

Как Яндекс предсказывает будущее: от исправления ошибок до discovery-запросов
Люди не всегда точно формулируют свои запросы, поэтому поисковые системы должны помогать им в этом. Давайте поговорим о том, как работает эта технология в Яндексе. Опишем архитектуру и применяемые алгоритмы. А ещё вы узнаете, чем предсказание следующего запроса отличается от предсказания будущих интересов человека.
Что хочет пользователь?
Рассмотрим, как технологии Яндекса помогают в решении задач, на примере воображаемого пользователя. Допустим, он печатает в поисковой строке «копить билет». Что он хочет найти? Узнать про накопление билетов или всё же просто ошибся?

Да, он опечатался. Он хочет не копить, а купить билет. Яндекс его понял, в этом ему помог опечаточник — система, которая исправляет некорректно введённые запросы. Математически эта система максимизирует вероятность корректно введённого запроса при условии введённого текста пользователем. Эта задача уже больше десяти лет решается в Яндексе. И не только в поиске.
Итак, наш воображаемый пользователь ввёл запрос «купить билет». На этом этапе в игру вступает саджест (или поисковые подсказки). Саджест помогает пользователю доформулировать запрос, правильно его завершить.
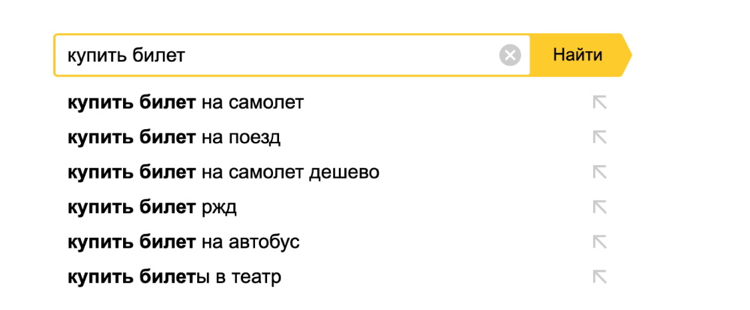
Саджест в Яндексе прошёл большой путь. Пару лет назад мы усложнили задачу. Хотелось показывать не просто самое логичное завершение запроса, но и предсказывать, какой запрос в итоге введёт именно этот пользователь, и начать его пререндер ещё до клика.
Наш воображаемый пользователь выбирает окончание запроса из ряда подсказок: оказывается, что он искал билеты в Третьяковскую галерею. Таким образом, система рекомендаций выполнила первую свою задачу — помогла пользователю сформулировать запрос.
Эта задача выполнена, но у пользователя ещё остались вопросы. Что он будет искать дальше? Может быть, он хочет узнать, как ему добраться в галерею? Да, он печатает «Лаврушинский пер, 10», чтобы проверить адрес.
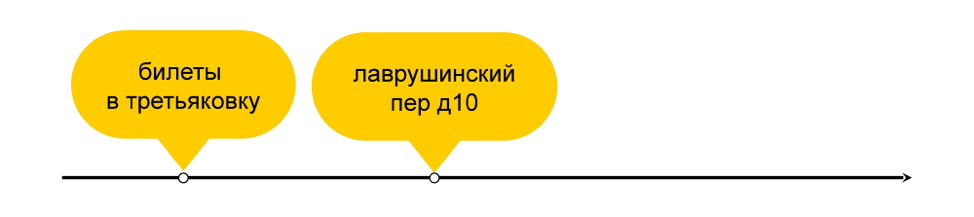
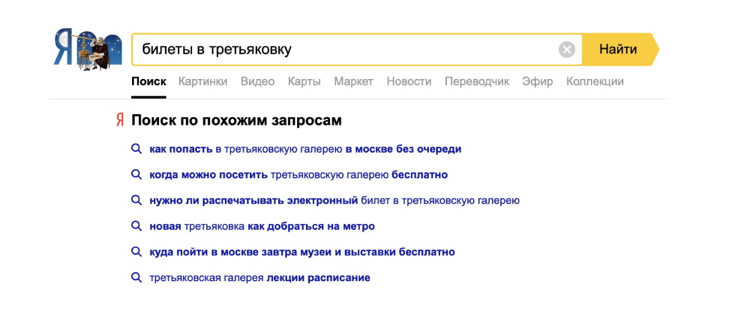
Можем ли мы предугадать этот запрос? Да. И мы это делаем довольно давно. Есть такой блок — «Также спрашивают» в конце выдачи. В нём показываются запросы, которые люди обычно задают после введённого в поле поиска. Именно в нём мы увидим наш запрос с адресом Третьяковской галереи.

