

Эффективное сжатие колоночных данных с помощью оптимальных алгоритмов кодирования
Основы
Amazon Redshift — это база данных, предназначенная, в первую очередь, для аналитики и запросов OLAP. Одна из ее ключевых функций — хранение данных в колоночном формате (columnar storage).
Это позволяет хранить бОльшие объемы данных по сравнению со строковыми форматами (row storage), что становится возможным благодаря алгоритмам кодирования и однородной природе данных одного столбца (он очень хорошо сжимается).
По умолчанию, когда вы изначально создаете и заполняете таблицу, Redshift выбирает алгоритмы сжатия для каждого столбца самостоятельно.
Подробнее о кодировках сжатия Redshift можете почитать здесь.
Вопрос о параметрах сжатия по умолчанию
Мне было интересно, можно ли применять более эффективные алгоритмы кодирования, чтобы сжимать данные еще эффективнее.
К счастью, у нас есть команда ANALYZE COMPRESSION:
Выполняет анализ сжатия и создает отчет с предлагаемой кодировкой сжатия для анализируемых таблиц. Для каждого столбца отчет включает оценку потенциального сокращения дискового пространства по сравнению с текущей кодировкой.
ANALYZE COMPRESSION hevo.wheely_prod_orders__backup COMPROWS 1000000 ;
Вот пример вывода:
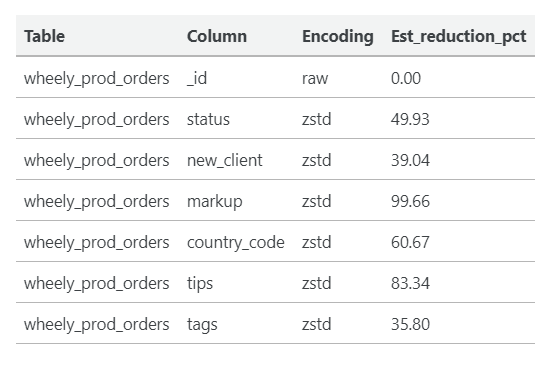
Ваши следующие шаги:
- Создать новую таблицу с предложенными кодировками (возможно, с новыми ключами dist / sort).
- Вставить данные в новую таблицу (сделать глубокую копию).
- Выполнить тесты и бенчмарки.
- Выполнить замену таблицы, удалить старую таблицу.
Оберните это в автоматический макрос
Теперь, когда дело доходит до автоматизации рутинных операций или их выполнения, на ряде таблиц очень удобны такие фреймворки, как dbt.
С помощью макроса dbt можно автоматизировать весь цикл операций и даже поставить его на регулярную основу:
{{ redshift.compress_table('hevo', 'wheely_prod_orders', drop_backup=False, comprows=1000000) }}
Смотрите описание пакета dbt Redshift, а также исходный код макроса сжатия.
Теперь давайте посмотрим на следующий код:
-- ensure new table does not exist yet drop table if exists "hevo"."wheely_prod_orders__compressed"; -- CREATE new table with new encodings create table "hevo"."wheely_prod_orders__compressed" ( -- COLUMNS "_id" VARCHAR(512) encode raw not null , "status" VARCHAR(512) encode zstd , "new_client" VARCHAR(512) encode zstd , "sorted_at" TIMESTAMP WITHOUT TIME ZONE encode az64 , "transfer_other_zone_id" VARCHAR(512) encode lzo , "ts" VARCHAR(512) encode lzo , ... -- CONSTRAINTS , PRIMARY KEY (_id) ) --KEYS -- DIST diststyle key distkey("_id") -- SORT compound sortkey("_id") ; -- perform deep copy insert into "hevo"."wheely_prod_orders__compressed" ( select * from "hevo"."wheely_prod_orders" ); -- perform atomic table interchange begin; -- drop table if exists "hevo"."wheely_prod_orders__backup" cascade; alter table "hevo"."wheely_prod_orders" rename to "wheely_prod_orders__backup"; alter table "hevo"."wheely_prod_orders__compressed" rename to "wheely_prod_orders"; commit;
Оцениваем результаты
Итак, я выполнил процедуру сжатия для нескольких таблиц, и теперь пришло время изучить результаты.
