

Архитектурные паттерны: Event Sourcing

Как известно, быструю распределенную систему синхронизовать нельзя, так как мы уменьшаем производительность. С другой стороны, иногда нам все же необходимо обеспечить определенную согласованность компонентов. Как раз для этого и существует подход eventual consistency, при котором гарантируется, что в случае отсутствия изменений данных через какой-либо промежуток времени после последнего обновления все запросы станут возвращать последнее обновленное значение.
Что тут важно понимать? Дело в том, что для классических БД относительно часто применяется строгая согласованность, когда каждый узел владеет одинаковой информацией (такое нередко достигается тогда, когда транзакция считается установленной лишь после ответа 2-го сервера). Тут существует ряд послаблений из-за уровней изоляции, но общая суть не меняется — можно жить в полностью согласованном мире.
Но вернемся к основной теме статьи. Итак, если мы можем часть системы построить с eventual consistency, мы можем построить следующую схему:
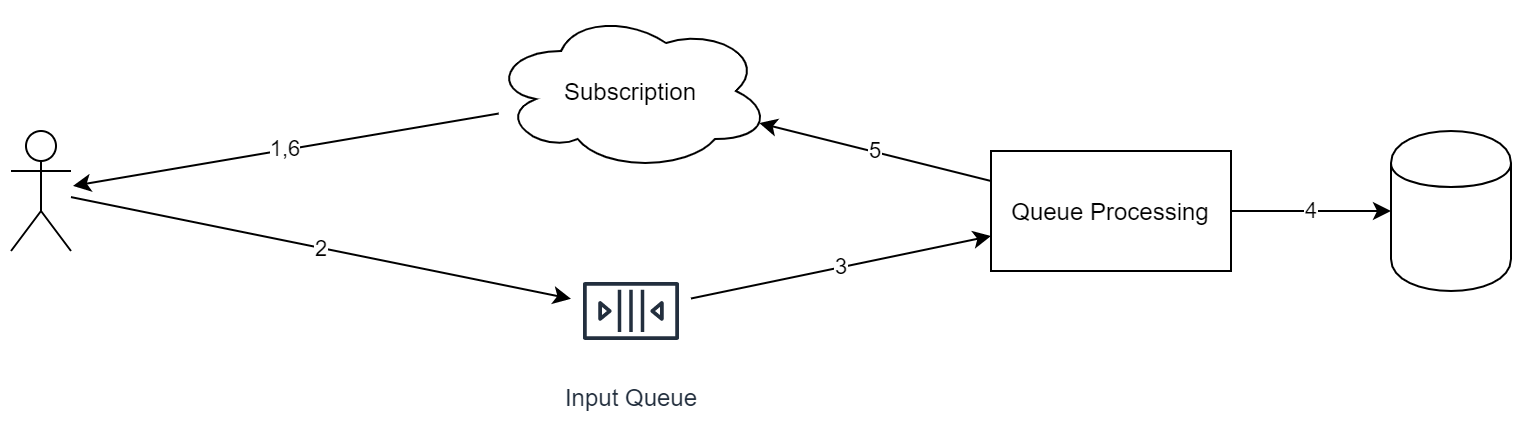
Что важно выделить в этом подходе: 1. Любой входящий запрос помещается в одну очередь. 2. Во время обработки запроса сервис может помещать задачи в другие очереди. 3. У любого входящего события существует идентификатор, необходимый для дедупликации. 4. Очередь идеологически функционирует по схеме «append only». То есть мы не можем удалять из нее элементы либо переставлять их. 5. Очередь функционирует по схеме FIFO. Когда надо сделать параллельное выполнение, необходимо в одном из этапов перекладывать объекты в различные очереди.