Мы максимизируем вероятность запроса при условии предыдущего запроса пользователя. Система выполнила вторую задачу — предсказала следующий запрос.
А вот дальше происходит кое-что очень интересное. Пользователь печатает запрос «когда можно посетить Третьяковскую галерею бесплатно». Этот запрос отличается от остальных, идёт вразрез с пользовательской задачей, решает некоторую ортогональную задачу.
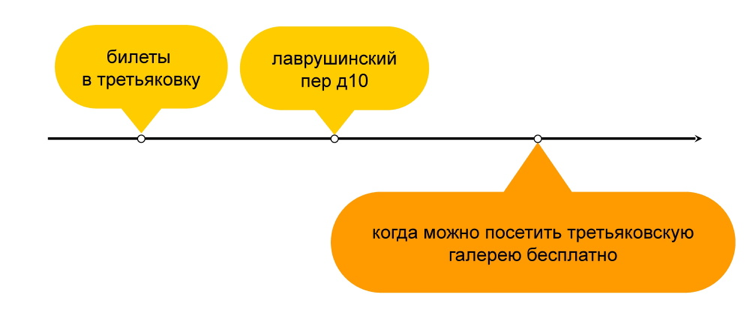
Но давайте подумаем: если бы мы искали билеты в галерею, что бы мы сами хотели увидеть в качестве рекомендации? Огромное количество людей хотели бы узнать, что билет, может быть, и не нужно покупать. Это третья, самая сложная и интересная часть задачи — порекомендовать пользователю что-то новое и полезное. Что-то, о чём он сам ещё не подумал.
Такие запросы мы называем discovery. Мы учимся их определять в наших поисковых логах, сохранять и рекомендовать в конце выдачи. И это как раз та новая и революционная задача, которой мы активно сейчас занимаемся. Человеку, покупающему скандинавские палки, Яндекс может порекомендовать запрос о том, как подобрать их по росту. Если человек часто путешествует, то, возможно, ему будет интересен поисковый запрос «куда поехать без визы». И так далее.
Математическая постановка задачи в этом случае будет выглядеть следующим образом: мы максимизируем не вероятность следующего запроса, а вероятность клика по запросу, который мы рекомендуем пользователю на основе его предыдущей сессии.
Как это работает?
Давайте посмотрим на то, как реализована наша система рекомендаций, какая архитектура за этим спрятана. Но для начала определимся, что мы вообще хотим получить от рекомендательной системы.
- Полезные рекомендации! Конечно, мы хотим, чтобы те запросы, которые мы рекомендуем пользователю, соответствовали его интересам. Они должны быть полезными и релевантными.
- Масштабируемость. Мы надеемся, что система будет хорошей: пользователей будет всё больше и больше, а количество запросов будет увеличиваться. И мы хотим увеличивать покрытие тем, по которым мы можем делать рекомендации.
- Простота реализации. Мы предполагаем, что наша система всё-таки будет работать, и мы не хотим её много раз переписывать. Система должна быть проста в реализации, чтобы мы потом могли её улучшать, не запуская новую версию, а улучшая текущую.
Определившись с нашими пожеланиями, давайте посмотрим, как можно воплотить их в жизнь.