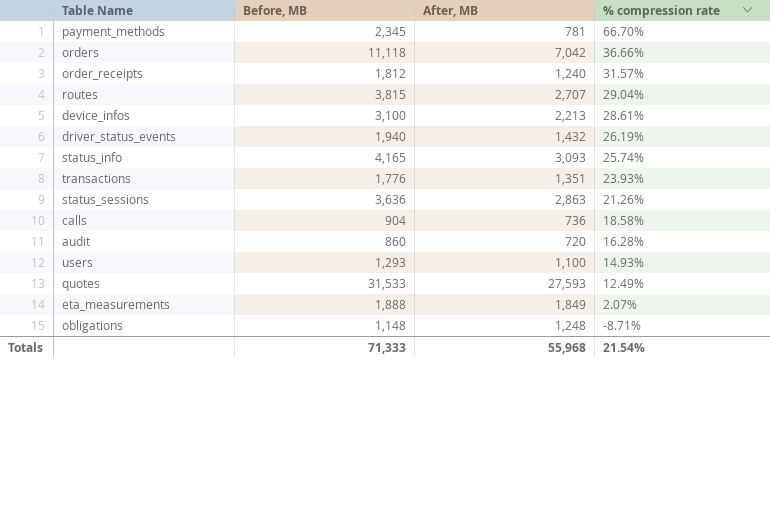
Степень сжатия варьируется от 67 % до -9 %, что говорит о том, что автоматическое сжатие подходит не для всех случаев.
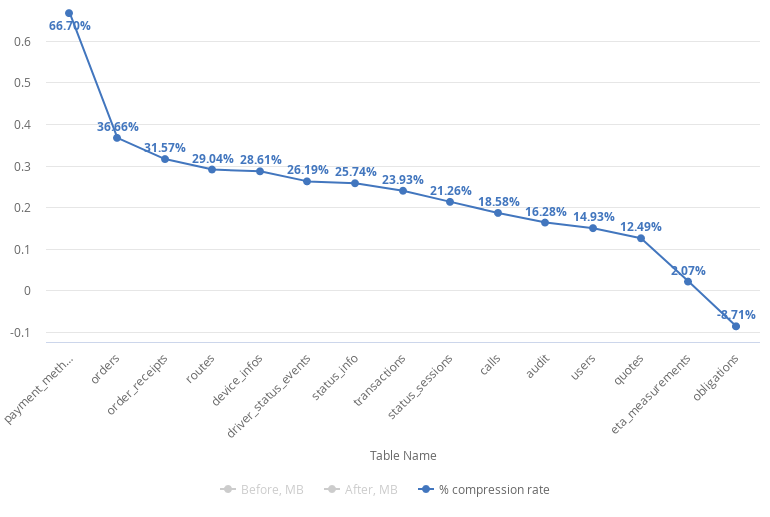
Несмотря на то, что у нас есть 1 таблица с отрицательным результатом (obligations), мы видим сокращение использования дискового пространства в среднем на 21,5 % . Прежде чем применять какие-либо изменения, обязательно оцените производительность запросов и составьте список таблиц, которые необходимо сжать. В моем случае я сжимаю все таблицы, кроме obligations.
Ключевые результаты
Тщательно оцените результат и производительность запросов. Основная цель по-прежнему заключается в том, чтобы сохранить скорость и производительность запросов при одновременном улучшении использования диска и ввода-вывода (I/O).
Рассмотрим алгоритм сжатия ZSTD. Согласно странице документа Redshift:
Кодирование Zstandard (ZSTD) обеспечивает высокую степень сжатия с очень хорошей производительностью для различных наборов данных. ZSTD особенно хорошо работает со столбцами CHAR и VARCHAR, в которых хранится широкий спектр длинных и коротких строк, таких как описания продуктов, комментарии пользователей, журналы и строки JSON. Там, где некоторые алгоритмы, такие как кодирование Delta или кодирование Mostly, потенциально могут использовать больше места для хранения, чем без сжатия, ZSTD вряд ли увеличит использование диска.
- Оберните его в макрос, который можно будет запускать автоматически на регулярной основе.
- Не стесняйтесь оставлять любые комментарии или вопросы.