Итак, перед нами — файловое онлайн-хранилище. Смотрим схему теперь:
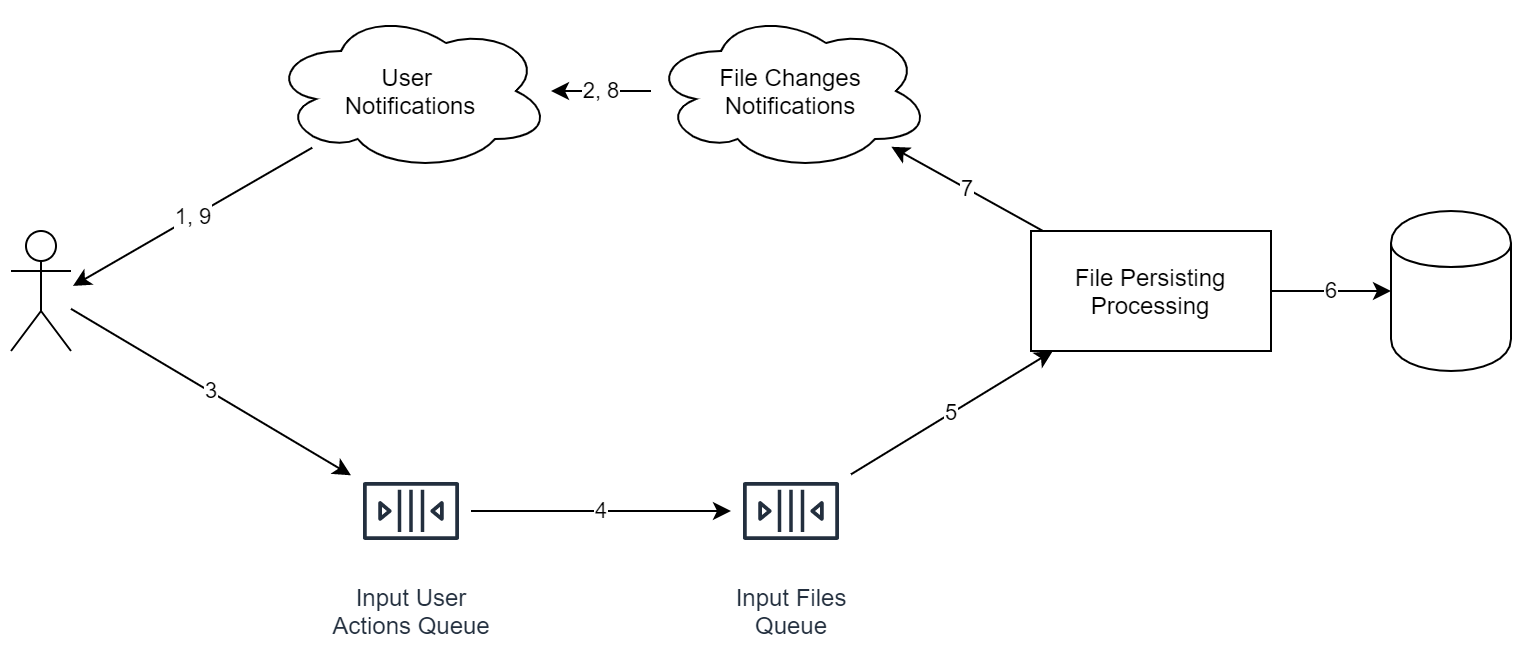
Обратите внимание, что сервисы на диаграмме совсем не обязательно означают отдельный сервер. Мало того, даже процесс может быть один и тот же. Главное не это, а то, что идеологически данные вещи разделены так, чтобы была возможность легко использовать горизонтальное масштабирование.
Теперь давайте посмотрим, как будет выглядеть наша схема для 2-х пользователей:
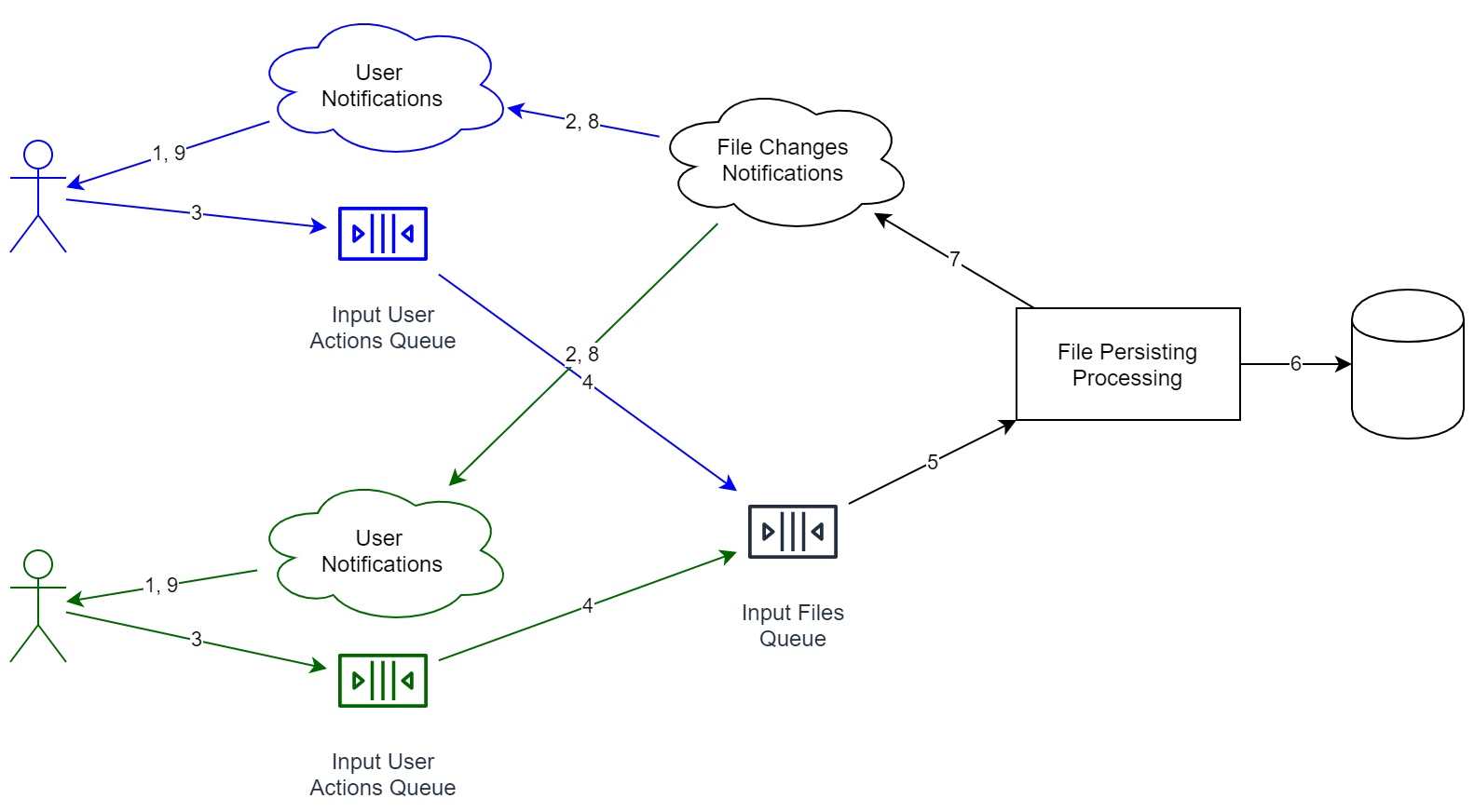
Подобная комбинация имеет ряд плюсов:
- Разделены сервисы обработки информации. Очереди разделены тоже. Когда нам потребуется повысить пропускную способность системы, нам надо будет всего-то запустить больше сервисов, сделав это на большем количестве серверов.
- Если мы получаем информацию от пользователя, совсем не обязательно ожидать полного сохранения данных. Мало того, нам будет вполне достаточно ответить «ок», чтобы потом постепенно начать работу. А еще очередь заодно сглаживает пики, ведь добавление нового объекта осуществляется быстро, а полного прохода по всему циклу пользователь может и не ждать.
- Мы добавили в пример сервис дедупликации — он пытается объединять одинаковые файлы. Когда он работает долго, клиент в 1 % случаев этого не заметит (см. выше), что немаловажный плюс, ведь от нас уже не нужна будет 100%-ная надежность и скорость.
Но есть и недостатки:
- У системы больше нет строгой согласованности. Если, к примеру, подписаться к различным сервисам, теоретически можно получить разное состояние (один из сервисов может и не успеть принять уведомление от внутренней очереди). Второе следствие вышесказанного — у системы теперь отсутствует общее время. Таким образом нельзя, к примеру, отсортировать все события просто лишь по времени прихода, ведь часы между серверами могут не быть синхронными (мало того, одинаковое время на 2-х серверах — это вообще утопия).