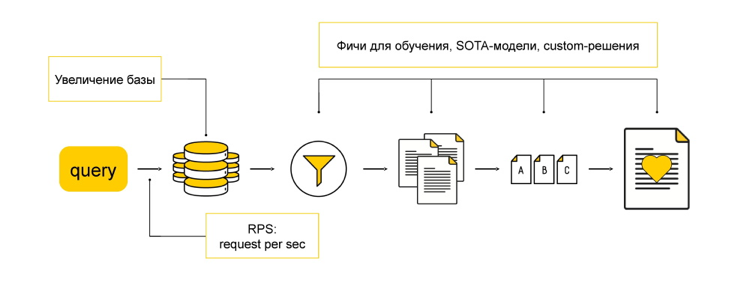
У нас есть некоторая discovery-база — база запросов, которые могут показаться интересными и полезными нашим пользователям. Но если мы начнем ранжировать всю эту базу, нам не хватит вычислительных мощностей. У пользователей много запросов, они разноплановые, поэтому сначала нам нужно эту базу отфильтровать.
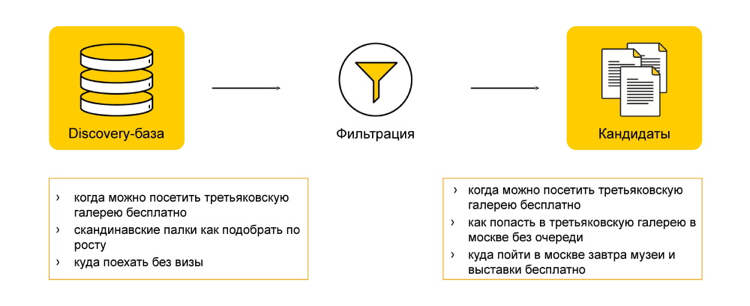
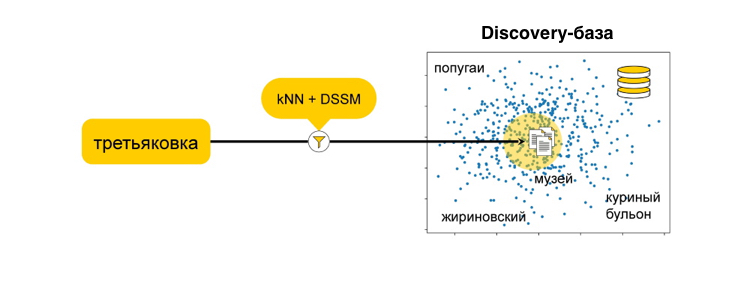
Фильтрацию можно осуществлять разными методами. В Яндексе мы используем для этого kNN (k-nearest neighbors) — базовый алгоритм классификации в машинном обучении, известный как «поиск ближайших соседей». С помощью этого алгоритма мы хотим отфильтровать базу: выбрать максимально близкие запросы к тому, что может заинтересовать пользователя. Для этого мы хотим в векторном пространстве сравнить запрос пользователя и те запросы, которые мы готовы порекомендовать.
Но чтобы привести эти запросы в одно векторное пространство, нам тоже нужно что-то придумать. Например, можно использовать DSSM (Deep Structured Semantic Model) — этакий чёрный ящик, который умеет разные сущности переводить в одно векторное пространство. Изначально этот подход был предложен в статье от Microsoft. Но Яндекс его уже достаточно сильно адаптировал под свои задачи и далеко ушёл от оригинальной идеи.
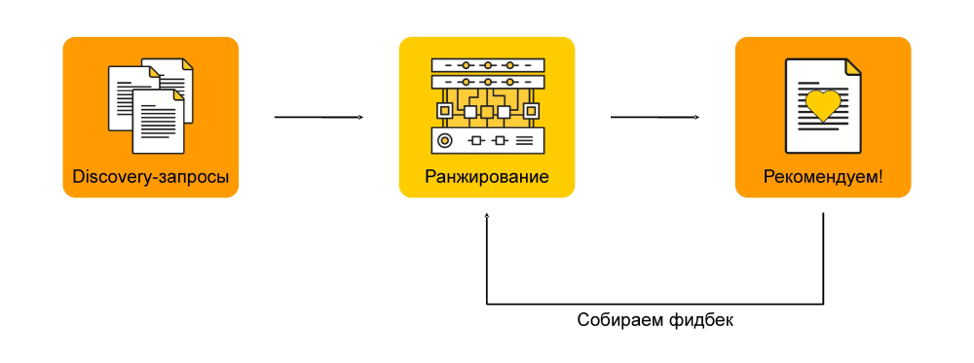
Следующий этап — это ранжирование. Когда у нас есть список запросов, близких к тому, что, возможно, заинтересует пользователя, мы хотим понять, что ему будет более интересно, а что менее.
