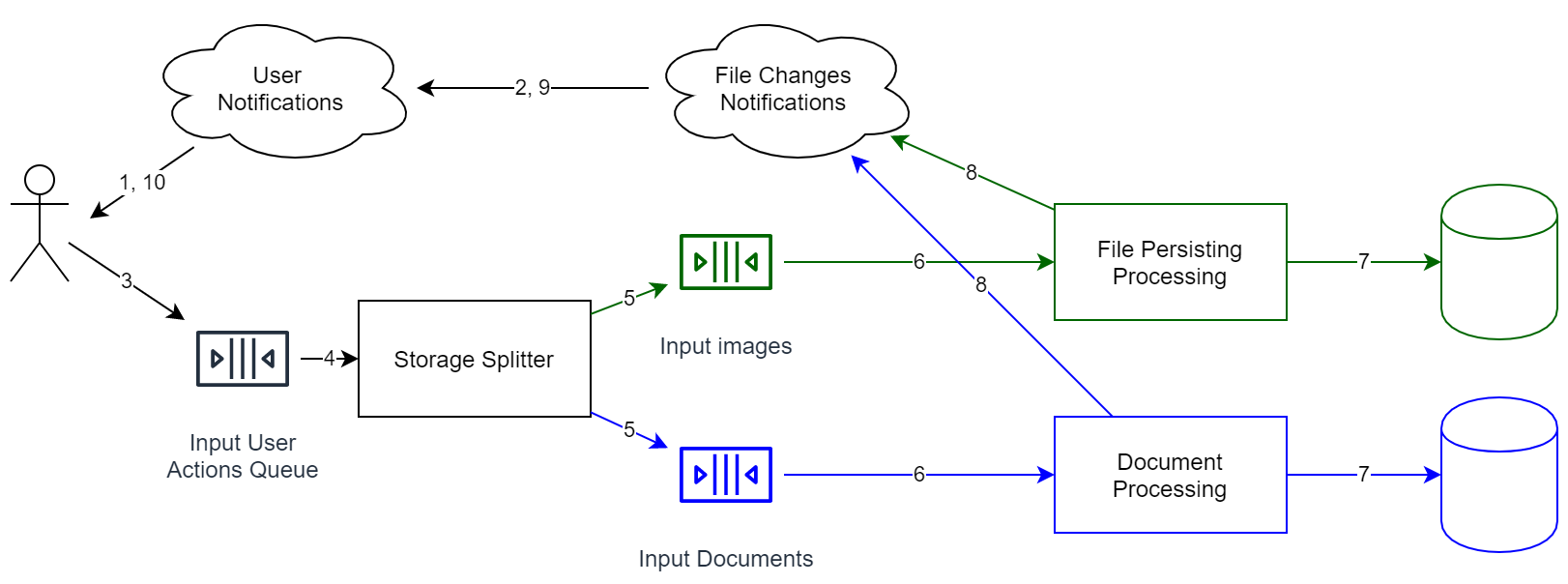
Однако если вы пожелаете осуществить перенос данных из одного хранилища в другое, стандартными средствами здесь не обойтись. К сожалению, в этом случае надо будет остановить очередь, сделать миграцию, а далее запустить ее. В общей ситуации вы не сможете перенести данные, что называется, «на лету», но если очередь событий сохраняется полностью, и у вас существуют слепки предыдущих состояний вашего хранилища, то можно переиграть события следующим образом:
• так как в Event Source каждое событие имеет собственный id (в идеале он не уменьшается), то в хранилище добавляем поле — идентификатор последнего обработанного элемента; • выполняем дублирование очереди, чтобы события смогли обрабатываться для нескольких независимых хранилищ (первое хранилище — это хранилище, где данные хранятся уже сейчас, второе — новое хранилище, пока пустое). При этом 2-я очередь пока обрабатываться не будет; • выполняем запуск 2-й очереди (начинаем переигрывать события); • если новая очередь будет относительно пуста (речь идет о том, чтобы средняя разница во времени между добавлением и извлечением элемента была приемлема), можно приступать к переключению пользователей на новое хранилище.
К чему в итоге пришли? В системе до сих пор нет строгой согласованности. Зато есть eventual constistency и гарантия того, что события будут обрабатываться в одинаковом порядке (правда, возможно, с разной задержкой). А уже пользуясь этим, мы сможем относительно легко перенести данные на другой конец планеты, не останавливая при этом систему.
Какие плюсы дает подобная архитектура, если мы строим онлайн-хранилище для файлов: • есть возможность перемещать объекты поближе к пользователям, причем делая это динамически. А значит, повышается качество сервиса; • есть возможность хранить часть информации внутри компаний. К примеру, Enterprise-пользователи часто требуют хранить свои данные в подконтрольных дата-центрах (для предотвращения утечек). А благодаря sharding мы можем без проблем это обеспечить. Причем задача становится еще более простой, если в распоряжении заказчика есть совместимое облако (допустим, Azure self hosted); • не обязательно сразу писать код. Для начала нас вполне устроит одно хранилище для всех аккаунтов (это позволит быстрее начать работу). Таким образом, мы подходим к ключевой особенности системы — пусть она и расширяема, однако на начальном этапе она относительно проста. Следовательно, нет необходимости сразу же писать код, который будет работать с миллионом независимых отдельных очередей и т. п. То есть если понадобится, мы просто сделаем это в будущем.
По материалам блога компании «Технологический Центр Дойче Банка» (https://habr.com/ru/company/dbtc/).