- Теперь нельзя просто откатить события, причем никакие (как это можно было сделать с БД). Вместо этого надо добавлять новое событие — compensation event, что будет менять последнее состояние на необходимое состояние. Вспоминаем git: мы не можем откатить коммит, но можем выполнить специальный rollback commit, который просто вернет нам старое состояние, но в истории сохранится и rollback, и ошибочный коммит.
- Схема данных способна меняться от релиза к релизу, но старые события нам уже не получится обновить на новый стандарт, ведь события в принципе менять нельзя.
Таким образом, можно сказать, что Event Sourcing прекрасно уживается с CQRS. Вообще, реализовать систему с удобными и эффективными очередями, правда, без разделения потоков данных, уже сложно само по себе, ведь нам придется добавлять точки синхронизации, а эти точки станут нивелировать весь позитивный эффект от очередей. Используя 2 подхода сразу, надо будет немного скорректировать код работы программы. В нашем примере в процессе отправки файла на сервер в ответе приходит лишь «ок», а это означает только то, что «операция добавления файла сохранена». Но формально это не значит, что данные уже являются доступными на иных устройствах (к примеру, сервис дедупликации способен перестраивать индекс). Но через некоторое время клиент получит уведомление типа «файл Х сохранен».
Вместо послесловия:
- Количество статусов отправки файлов повышается: вместо классического «файл отправлен» мы будем получать «файл добавлен в очередь на сервере», плюс «файл сохранен в хранилище». Причем последнее значит, что другие устройства уже смогут начать получать файл (учитывая поправку на то, что очереди функционируют с различной скоростью).
- Так как информация об отправке стала у нас приходить по различным каналам, надо придумывать решения для получения статуса обработки файла. Как следствие — в отличие от классического request-response, клиент теперь может быть перезапущен во время обработки файла, только вот статус этой обработки будет корректен. При этом данный пункт функционирует, по сути, из коробки. Отсюда вывод: теперь мы более толерантны к отказам.
По материалам блога компании «Технологический Центр Дойче Банка».