Например, мы выбрали 100 запросов. Вряд ли пользователь будет скроллить все 100. Нужно выбрать топ-5 и порекомендовать. Чтобы это сделать, мы присваиваем нашим запросам оценки. Эти оценки мы получаем, исходя из вероятности клика по запросу, который мы рекомендуем пользователю на основе его предыдущей сессии.
Как же мы получаем вероятность следующего клика? Наша система уже запущена и работает, поэтому мы просто собираем фидбек от пользователей — и тем самым постепенно улучшаем нашу рекомендательную систему.
Теперь, когда мы рассмотрели все этапы отдельно, давайте вернёмся к началу и соберём всё вместе. Итого: пользователь приходит к нам с некоторым запросом, а у нас есть какая-то база рекомендаций. Мы берём эту базу и фильтруем, получая запросы, которые мы хотим отранжировать и порекомендовать пользователю.
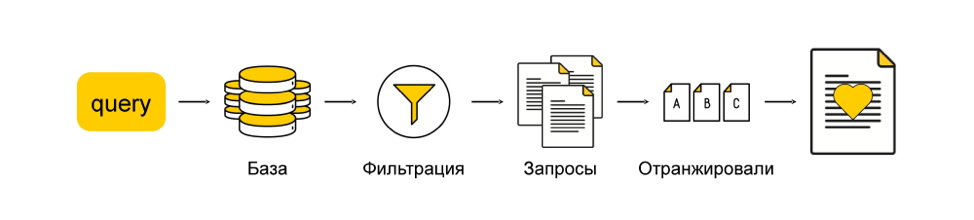
Теперь вспомним о том, что мы вообще формулировали пожелания к нашей рекомендательной системе. И посмотрим, как мы можем их реализовать в полученной архитектуре.
Например, мы хотели масштабируемость в терминах улучшения базы. У нашего способа реализации есть все необходимые для такого масштабирования свойства. Мы не должны держать всю базу в памяти: как только база расширится настолько, что она не будет помещаться на один кластер, мы можем разбить её на два. И если раньше по одному кластеру мы проходили с kNN и выбирали топ-100, которые будем ранжировать, сейчас мы можем пройтись по двум кластерам отдельно и выбрать в каждом, например, топ-50. Или, вообще, разбить кластеры по тематикам и проходиться с kNN только по нужной тематике.
Чтобы масштабировать количество пользователей, можно просто добавить дополнительных вычислительных мощностей и каждого обрабатывать отдельно, потому что в нашей архитектуре нет мест, где нам пришлось бы держать всех юзеров в памяти одновременно.
В некоторых других подходах такие места есть, которые фильтруют, например, при разложении матрицы. Разложение матрицы — это другой подход, который используется в рекомендациях. На самом деле, Яндекс его тоже использует, но при этом не для фильтрации, а в качестве дополнительных фичей для обучения, потому что там всё ещё много информации, которую полезно анализировать.
Дополнительные фичи, новые алгоритмы и другие методы можно применять в остальной части архитектуры. Когда система запущена и работает, мы можем начинать это улучшать.
Где это работает?
Такая архитектура уже внедрена в Яндексе, и в сравнении с обычными переформулировками, когда мы пытались пользователю посоветовать узнать адрес Третьяковской галереи, мы уже можем советовать, как попасть в Третьяковку без очереди или вообще бесплатно.
Это новый уровень взаимодействия поисковой системы с пользователями. Мы не просто исправляем ошибки и дополняем запросы, а учимся предсказывать интересы человека и предлагать ему что-то новое. Возможно, именно таким будет поиск будущего. А что думаете вы?
Статья написана совместно с Сергеем Юдиным, руководителем группы аналитики функциональности поиска в Яндексе.